






一、ARIMA回归模型
ARIMA回归模型是一种用于时间序列数据预测的统计模型。
ARIMA 是 AutoRegressive Integrated Moving Average 的缩写,中文意思是“自回归差分移动平均模型”。它是一种结合了自回归(AR)、差分(I)和移动平均(MA)三种方法的模型。
自回归(AR):指的是模型会考虑过去的值对当前值的影响。
差分(I):指的是对数据进行处理,使其平稳,即消除数据中的趋势和季节性。
移动平均(MA):指的是模型会考虑过去的误差对当前值的影响。
算法步骤
Step1:读取数据
Step2:数据预处理
Step3: 确定模型参数
Step4: 训练模型
Step5: 检验模型
ARIMA模型的优点:
预测能力:可以预测未来的趋势,帮助做出决策(短期较为准确,长期预测误差较大)。
理解数据:通过分析历史数据,可以更好地理解数据的模式和结构。
提高效率:在某些情况下,可以减少不必要的资源浪费。
二、数据的来源
本文的数据来源于某股市的交易数据,其中包含字段分别为交易日期、开盘价、最高价、最低价、收盘价、昨日收盘价、成交量、成交金额、振幅、涨跌幅、涨跌额、换手率。

三、程序部分
Step1:读取数据
%matplotlib inline
import pandas as pd #数据处理,数据分析
import datetime #导入日期和时间
import matplotlib.pylab as plt #可视化展示
