






摘要:我们推出了MiniMax-01系列,包括MiniMax-Text-01和MiniMax-VL-01,这两个模型在性能上与顶级模型相媲美,同时在处理更长上下文方面展现出卓越的能力。其核心在于闪电注意力机制及其高效扩展性。为了最大化计算能力,我们将其与专家混合(Mixture of Experts, MoE)技术相结合,创建了一个包含32个专家、总参数量达4560亿的模型,其中每个标记(token)激活459亿参数。我们为MoE和闪电注意力机制开发了一种优化的并行策略以及高效的计算-通信重叠技术。这种方法使我们能够在包含数百亿参数的模型上,对跨越数百万标记的上下文进行高效训练和推理。在训练过程中,MiniMax-Text-01的上下文窗口可以达到100万个标记,并且在推理时以较低的成本扩展到400万个标记。我们的视觉-语言模型MiniMax-VL-01是通过使用5120亿个视觉-语言标记进行持续训练而构建的。在标准基准测试和内部基准测试中的实验表明,我们的模型在性能上与GPT-4o和Claude-3.5-Sonnet等最先进模型相当,同时提供了20至32倍更长的上下文窗口。我们已在https://github.com/MiniMax-AI上公开发布了MiniMax-01系列模型。Huggingface链接:Daily Papers ,论文链接:2501.08313
1. 引言
近年来,上下文窗口的扩展主要得益于更强大的GPU和更好的I/O感知的softmax注意力实现。然而,进一步扩展这些窗口仍然面临挑战,这主要源于Transformer模型的二次计算复杂度。为了应对这一挑战,研究人员提出了多种方法来降低注意力机制的计算复杂度,如稀疏注意力、线性注意力、长卷积、状态空间模型等。本文介绍了MiniMax-01系列模型,特别是其在利用闪电注意力机制扩展基础模型方面的创新,以及如何通过混合专家(MoE)技术实现高效训练和推理。
2. 模型架构
2.1 MiniMax-Text-01模型架构
MiniMax-Text-01模型采用了Transformer风格的结构,每个模块包括一个通道混合器(注意力块)和一个特征混合器(MLP块)。模型结合了两种类型的通道混合器:闪电注意力和softmax注意力。特征混合器则采用了MoE结构,包含多个专家。
- 闪电注意力机制:通过利用“右积核技巧”,将二次计算复杂度降低为线性复杂度。具体而言,模型采用了TransNormer的NormAttention机制,并通过策略性地将注意力计算分为块内和块间计算,有效避免了cumsum操作的瓶颈。
- 混合专家(MoE):模型通过MoE技术进一步提升了计算效率。在MoE中,每个输入标记被路由到一个或多个专家,每个专家处理一部分输入。模型采用了token-drop策略来优化训练效率,并引入了辅助损失和全局路由器来确保训练稳定性和负载平衡。
2.2 MiniMax-VL-01模型架构
MiniMax-VL-01是MiniMax系列的视觉-语言模型,通过整合图像编码器和图像适配器,扩展了MiniMax-Text-01的能力,使其能够处理视觉理解任务。模型采用了“ViT-MLP-LLM”范式,包括一个具有3.03亿参数的视觉Transformer(ViT)用于视觉编码,以及一个两层MLP投影器。
3. 模型训练与优化
3.1 训练策略
- 初始预训练:模型使用Xavier初始化方法,采用Adam优化器,并设计了动态批大小调度策略。初始训练序列长度为8192,批大小随着训练进度逐步增加。
- 长上下文扩展:通过三阶段训练过程,逐步扩展模型的训练上下文长度至100万个标记。此外,模型还通过引入高质量的长上下文问答数据,进一步增强了其对长上下文的理解能力。
3.2 计算优化
