







需要学习前期准备:
1.在线体验模型方案 实践1应用部署链接
2.在线体验模型方案 实践2模型训练链接
lesson 3 模型评估与调优
📍界面位置:
【模型产线】 -> 【选择产线】 -> 【产线评估】
🛠 操作方式:
配置完成后点击开始评估
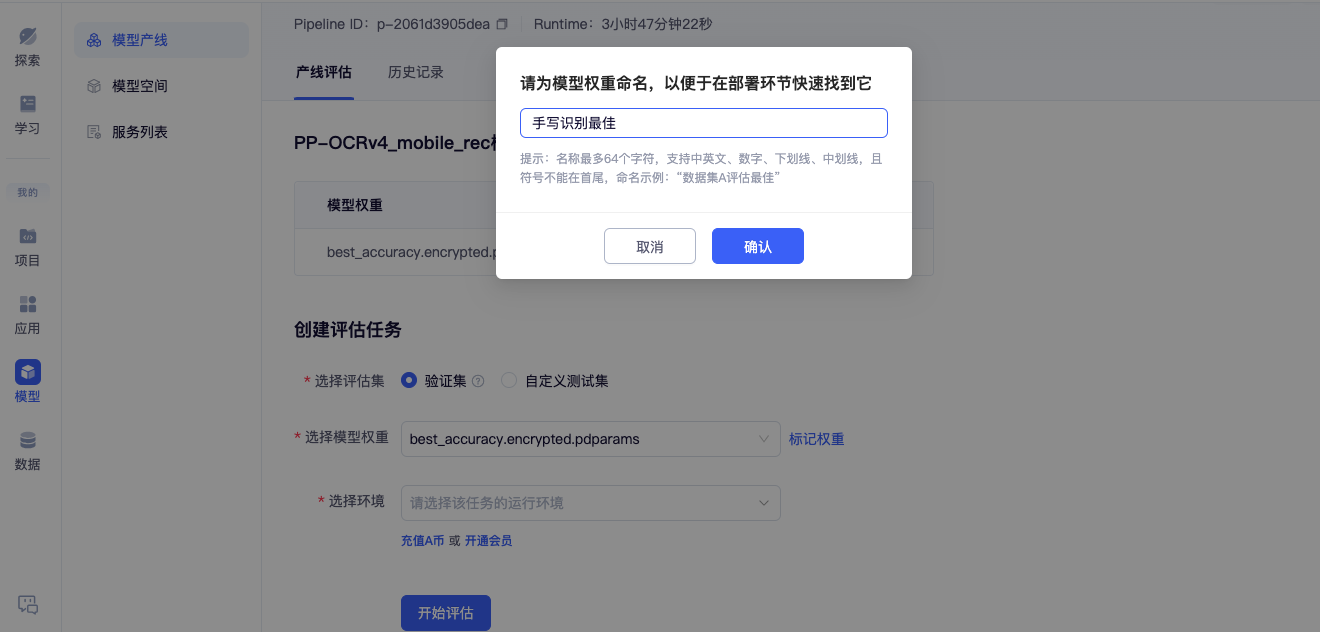
标记模型权重(必选):
在评估阶段保存标记训练过程中的权重最佳的权重,用于后续部署。
评估流程:
在实际训练完成后,您可以沿着【模型产线】->【选择产线】->【产线评估】的流程,来查看训练过程中的评估结果。
此时可以基于 baseline 调整参数继续训练以获得高精度的模型,也可以直接标记当前模型权重。