from matplotlib.pylab import style #画图风格
from statsmodels.tsa.arima_model import ARIMA #差分自回归移动平均模型
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf #ACF图,PACF图
#去掉不必要的警告
import warnings
warnings.filterwarnings("ignore")
stock = pd.read_csv('sh_******.csv', index_col=0, parse_dates=[0],encoding='utf-8') #把日期作为索引列
stock前5行数据:
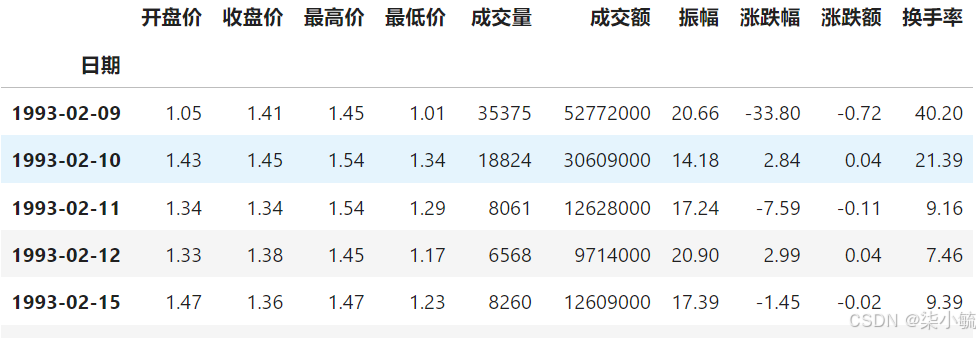
Step2:数据预处理
2.1数据重采样
#对“收盘价”列进行数据重新采样(时间序列的频率从每天变成每周一),然后取每周的平均值
stock_week = stock['收盘价'].resample('W-MON').mean()
stock_week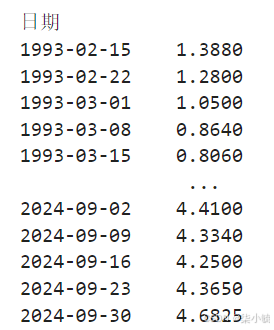
stock_train = stock_week['2017':'2022']
#选择2017年到2022年的数据作为训练集数据2.2画图展示股票收盘价
from matplotlib.font_manager import FontProperties #设置绘图时的中文字体