- MoE优化:通过实现基于token分组的重叠方案,有效减少了MoE训练中的all-to-all通信开销。此外,模型还引入了专家数据并行(EDP)策略,进一步提升了计算效率。
- 长上下文优化:针对长上下文训练中的样本标准化问题,模型采用了数据打包技术,通过在序列维度上连接不同长度的样本,最小化了计算浪费。同时,针对softmax注意力,模型设计了可变长环形注意力机制;针对闪电注意力,模型提出了改进的序列并行性算法(LASP+),显著提升了训练速度。
- 闪电注意力推理优化:通过实现批内核融合、分离预填充和解码执行、多级填充和步幅批矩阵乘法扩展等策略,模型在闪电注意力的推理过程中实现了高效的内存访问和计算效率。
4. 模型性能与评估
4.1 基准测试性能
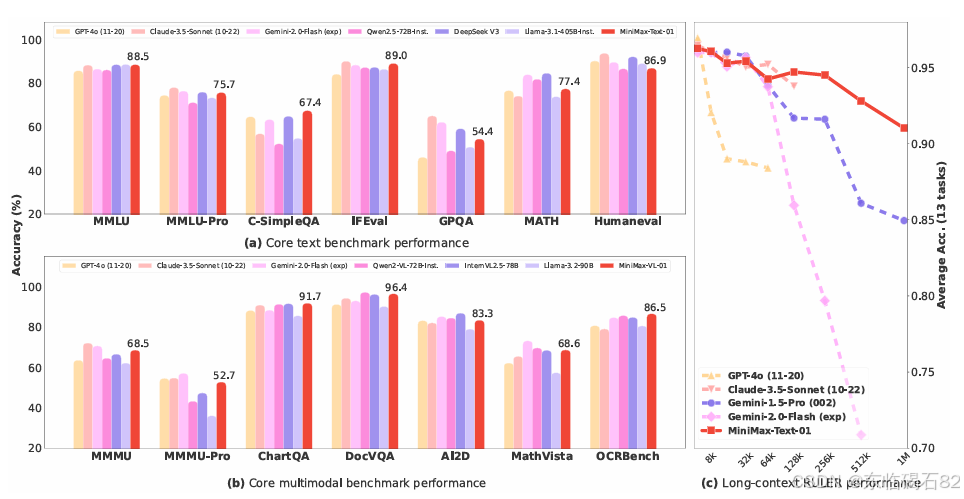
在多个学术基准测试上,MiniMax-Text-01模型展现出了与顶级模型相当的性能。特别是在处理长上下文任务时,模型表现出了显著的优势。例如,在MMLU、MMLU-Pro等基准测试上,MiniMax-Text-01取得了与GPT-4o和Claude-3.5-Sonnet相当的成绩,同时在需要长上下文理解的任务上表现更为出色。
4.2 长上下文评估
- 长上下文检索:通过构建更具挑战性的MR-NIAH任务,模型展示了其在长上下文检索方面的强大能力。实验结果表明,MiniMax-Text-01在处理长达数百万个标记的上下文时,仍能保持稳定的检索性能。
- 长上下文理解:在Ruler和LongBench-V2等基准测试上,模型在处理长上下文理解任务时表现出了卓越的能力。特别是在处理需要复杂推理的长上下文时,模型展现出了显著的优势。
- 长上下文学习:通过MTOB任务,模型展示了其从长上下文中学习新知识的能力。实验结果表明,即使在处理未见过的语言时,模型仍能通过给定的语法书和词表进行有效的翻译。
4.3 内部评估
除了学术基准测试外,模型还通过内部评估来验证其在真实世界场景中的性能。内部评估涵盖了通用助理能力、知识问答、创意写作、硬能力、指令遵循、编码、安全性和长上下文等多个方面。实验结果表明,MiniMax-Text-01在大多数内部评估任务上均表现优异,特别是在需要长上下文理解和生成的任务上展现出了显著的优势。
5. 视觉-语言模型(MiniMax-VL-01)
MiniMax-VL-01模型通过整合图像编码器和图像适配器,扩展了MiniMax-Text-01的能力,使其能够处理视觉理解任务。模型采用了多阶段训练策略,包括模态对齐、视觉理解增强、用户体验增强和偏好增强等阶段。通过持续训练,模型在多个视觉-语言基准测试上取得了优异的成绩,特别是在知识、视觉推理、数学和科学等领域展现出了强大的能力。
6. 未来工作
尽管MiniMax-Text-01和MiniMax-VL-01模型在多个方面展现出了卓越的能力,但仍存在一些局限性需要进一步探索。例如,在长上下文评估方面,当前的数据集主要设计用于人工或简化的场景,而在实际应用中的长文本推理能力评估仍显不足。此外,模型架构方面仍存在优化空间,未来可以探索更高效的架构以完全消除softmax注意力。最后,在复杂编程任务上,模型的表现仍有待提升。未来工作将致力于解决这些问题,并进一步推动基础模型的发展。
7. 结论
本文介绍了MiniMax-01系列模型,特别是其在利用闪电注意力机制扩展基础模型方面的创新。通过结合MoE技术和高效的计算优化策略,模型在处理长上下文方面展现出了卓越的能力。实验结果表明,MiniMax-Text-01和MiniMax-VL-01模型在多个基准测试上均取得了优异的成绩,并在内部评估中验证了其在真实世界场景中的实用性。未来工作将继续探索模型的优化和应用拓展,以推动基础模型的发展和应用落地。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









