







动手实践篇2:文档场景信息抽取(PP-ChatOCRv2_doc)模型训练
Lesson 2 模型训练
第一步:选择产线
- 界面位置: [选择产线] -> [文档图像信息抽取]
- 操作方式:选择完成后点击下一步
- 预置模型:系统内置了版面分析、文本检测、文本识别、表格识别等基础模型。
| 模型类别 | 模型名称 |
|---|---|
| 版面分析 | PicoDet_layout_1x |
| 文本检测 | PP-OCRv4_server_det / PP-OCRv4_mobile_det |
| 文本识别 | PP-OCRv4_server_rec / PP-OCRv4_mobile_rec |
| 表格识别 | SLANet |
第二步:数据准备
- 界面位置: [选择模型] -> [添加数据集] -> [未校验数据集] -> [数据校验]
- 操作方式:配置完成后点击下一步
-
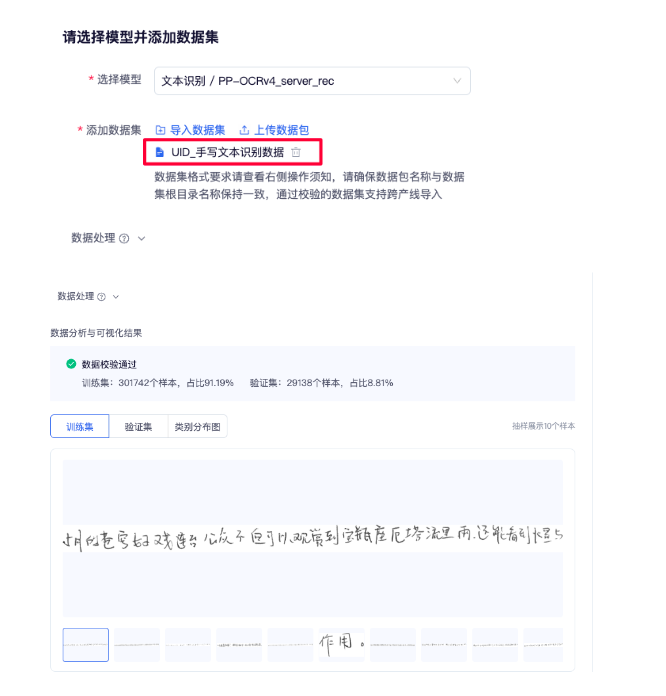
选择模型:先选择 [文本识别/PP-OCRv4_server_rec],来微调手写文本识别服务器端模型。之后选择 [文本识别/PP-OCRv4_mobile_rec] ,来微调手写文本识别移动端模型。
-
添加数据集:通过添加数据集的方式,将准备好的训练数据导入系统。完成一次训练后,相关数据将自动保存至您的个人数据集中,无需重复上传。其中, [已校验数据集] 已经达到 PaddleX 的数据校验成功的数据集,可以直接使用; [未校验数据集] 是您程序中导入的未校验数据,未必满足 PaddleX 要求的格式,需要处理并校验成功后方可使用。这里我们点击 [已校验数据集] ,选择内置的样例数据 [中文手写数据集]。