myfont=FontProperties(fname=r'C:\Windows\Fonts\simhei.ttf'# 设置中文
plt.figure(figsize=(12,8),dpi=600) #设置图形和清晰度的大小
stock_train.plot() #画图
plt.title('股票收盘价',fontproperties=myfont) #设置标题
plt.xlabel('时间',fontproperties=myfont) #设置X轴标签
plt.ylabel('股票收盘价',fontproperties=myfont) #设置y轴标签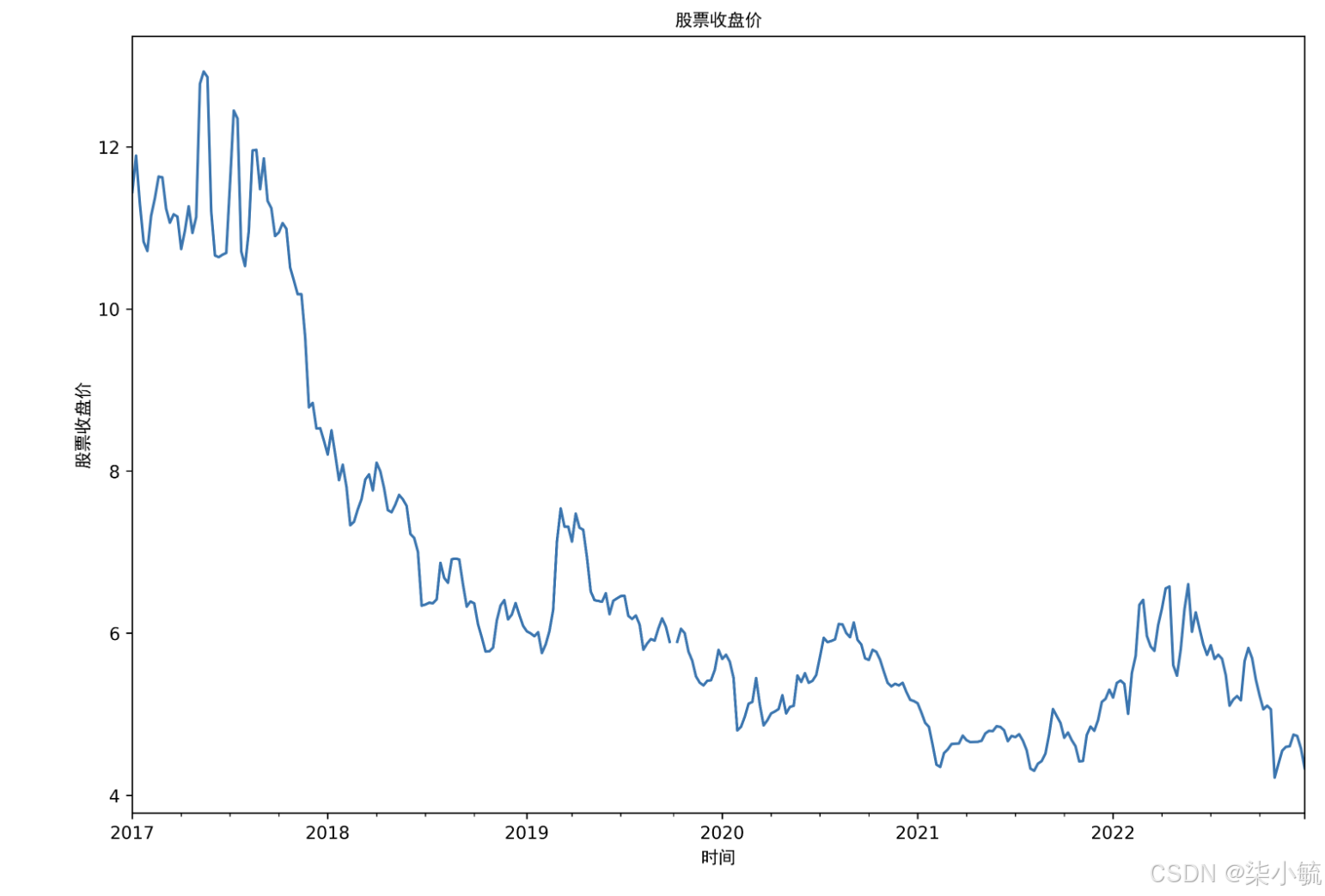
#显著性水平在0.05以下表示时间序列平稳
from statsmodels.tsa.stattools import adfuller
dftest = adfuller(stock_train)
dftest[1]Step3:确定模型参数
stock_diff_1 = stock_train.diff() #df.diff()一阶差分
stock_diff_1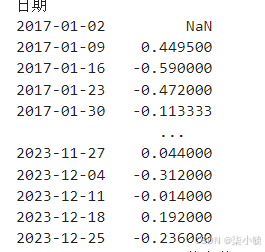
stock_diff = stock_diff_1.dropna()#dropna()滤除缺失数据
stock_diff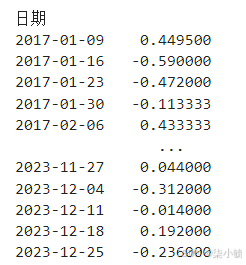
plt.figure(dpi=600)
