






目录
一.引言
什么是损失函数?
深度学习中,损失函数是用来衡量模型参数的质量的函数,衡量的方式,是比较网络输出 和 真实值的差异
损失函数在不同的文献中,名称是不一样的,主要命名方式有:损失函数,代价函数,目标函数(和真实目标不是一个东西 ),误差函数
二.损失函数
1.分类任务
1.多分类损失函数
在多分类任务通常使用softmax将logits转换为概率的形式,所以多分类的交叉熵损失也叫softmax损失.

1.y是样本x属于某一个类别的真实概率
2.f(x)是样本属于某易类别的预测分数
3.S是softmax激活函数,将属于某一类别的预测分数转换成概率
4.L是用来衡量真实值y和预测值之间差异性的损失结果

# 分类损失函数:交叉熵损失使用nn.CrossEntropyLoss()实现。nn.CrossEntropyLoss()=softmax + 损失计算
def test():
# 设置真实值: 可以是热编码后的结果也可以不进行热编码
# y_true = torch.tensor([[0, 1, 0], [0, 0, 1]], dtype=torch.float32)
# 注意的类型必须是64位整型数据
y_true = torch.tensor([1, 2], dtype=torch.int64)
y_pred = torch.tensor([[0.2, 0.6, 0.2], [0.1, 0.8, 0.1]], dtype=torch.float32)
# 实例化交叉熵损失
loss = nn.CrossEntropyLoss()
# 计算损失结果
my_loss = loss(y_pred, y_true).numpy()
print('loss:', my_loss)注意:y可以进行one-hot编码也可以不进行编码,规定为int64.,因为pytorch里自动,将整数标签转换为了ont-hot标签.
2.多分类任务损失函数
在处理二分类任务时,不在使用softmax激活函数,而使用sigmoid激活函数,损失函数也进行了调整.

1.y是样本x属于某一个类别的真实概率
2.y^是样本属于某一类别的预测概率
3.L是用来衡量真实值y与预测值y^的损失结果
def test2():
# 1 设置真实值和预测值
# 预测值是sigmoid输出的结果
y_pred = torch.tensor([0.6901, 0.5459, 0.2469], requires_grad=True)
y_true = torch.tensor([0, 1, 0], dtype=torch.float32)
# 2 实例化二分类交叉熵损失
criterion = nn.BCELoss()
# 3 计算损失
my_loss = criterion(y_pred, y_true).detach().numpy()
print('loss:', my_loss)2.回归任务
1.MAE损失函数
mean absolute loss 也被称为L1loss ,以绝对误差作为距离

特点:
1.由于L1loss具有稀疏性,为了惩罚较大的值,因此常常将其作为正则项添加到其他LOSS里作为约束.
2.L1 loss 最大的问题是在梯度在零点不平滑,导致会跳过极小值.
# 计算算inputs与target之差的绝对值
def test3():
# 1 设置真实值和预测值
y_pred = torch.tensor([1.0, 1.0, 1.9], requires_grad=True)
y_true = torch.tensor([2.0, 2.0, 2.0], dtype=torch.float32)
# 2 实例MAE损失对象
loss = nn.L1Loss()
# 3 计算损失
my_loss = loss(y_pred, y_true).detach().numpy()
print('loss:', my_loss)2.MSE损失函数
mean quared loss 也被称为L2 Loss
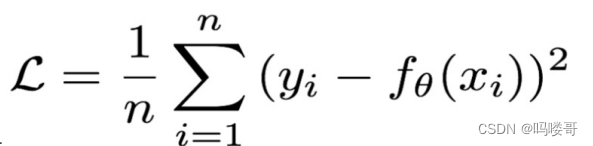
特点:
1.L2 loss也经常作为正则项
2.预测值和目标值相差很大的时候,容易发生梯度爆炸
def test4():
# 1 设置真实值和预测值
y_pred = torch.tensor([1.0, 1.0, 1.9], requires_grad=True)
y_true = torch.tensor([2.0, 2.0, 2.0], dtype=torch.float32)
# 2 实例MSE损失对象
loss = nn.MSELoss()
# 3 计算损失
my_loss = loss(y_pred, y_true).detach().numpy()
print('myloss:', my_loss)3.smooth L1损失函数
光滑之后的L1

x = f(x)-y 真实值和预测值的差值
特点:
1.解决了L1不光滑的问题
2.解决了梯度爆炸的问题
def test5():
# 1 !"#$%&'(%
y_true = torch.tensor([0, 3])
y_pred = torch.tensor ([0.6, 0.4], requires_grad=True)
# 2 $)smmothL1*+,-
loss = nn.SmoothL1Loss()
# 3 ./*+
my_loss = loss(y_pred, y_true).detach().numpy()
print('loss:', my_loss)














 899
899











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









