






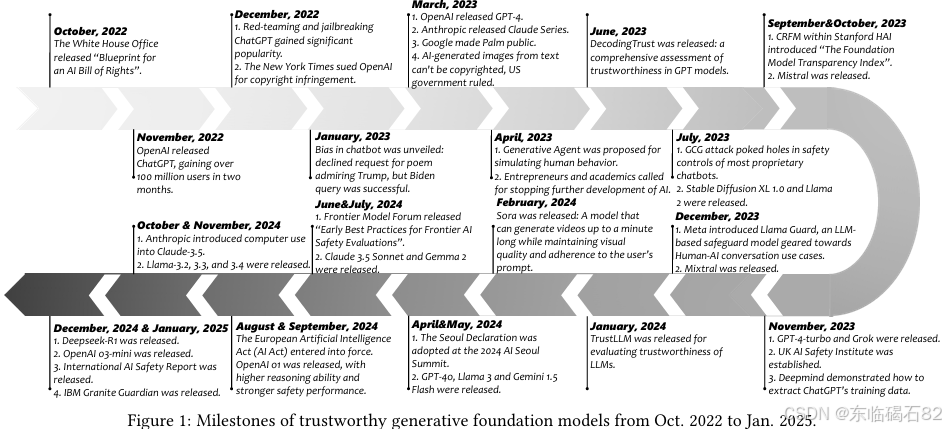
摘要:生成式基础模型(GenFMs)已成为具有变革性的工具。然而,其广泛应用在多个维度上引发了关于可信度的重大担忧。本文通过一个综合框架来应对这些挑战,并做出了三项关键贡献。首先,我们系统回顾了来自政府和监管机构的全球人工智能治理法律和政策,以及行业实践和标准。在此基础上,我们通过广泛的多学科合作,综合技术、伦理、法律和社会视角,提出了一套针对GenFMs的指导原则。其次,我们推出了TrustGen,这是首个旨在跨多个维度和模型类型(包括文本到图像、大型语言和视觉-语言模型)评估可信度的动态基准测试平台。TrustGen利用模块化组件——元数据管理、测试用例生成和情境变化——来实现适应性和迭代式评估,克服了静态评估方法的局限性。通过TrustGen,我们揭示了可信度方面的显著进步,同时也识别出了持续存在的挑战。最后,我们深入讨论了可信GenFMs面临的挑战和未来方向,揭示了可信度的复杂性和不断演变的性质,强调了效用与可信度之间微妙的权衡,并考虑了各种下游应用,识别了持续存在的挑战,并为未来研究提供了战略路线图。这项工作为提升生成式人工智能(GenAI)的可信度建立了一个整体框架,为将GenFMs更安全、更负责任地集成到关键应用中铺平了道路。为了促进社区的发展,我们发布了用于动态评估的工具包。Huggingface链接:Paper page,论文链接:2502.14296
1. 引言
生成式基础模型(Generative Foundation Models, GenFMs)近年来在人工智能领域取得了显著进展,成为推动技术创新的重要力量。然而,随着这些模型在各个领域的广泛应用,其可信度问题日益凸显。可信度不仅关乎模型生成内容的准确性、安全性和公平性,还直接影响到公众对人工智能技术的信任和接受度。本文旨在通过系统回顾和分析现有研究,提出一套针对GenFMs的可信度评估框架,并探讨未来的研究方向。
2. 生成式基础模型概述
生成式基础模型是一类能够生成新内容(如文本、图像、音频等)的人工智能模型。这些模型通过在大规模数据集上进行预训练,学会了数据的内在分布和模式,从而能够生成与训练数据相似的新内容。近年来,随着深度学习技术的不断进步,GenFMs的性能得到了显著提升,已广泛应用于自然语言处理、计算机视觉、多模态融合等多个领域。
3. 可信度评估框架
本文提出的可信度评估框架包含三个核心部分:指导原则、评估平台和未来展望。
3.1 指导原则
为了确保GenFMs的可信度,我们首先需要建立一套明确的指导原则。这些原则应涵盖技术、伦理、法律和社会等多个维度,以确保模型在生成内容时的安全性、公平性和透明度。
- 技术维度:模型应具备良好的泛化能力,能够在未见过的数据上表现出色。同时,模型应能够准确识别并拒绝生成有害或误导性的内容。
- 伦理维度:模型应尊重人类价值观,避免生成歧视性、攻击性或误导性的内容。此外,模型应能够在面对伦理困境时做出合理决策。
- 法律维度:模型应遵守相关法律法规,确保生成内容不侵犯他人权益。这包括版权、隐私权等多个方面。
- 社会维度:模型应能够考虑到不同社会群体的需求和利益,避免加剧社会不平等和偏见。
为了制定这些原则,我们系统回顾了全球范围内的人工智能治理法律和政策,以及行业实践和标准。通过多学科合作,我们综合了技术、伦理、法律和社会视角,提出了一套适用于GenFMs的指导原则。
3.2 评估平台
为了实际评估GenFMs的可信度,我们开发了TrustGen这一动态基准测试平台。该平台能够跨多个维度和模型类型对可信度进行评估,包括文本到图像、大型语言和视觉-语言模型等。
- 模块化设计:TrustGen采用模块化设计,包含元数据管理、测试用例生成和情境变化三个核心模块。这些模块能够协同工作,实现适应性和迭代式评估。
- 动态评估:与传统静态评估方法不同,TrustGen能够进行动态评估。这意味着平台能够随着新模型的出现和用户需求的变化不断更新评估方法和指标,确保评估结果的时效性和准确性。