plt.plot(stock_diff)
plt.show()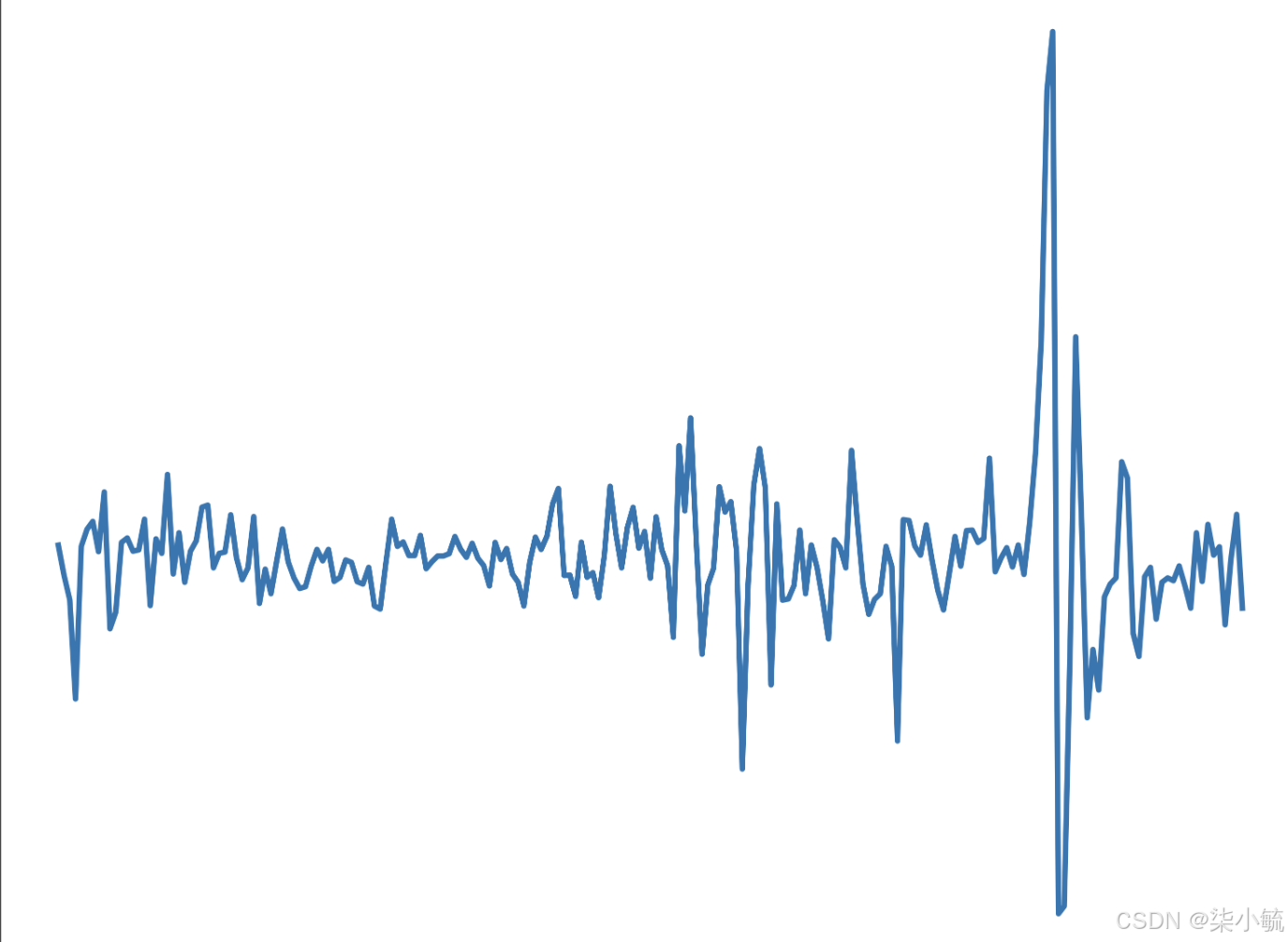
#再次adf检验
from statsmodels.tsa.stattools import adfuller #再次adf检验
dftest = adfuller(stock_diff)
dftest[1]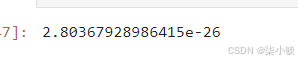
#绘制acf图
plt.figure(dpi=600)
acf = plot_acf(stock_diff, lags=20)
plt.title("ACF")
plt.xlabel("阶数",fontproperties=myfont)
plt.ylabel("自相关系数",fontproperties=myfont)
acf.show()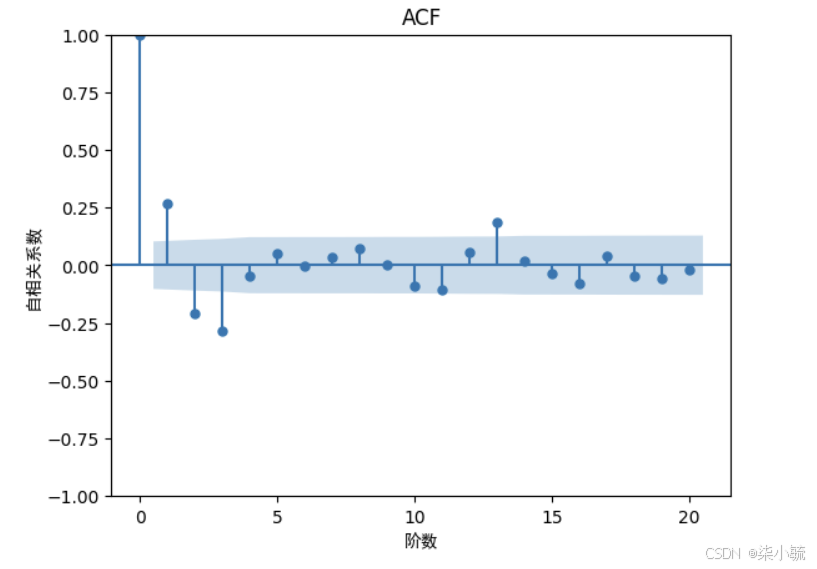
#绘制PACF图
plt.figure(dpi=600)
pacf = plot_pacf(stock_diff, lags=20)
plt.title("PACF")
plt.xlabel("阶数",fontproperties=myfont)
plt.ylabel("偏自相关系数",fontproperties=myfont)
pacf.show()#展示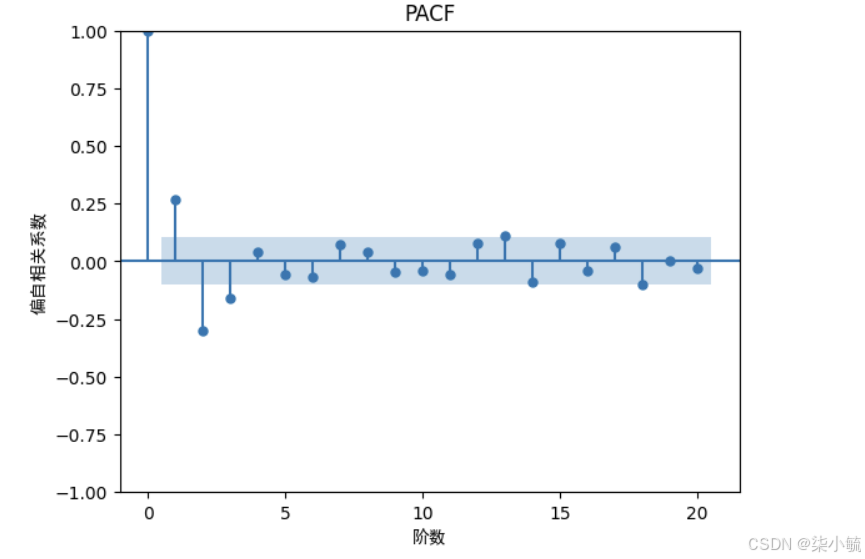
#通过AIC准则确定p,q