创建评估任务(可选):
如有额外的评估数据,可以在此评估其他数据集精度。
知识补充
在模型评估阶段,可以检测训练过程中保存下来的模型权重以及验证集分数。PaddleX 允许训练和评估交替进行,通过设定参数中的“评估间隔 (Eval Interval)” 来控制评估的频率。默认情况下每过 100 个迭代 (iter) 就会进行一次评估。值得注意的是,评估间隔设置得越长,所需的时间通常越长,但这也能够更高效地监测模型性能,减少错过最佳模型权重的风险。
验证集分数则是指模型在验证集上的字符识别准确率 (ACC),具体表现为正确识别的文本行占标记文本行总数的比例。仅当整个文本行完全正确识别时,才计入正确识别的范畴。通常,我们会标记验证集上表现最佳、精度最高的模型权重作为最终部署的模型权重。
模型调优
在教程第 2.4 节中,我们详细介绍了参数的概念和调整参数的方法。在模型训练的参数中,学习率 (Learning Rate) 和轮次 (Epochs) 尤为关键。
通过合理调整训练参数,您可以控制模型的训练深度,避免出现欠拟合或过拟合;而学习率的设置则关系到模型收敛的速度和稳定性。因此,在优化模型性能时,务必慎重考虑这两个参数的数值,并根据实际情况进行灵活调整,以获得最佳的训练效果。推荐在调试参数时遵循的控制变量法:
- 首先固定训练轮次为 20,批大小为 64。
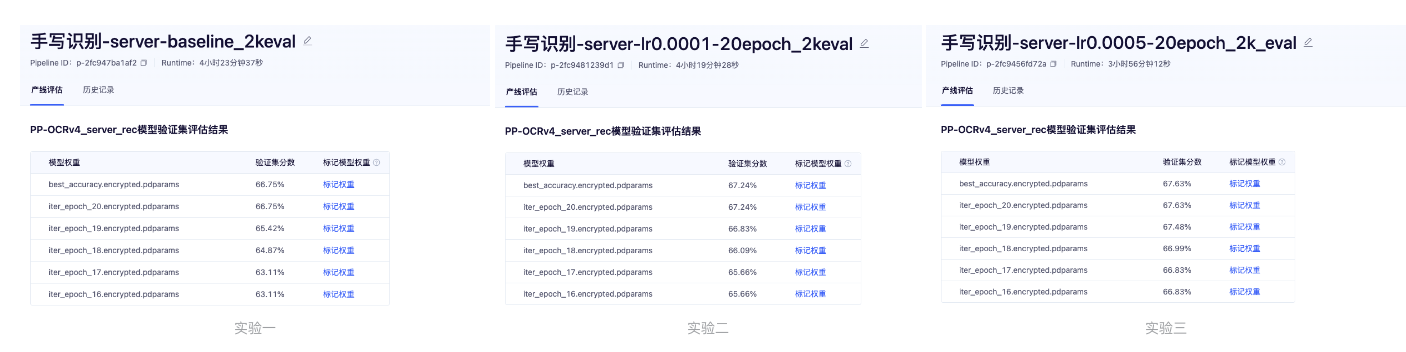
- 基于 PP-OCRv4 server rec 模型做三个实验,学习率分别为:0.001, 0.0005, 0.0001。
- 可以发现第 3 个精度最高的配置当学习率为 0.0005,同时观察验证集分数,精度在最后几轮仅有上升。因此可以提升训练轮次为 100,模型精度会有进一步的提升。
学习率探索实验结果:
| 实验 | 轮次 | 学习率 | batch_size | 评估间隔 | 训练环境 | ACC |
|---|---|---|---|---|---|---|
| 实验一 | 20 | 0.001 | 64 | 2000 | 4卡 | 66.75% |
| 实验二 | 20 | 0.0005 | 64 | 2000 | 4卡 | 67.64% |
| 实验三 | 20 | 0.0001 | 64 | 2000 | 4卡 | 67.23% |
增大 epoch 实验结果:
| 实验 | 轮次 | 学习率 | batch_size | 评估间隔 | 训练环境 | ACC |
|---|---|---|---|---|---|---|
| 实验二 | 20 | 0.0005 | 64 | 2000 | 4卡 | 67.64% |
| 实验二增大训练轮次 | 100 | 0.0005 | 64 | 2000 | 4卡 | 69.71% |
学习
- 完成 3 组 PP-OCRv4 server_rec 学习率探索实验,并参照上文记录实验结果,提交实验结果与最佳精度训练结果截图,例如:
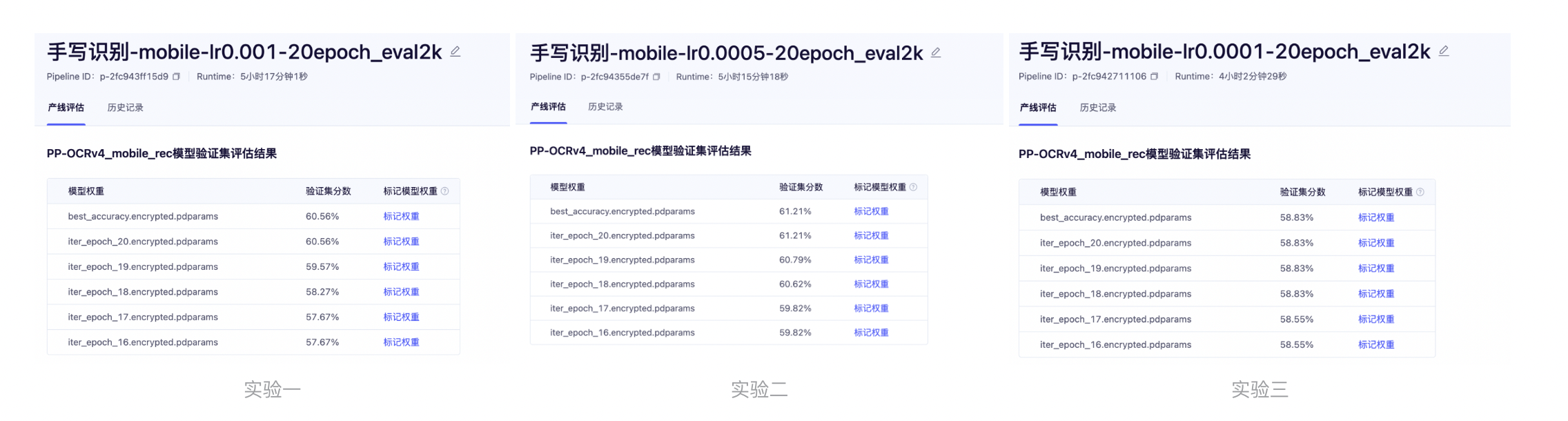
2.完成3组 PP-OCRv4_mobile_rec 学习率探寻实验,并参照上文记录实验结果,提交实验结果与最佳精度训练结果截图。
实践1应用部署文档场景信息抽取(PP-ChatOCRv2_doc)
















 1187
1187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