-
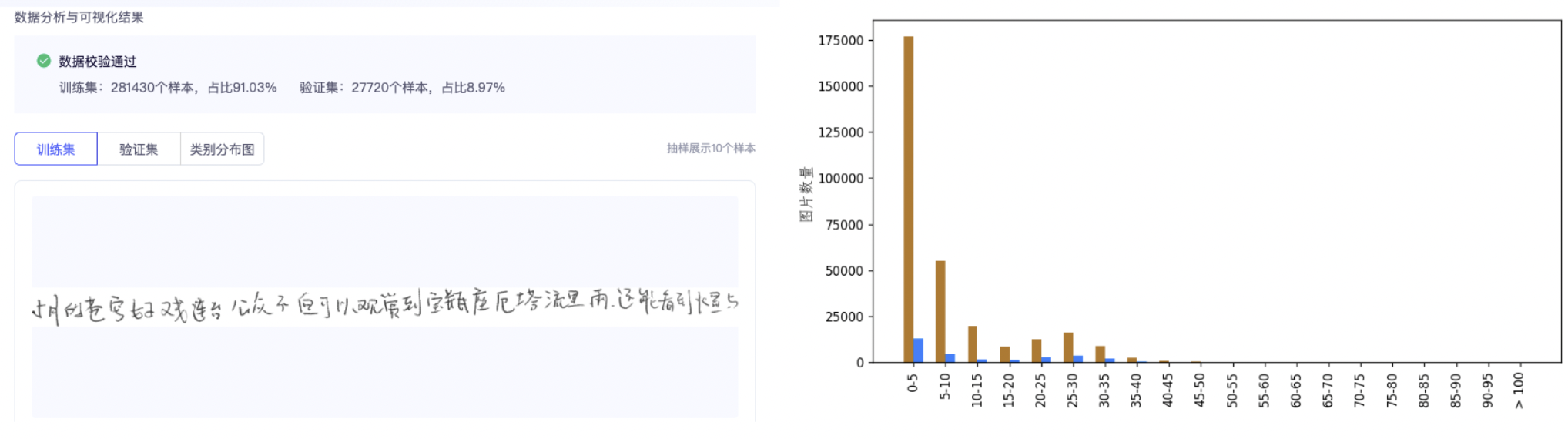
数据校验:预先检查添加数据集的标注和内容,确保数据是否满足后续训练要求。此外,能够看到每个数据的标注样式,并获取整个数据集样本的长度分布情况统计,帮助您更好地了解数据的分布和特性。
💡 实践经验:
经过数据校验,可以观察到当前手写文字数据集中,大部分训练数据包含 5-10 个文字,同时,含有 20 个字以上的长文本样本也占据了较大的比例。这一数据特点提示我们在模型训练时,需要特别关注长文本的处理问题,确保模型能够准确识别并处理这些较长的手写文字序列。
例如,文本识别中,默认可处理的最长文本数为 25,如发现训练数据中超过 25 的数据过多时,需要在参数准备中,选择 [修改配置文件],将 max_text_length 放大至 50。
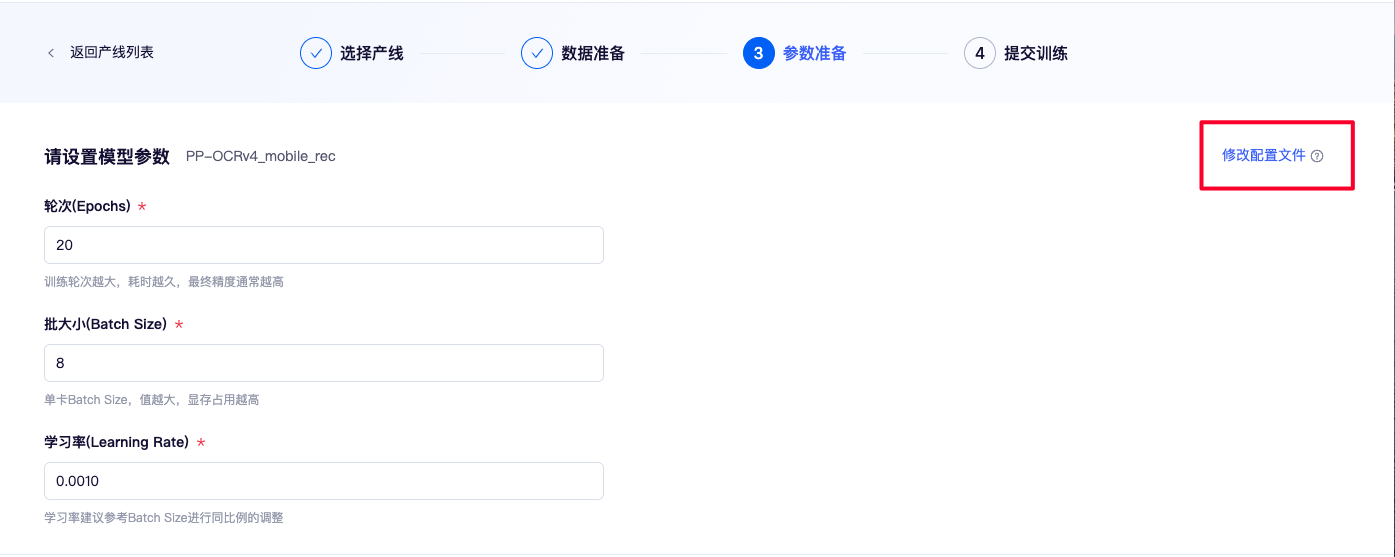
✅ 第三步:参数准备
📍 界面位置:【设置参数】
🖱️ 操作方式:填写完成后点击下一步
参数准备阶段有以下三个部分支持自定义配置:
基础配置:
重点关注训练轮次、批大小、学习率这三个核心参数的调整。
- 训练轮数:决定了模型对数据的重复学习次数;训练轮次越大,耗时越久,最终精度通常越高。
- 批大小:每一次训练迭代中使用的样本数量;单卡 Batch Size,值越大,显存占用越高。
- 学习率:影响着模型参数更新的步长;学习率建议参考 Batch Size 进行同比例的调整。
高级配置:
预训练模型路径已默认设置为官方权重,使用这些权重可以加速模型的收敛过程,并有助于提升模型的精度。
当然,如果您有自己训练的模型权重,也可以随时替换官方权重进行使用。