import statsmodels.api as sm
res = sm.tsa.arma_order_select_ic(stock_diff,max_ar = 5,max_ma = 5,ic = ['aic'])
res.aic_min_orderStep4: 训练模型
forcast_steps=50 # 请注意:步长超过30后,运行时间会超过 1 分钟。步长超过50后,运行时间会超过 3 分钟
model = sm.tsa.ARIMA(stock_train, order = (forcast_steps,1,forcast_steps),freq='W-MON')
model = model.fit()pred_1 = model.forecast(steps=forcast_steps)
pred_1[-10:]forcast_end_day = str(pred_1.index[-1].year)+'-'+str(pred_1.index[-1].month)+'-'+str(pred_1.index[-1].day+1)
forcast_end_daystock_val = stock_week['2000-1-1':forcast_end_day]
stock_valplt.figure(dpi=600)
plt.plot(stock_val)
plt.plot(pred_1) 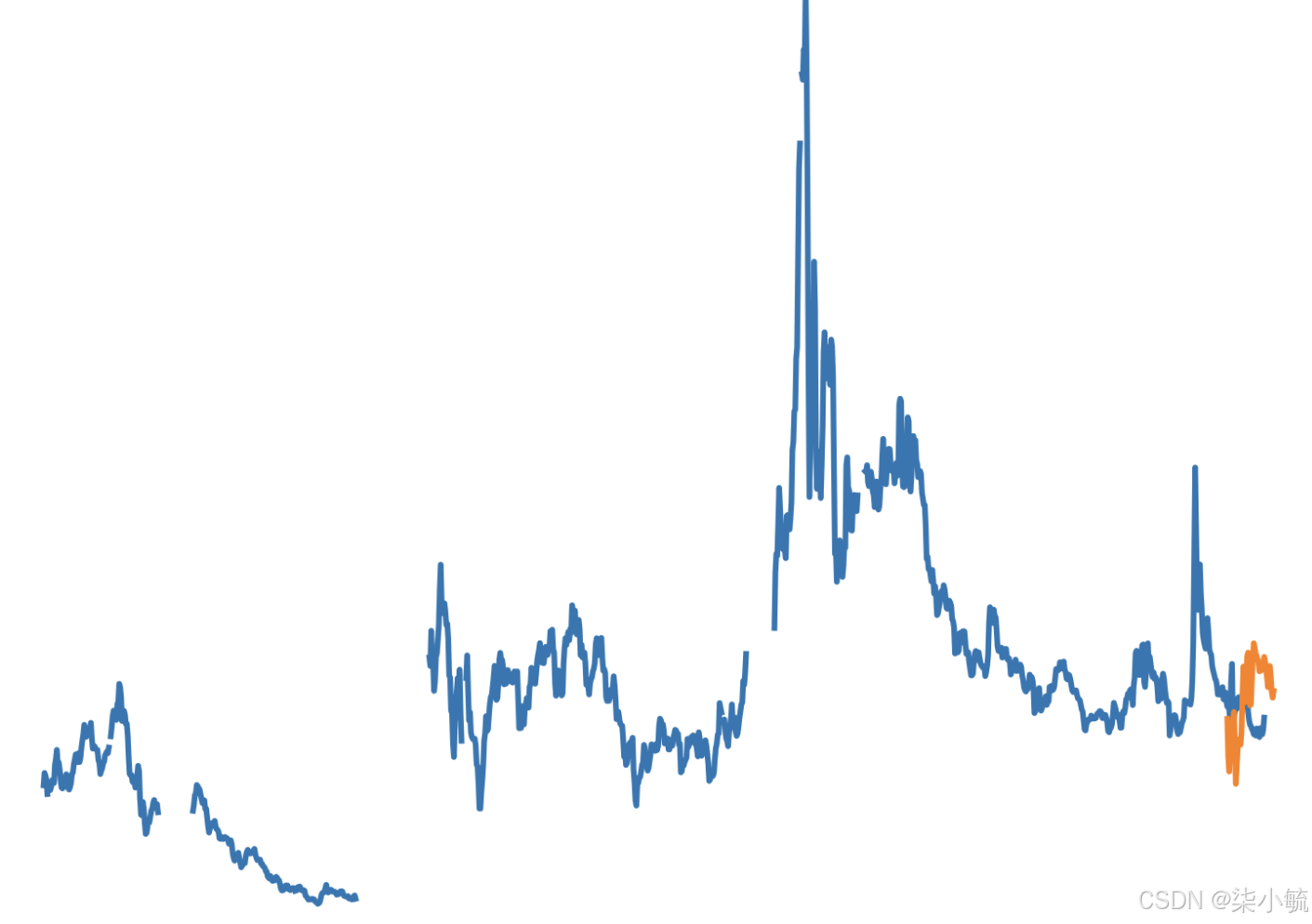
stock_train2 = stock_week
