






摘要:
测试时扩展是一种颇具前景的语言建模新方法,它利用额外的测试时计算资源来提升性能。最近,OpenAI的o1模型展示了这种能力,但并未公开其方法细节,从而引发了众多复制尝试。我们致力于寻找实现测试时扩展和强大推理性能的最简单方法。首先,我们根据三个通过消融实验验证的标准(难度、多样性和质量),精心构建了一个包含1000个问题及其推理轨迹的小型数据集s1K。其次,我们开发了预算强制技术,通过在模型试图结束时强制终止其思考过程或多次在其生成内容后追加“等待”指令,来控制测试时的计算量。这可以促使模型重新检查其答案,通常能修正错误的推理步骤。在对Qwen2.5-32B-Instruct语言模型进行s1K数据集的监督微调,并配备预算强制技术后,我们的模型s1在竞赛数学题(MATH和AIME24)上的表现超过了o1-preview,最高提升了27%。此外,通过预算强制技术对s1进行扩展,使其能够在没有测试时干预的情况下超越其原有性能:在AIME24上的准确率从50%提高到57%。我们的模型、数据和代码已在GitHub - simplescaling/s1: s1: Simple test-time scaling开源。Huggingface链接:Paper page,论文链接:s1: Simple test-time scaling。
一、引言
测试时扩展的提出与背景
测试时扩展(Test-time Scaling)是一种新兴的语言建模方法,其核心思想是通过在测试阶段增加计算资源来提升模型性能。这一方法近年来受到广泛关注,特别是随着大型语言模型(LLMs)的发展,如何在不改变模型结构的情况下,通过计算资源的调整来优化模型表现成为了一个重要的研究方向。OpenAI的o1模型率先展示了测试时扩展的能力,但其方法并未公开,这促使了众多研究团队尝试复制并改进这一技术。
研究目的与贡献
本文旨在探索实现测试时扩展和强大推理性能的最简单方法。主要贡献包括:
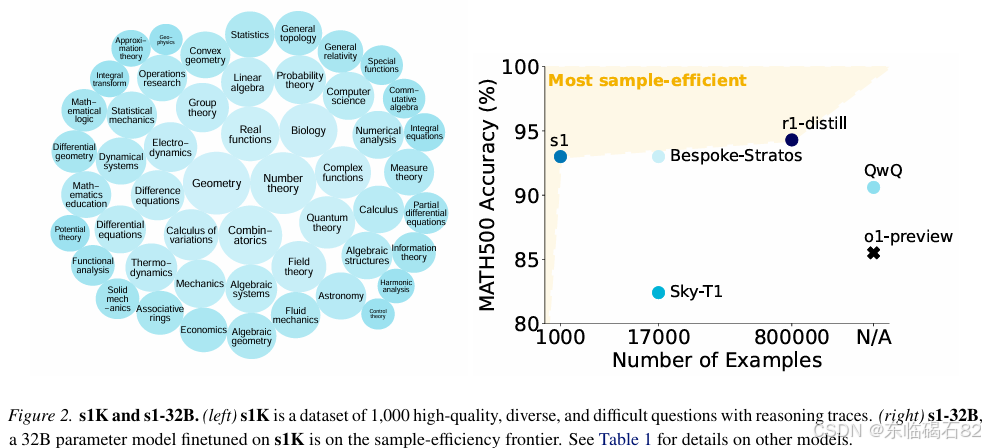
- 构建高质量数据集:通过精心挑选和验证,构建了一个包含1000个问题及其推理轨迹的小型数据集s1K,这些问题涵盖了难度、多样性和质量三个关键维度。
- 开发预算强制技术:提出了一种新的技术——预算强制,通过在模型试图结束时强制终止其思考过程或追加“等待”指令来延长思考时间,从而有效控制测试时的计算量。
- 实现显著性能提升:通过对Qwen2.5-32B-Instruct语言模型进行s1K数据集的监督微调,并配备预算强制技术,本文的模型s1在竞赛数学题上的表现超过了o1-preview,最高提升了27%。
- 开源贡献:将模型、数据和代码全部开源,以促进该领域的研究进展。
二、数据集构建
数据收集与筛选
为了构建s1K数据集,研究团队首先收集了一个包含59029个问题的初始数据集,这些问题来源于16个不同的资源,涵盖了数学、物理、计算机科学等多个领域。在收集过程中,团队遵循了质量、难度和多样性三个关键标准。
- 质量:确保数据集中的问题表述清晰、准确,避免存在格式错误或歧义。
- 难度:选择具有挑战性、需要显著推理努力的问题。
- 多样性:确保数据集涵盖不同领域和类型的问题,以增加模型的泛化能力。
在收集到初始数据集后,研究团队通过三个阶段的筛选,最终得到了包含1000个问题的s1K数据集。这三个阶段分别基于质量、难度和多样性标准进行筛选,确保了s1K数据集的高质量和高价值。
数据集的组成与特点
s1K数据集由1000个问题组成,每个问题都配备了推理轨迹和答案。这些问题涵盖了50个不同的领域,确保了数据集的多样性。同时,通过精心挑选和验证,确保了数据集的质量和难度。此外,研究团队还对数据集进行了去重和污染检查,以确保其可靠性和准确性。