若训练过程中发生意外中断也无需担心,可以加载断点训练权重,从而无缝继续之前的训练进程。
进阶使用:
除了通过表单来修改常用参数外,对于追求更高灵活性的高阶用户,我们还提供了点击“修改配置文件”的选项,允许您进行更细致的参数设置,包括但不限于学习率衰减、正则化系数调整以及数据增广等个性化配置。
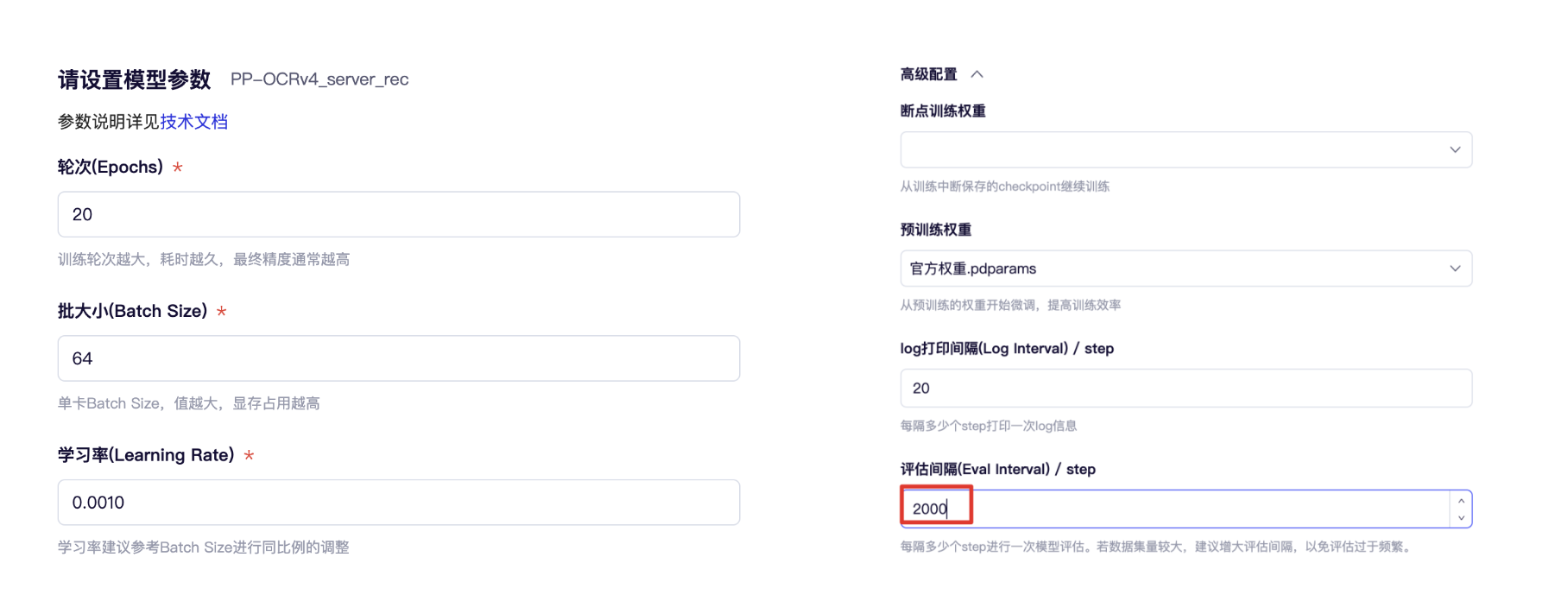
本节实战任务是跑通 baseline,下节将详细介绍模型评估和调参策略。可以参考如下截图修改配置文件:
- 训练轮次为 20
- 批大小为 64
- 卡数选择 4 卡
- 学习率为 0.001
- 并在高级设置里将评估间隔修改为 2000
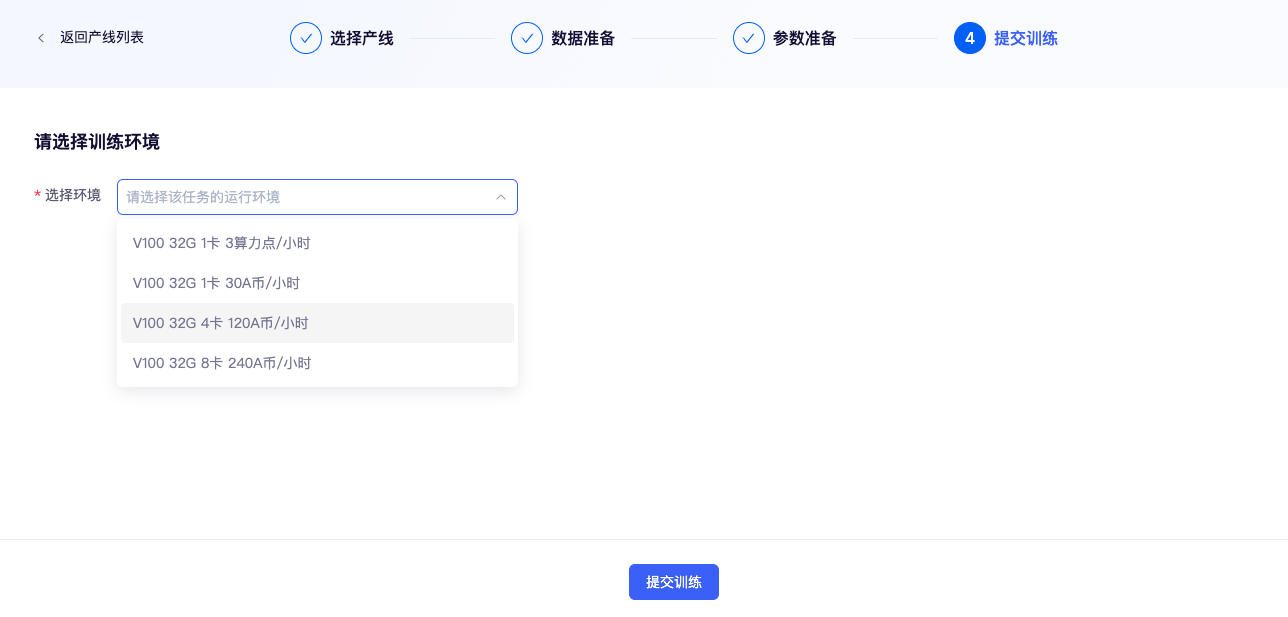
✅ 第四步:提交训练
📍 界面位置:【选择训练环境】 -> 【提交训练】
🖱️ 操作方式:点选后提交训练
选择环境:
在选择训练环境时,请确保训练卡数乘以单卡 batch_size 等于总 batch_size。同时,学习率应与总 batch_size 保持同步调整。当前的学习率设置是基于 4 卡训练的,若您打算在单卡环境下进行训练,则学习率需相应除以 4。
日志查看:
完成环境选择后,点击提交训练可以看到实时日志打印。等待模型训练完毕后可以在右上角进行评估和部署。
1.不同于教程中直接选择内置数据集,希望大家可以体验自行上传准备数据的流程。因此请尝试下载训练数据,上传至产线完成数据校验,并在校验成功页面截图。
2.按照参数准备截图中的配置(训练轮次为 20,批大小为 64, 卡数选择 4 卡,学习率为 0.001)修改配置文件参数完成 PP-OCRv4_server_det 模型训练,并截图。