- 多维度评估:TrustGen能够跨多个维度对GenFMs的可信度进行评估,包括真实性、安全性、公平性、鲁棒性、隐私保护和机器伦理等。这些维度共同构成了GenFMs可信度的全面画像。
通过TrustGen平台,我们对多种GenFMs进行了实际评估,揭示了它们在可信度方面的显著进步以及持续存在的挑战。
3.3 未来展望
尽管GenFMs在可信度方面取得了显著进展,但仍面临诸多挑战。为了推动这一领域的发展,我们需要从多个方面入手:
- 加强跨学科合作:可信度评估涉及技术、伦理、法律和社会等多个领域,需要加强跨学科合作,共同推动研究进展。
- 完善评估方法和指标:随着技术的不断进步和应用场景的不断拓展,我们需要不断完善评估方法和指标,以更准确地反映GenFMs的可信度水平。
- 推动标准化和规范化:为了促进GenFMs的广泛应用和健康发展,我们需要推动相关标准和规范的制定和实施,确保模型在开发、部署和使用过程中遵循统一的标准和要求。
4. 案例分析
为了更具体地说明可信度评估框架的应用,我们以文本到图像模型为例进行详细分析。
4.1 真实性评估
真实性是评估GenFMs可信度的重要指标之一。对于文本到图像模型而言,真实性主要关注模型生成图像与输入文本的一致性。为了评估这一点,我们设计了一系列测试用例,包含各种复杂场景和细节描述。通过对比模型生成图像与预期图像的差异,我们能够量化模型在真实性方面的表现。
4.2 安全性评估
安全性是另一个至关重要的评估维度。对于文本到图像模型而言,安全性主要关注模型是否能够拒绝生成有害或敏感内容。为了评估这一点,我们设计了一系列恶意提示词和测试用例,旨在诱导模型生成不安全内容。通过分析模型对这些提示词和测试用例的响应,我们能够评估模型在安全性方面的表现。
4.3 公平性评估
公平性评估旨在确保模型在不同社会群体之间表现出一致的性能。对于文本到图像模型而言,这主要关注模型是否能够准确生成反映不同社会群体特征的图像。为了评估这一点,我们设计了一系列包含种族、性别等敏感属性的测试用例。通过对比模型在不同测试用例上的表现,我们能够评估模型在公平性方面的表现。
5. 挑战与解决方案
尽管我们提出了一套全面的可信度评估框架,但在实际应用中仍面临诸多挑战。以下是一些主要挑战及相应的解决方案:
- 数据偏见:训练数据中的偏见可能导致模型生成不公平或有害的内容。为了解决这个问题,我们需要采用更加多样化的训练数据集,并确保数据在采集、标注和预处理过程中遵循公平性原则。
- 模型泛化能力:模型在未见过的数据上可能表现出较差的性能。为了提升模型的泛化能力,我们需要采用更加复杂的网络结构和训练策略,并加强模型在不同场景和领域的应用测试。
- 评估方法局限性:现有的评估方法可能无法全面反映模型的可信度水平。为了克服这个局限性,我们需要不断探索新的评估方法和指标,并结合人类专家的判断进行综合评估。
6. 结论
本文提出了一套针对GenFMs的可信度评估框架,并通过实际案例分析和挑战探讨展示了其应用价值和未来发展方向。我们相信,通过不断加强跨学科合作、完善评估方法和指标以及推动标准化和规范化,我们能够推动GenFMs在更广泛领域的安全、公平和负责任应用。这不仅有助于提升公众对人工智能技术的信任和接受度,还将为人工智能技术的可持续发展注入新的动力。
7. 未来研究方向
展望未来,我们认为以下几个方向值得进一步深入研究:
- 多模态融合模型的可信度评估:随着多模态融合技术的不断发展,如何评估这类模型的可信度将成为一个重要研究方向。
- 动态环境下的可信度评估:在实际应用中,模型可能面临不断变化的环境和需求。如何在这种动态环境下持续评估和优化模型的可信度将是一个挑战。
- 人类专家与AI系统的协同评估:结合人类专家的判断和AI系统的自动化评估能力,有望提升评估结果的准确性和可靠性。这将是一个值得探索的研究方向。
总之,生成式基础模型的可信度评估是一个复杂而重要的问题。通过不断努力和探索,我们有望为这一领域的发展贡献更多智慧和力量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