三、预算强制技术
预算强制技术的提出
预算强制技术是一种新的测试时计算控制技术,它通过强制终止模型的思考过程或追加“等待”指令来延长思考时间,从而实现对测试时计算量的有效控制。这一技术的提出旨在解决传统测试时扩展方法中存在的控制不精确和性能不稳定等问题。
预算强制技术的实现方式
预算强制技术的实现方式相对简单但非常有效。当模型试图结束时,如果其生成的思考令牌数未达到预设的最大限制,可以通过追加“等待”指令来延长其思考时间。相反,如果生成的思考令牌数超过了最大限制,则可以强制终止其思考过程。通过这种方式,可以实现对模型思考时间的精确控制,从而提高模型的推理性能和稳定性。
预算强制技术的效果验证
为了验证预算强制技术的效果,研究团队进行了一系列实验。实验结果表明,通过配备预算强制技术,模型s1在竞赛数学题上的表现得到了显著提升。特别是在AIME24数据集上,模型s1的准确率从50%提高到了57%,这一提升幅度超过了其他测试时扩展方法。
四、模型性能与比较
模型性能评估
为了全面评估模型s1的性能,研究团队在多个基准数据集上进行了测试,包括MATH、AIME24和GPQA Diamond等。实验结果表明,模型s1在这些数据集上均取得了显著优于其他模型的表现。特别是在竞赛数学题上,模型s1的表现尤为突出,超过了包括o1-preview在内的多个先进模型。
与其他模型的比较
为了更直观地展示模型s1的优势,研究团队将其与其他先进模型进行了比较。实验结果表明,在相同的计算资源下,模型s1的准确率更高、推理性能更强。特别是在测试时扩展能力方面,模型s1通过配备预算强制技术实现了对计算资源的有效利用和控制,从而取得了显著优于其他模型的表现。
五、消融实验与分析
数据集的消融实验
为了验证s1K数据集在测试时扩展中的关键作用,研究团队进行了一系列消融实验。实验结果表明,通过精心挑选和验证的问题及其推理轨迹对于提高模型的推理性能至关重要。特别是当数据集同时满足难度、多样性和质量三个标准时,模型的性能提升最为显著。
预算强制技术的消融实验
为了验证预算强制技术在测试时扩展中的有效性,研究团队也进行了一系列消融实验。实验结果表明,通过配备预算强制技术,模型在测试时的计算量得到了有效控制,从而提高了模型的推理性能和稳定性。特别是当预算强制技术与s1K数据集结合使用时,模型的性能提升最为显著。
六、讨论与未来工作
测试时扩展的潜力与挑战
测试时扩展作为一种新兴的语言建模方法,具有巨大的潜力和广泛的应用前景。然而,目前仍存在一些挑战和问题,如如何更有效地利用计算资源、如何提高模型的推理性能等。针对这些问题,研究团队提出了一些可能的解决方案和未来工作方向。
未来工作展望
针对测试时扩展领域的研究进展和挑战,研究团队提出了以下未来工作展望:
- 探索更高效的计算资源利用方法:通过优化算法和模型结构等方式来降低计算成本、提高计算效率。
- 提高模型的推理性能:通过引入更强的监督信号、采用更复杂的推理机制等方式来提高模型的推理能力。
- 推动测试时扩展技术的应用:将测试时扩展技术应用于更多实际场景中,如智能客服、自动问答系统等,以推动该技术的普及和发展。
七、结论
本文通过精心构建的高质量数据集s1K和开发的预算强制技术,实现了对测试时扩展和强大推理性能的最简单方法探索。实验结果表明,通过配备预算强制技术的模型s1在竞赛数学题上的表现超过了o1-preview等先进模型,取得了显著的性能提升。同时,通过消融实验和分析验证了s1K数据集和预算强制技术的关键作用。未来工作将围绕更高效的计算资源利用方法、提高模型的推理性能以及推动测试时扩展技术的应用等方面展开。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