PP -ChatOCRv2_doc模型训练和部署过程从选择文档图像提取管道开始。进入【选择产线】->【文档图像信息抽取】,预装了布局分析、文本检测、识别、表格识别等模型,如PicoDet_layout_1x、PP-OCRv4_server_det、PP-OCRv4_mobile_det、PP-OCRv4_server_rec、PP-OCRv4_mobile_rec和SLANet可用。接下来,在数据准备阶段,您可以使用预装的数据集或通过[选择模型] -> [添加数据集] -> [未校]上传并验证自己的数据来微调手写文本识别模型验货数据集] -> [数据校验]。如果你的数据集包含长文本,则必须将max_text_length参数调整为 50。之后,转到[设置参数]下的参数配置,在其中设置基本参数,例如 epochs(20)、batch size(64)、GPU 卡(4 )、学习率(0.001)。高级用户可以自定义学习率衰减、数据增强等更详细的配置。参数准备好后,您可以通过[选择训练环境] -> [提交训练]提交训练],确保根据使用的 GPU 数量正确调整批处理大小和学习率。在训练期间,您可以监控实时日志,并在完成后评估和部署模型。作为一项额外任务,而不是使用预先安装的数据集,鼓励您上传和验证自己的数据,然后完成PP-OCRv4_server_det模型训练并捕获结果的屏幕截图。此过程提供了训练、配置和部署 PP-ChatOCRv2_doc 模型的实践经验,同时探索数据集准备和参数调整策略。
















 1923
1923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