forcast_steps=50 # 请注意:步长超过30后,运行时间会超过 1 分钟。步长超过50后,运行时间会超过 3 分钟
model2 = sm.tsa.ARIMA(stock_train2, order = (forcast_steps,1,forcast_steps),freq='W-MON')
model2 = model2.fit()pred_2 = model2.forecast(steps=forcast_steps)
pred_2[-10:]plt.figure(dpi=600)
plt.plot(stock_train2)
plt.plot(pred_2)
Step5: 检验模型
stock_actual = stock_week['20140609':'20160627']
print(stock_actual)print(pred_1)error_1=pow(stock_actual-pred_1,2)
MSE1=error_1.sum()/len(pred_1)
print(MSE1)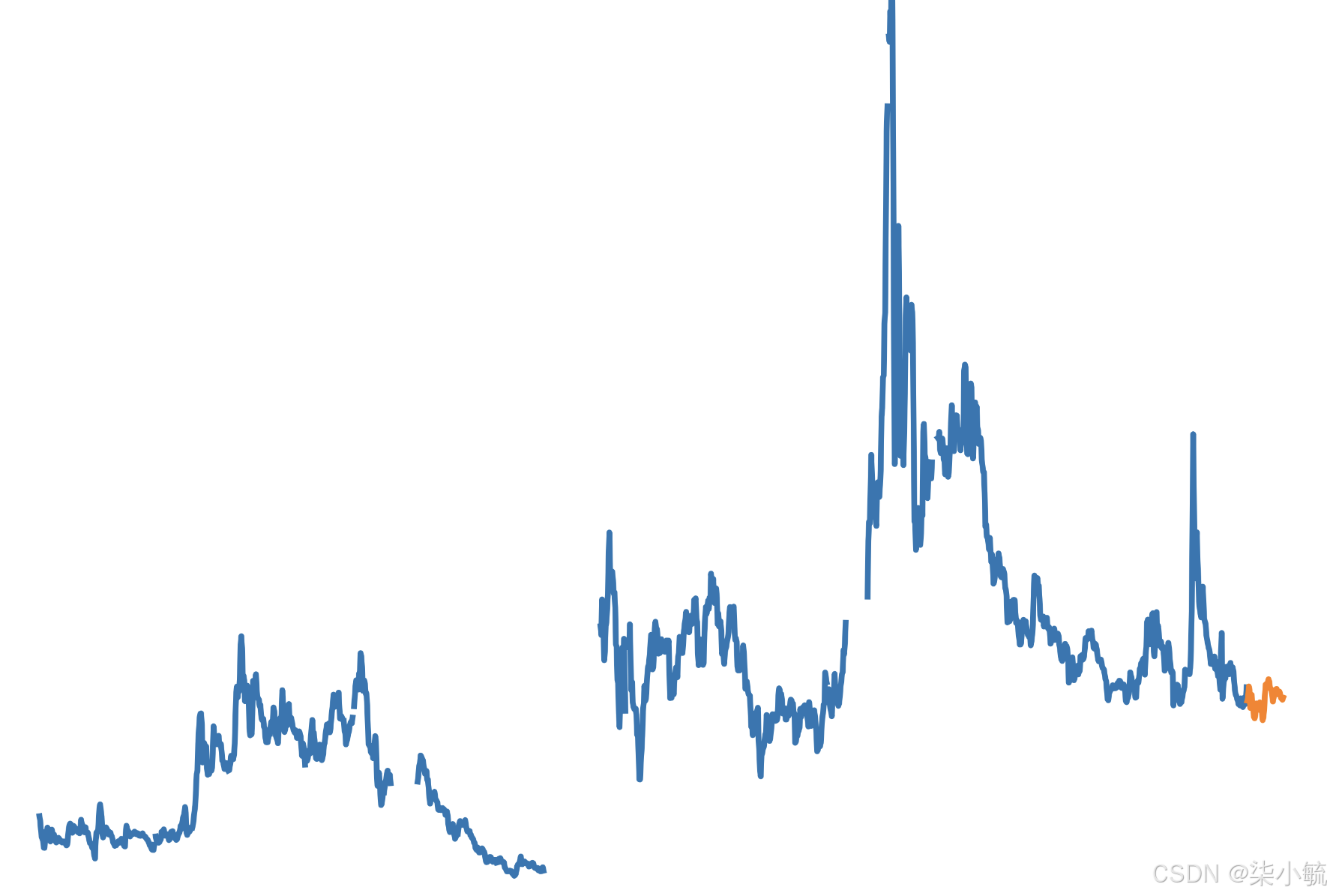
print(pred_2)error_2=pow(stock_actual-pred_2,2)
MSE2=error_2.sum()/len(pred_2)
print(MSE2)
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









