






摘要:最近发布的DeepSeek-R1展示了强化学习(RL)在提升大型语言模型(LLM)通用推理能力方面的巨大潜力。虽然DeepSeek-R1及其后续工作主要集中在将RL应用于竞技编程和数学问题,但本文介绍了SWE-RL,这是首个将基于RL的LLM推理扩展到现实世界软件工程领域的方法。SWE-RL利用轻量级的基于规则的奖励机制(例如,真实解决方案与LLM生成解决方案之间的相似度得分),使LLM能够通过学习大量的开源软件演化数据——即软件整个生命周期的记录,包括代码快照、代码更改以及问题报告和拉取请求等事件,自主恢复开发者的推理过程和解决方案。我们的推理模型Llama3-SWE-RL-70B是在Llama 3的基础上训练而成的,它在SWE-bench Verified数据集上实现了41.0%的解决率,该数据集是一个经过人工验证的真实GitHub问题集合。据我们所知,这是迄今为止中型(<100B)LLM所报告的最佳性能,甚至与领先的专有LLM(如GPT-4o)相媲美。令人惊讶的是,尽管SWE-RL仅在软件演化数据上进行强化学习,但Llama3-SWE-RL却展现出了泛化推理能力。例如,它在五个领域外任务上表现出了改进的结果,即函数编程、库使用、代码推理、数学和一般语言理解,而监督微调基线平均而言甚至会导致性能下降。总体而言,SWE-RL为通过大规模软件工程数据上的强化学习来提升LLM的推理能力开辟了一个新的方向。Huggingface链接:Paper page,论文链接:2502.18449
一、引言
近年来,大型语言模型(LLMs)在软件工程(SE)任务中的应用受到了广泛关注。研究者们探索了LLMs在自动化各种复杂SE任务方面的潜力,如库级和复杂代码生成、现实世界中的错误/问题解决以及软件测试等。然而,尽管LLMs在这些任务上取得了一定进展,但大多数现有技术依赖于强大的专有LLMs(如GPT-4和Claude-3.5-Sonnet),这些模型的进步更多来自于增强的提示策略,而非底层LLM的改进。
随着DeepSeek-R1的发布,使用基于规则的奖励的强化学习(RL)成为增强LLMs在各种下游任务(包括编码和数学)推理能力的一项关键技术。然而,RL在SE任务中的有效性仍然有限,且现有RL研究通常依赖于执行反馈作为奖励信号,这限制了其在现实世界SE任务中的应用。此外,先前的研究依赖于专有教师模型,并主要集中在监督微调(SFT)上,但本文表明,SFT在有效性和泛化能力方面表现不佳。
为了解决这些局限性,本文提出了SWE-RL,这是首个专门设计用于通过软件演化数据(如拉取请求)和基于规则的奖励来增强LLMs在SE任务上推理能力的方法。
二、SWE-RL方法概述
1. 数据集构建
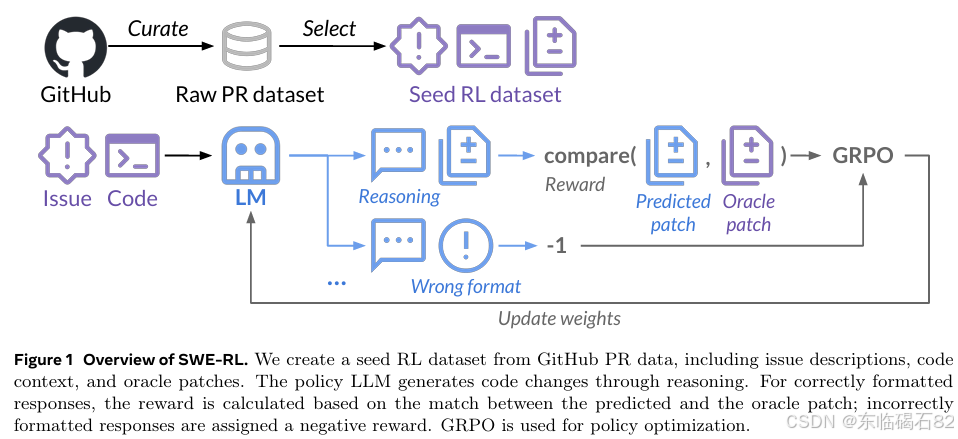
SWE-RL方法的第一步是构建一个全面的GitHub拉取请求(PR)数据集。这一过程包括从GitHub事件和克隆中恢复所有PR的详细信息,这些数据涵盖了从2015年1月到2024年8月的所有活动事件。接着,通过去重、预测相关但未更改的文件、以及过滤掉噪声PR(如机器人生成的PR或空更改的PR)等步骤,最终得到了约1100万个唯一的PR实例。
2. 奖励建模
在SWE-RL中,奖励函数基于预测补丁与真实补丁之间的相似度来计算。具体来说,如果LLM生成的代码更改格式正确,则奖励为预测补丁与真实补丁之间的相似度得分(使用Python的difflib.SequenceMatcher计算);如果格式不正确,则奖励为-1。这种轻量级的基于规则的奖励机制使得LLM能够通过学习大量的开源软件演化数据来自主恢复开发者的推理过程和解决方案。
3. 策略优化
在训练过程中,SWE-RL使用组相对策略优化(GRPO)来优化策略LLM。GRPO通过最大化优势函数来更新策略,同时保持与旧策略和新参考策略之间的KL散度在合理范围内。这种优化方法使得LLM能够在保持稳定性的同时,逐步提升其解决SE任务的能力。
三、实验与结果
1. 实验设置
本文在Llama 3的基础上训练了Llama3-SWE-RL-70B模型,并通过SWE-RL进行了1600步的训练。为了评估模型在现实世界SE任务上的性能,本文在SWE-bench Verified数据集上进行了测试,该数据集是一个包含500个经过人工验证的GitHub问题的集合。
2. 主要结果
实验结果显示,Llama3-SWE-RL-70B在SWE-bench Verified上实现了41.0%的解决率,这是迄今为止中型LLMs所报告的最佳性能,甚至与领先的专有LLMs(如GPT-4o)相媲美。与其他开源基线模型相比,Llama3-SWE-RL-70B在解决率上具有显著优势。
此外,本文还进行了基线比较实验,以了解SWE-RL在提升LLMs解决SE任务能力方面的效果。实验结果显示,与基础Llama-3.3模型和SFT基线相比,Llama3-SWE-RL-70B在格式正确性和修复性能方面均表现出色。尽管其格式准确性略低于SFT版本,但在修复性能上却显著提升。
3. 扩展性分析
本文还进行了扩展性分析,以评估增加修复样本和再生测试样本数量对模型性能的影响。实验结果显示,增加修复样本和再生测试样本数量均能提高模型在SWE-bench Verified上的解决率。然而,当样本数量增加到一定程度时,性能提升的趋势开始趋于平缓。
4. 泛化能力分析
为了评估Llama3-SWE-RL-70B的泛化能力,本文还在五个领域外任务上进行了测试,包括函数编程、库使用、代码推理、数学和一般语言理解。实验结果显示,Llama3-SWE-RL-70B在这些任务上均表现出色,甚至在某些任务上超过了基础模型和SFT基线。这表明SWE-RL不仅能够提升LLMs在SE任务上的推理能力,还能够使其获得泛化推理能力。
5. 奖励消融实验
为了评估不同奖励函数对模型性能的影响,本文还进行了奖励消融实验。实验结果显示,与离散奖励相比,连续奖励在提升模型修复性能方面更为有效。这是因为连续奖励能够更好地捕捉部分正确性和增量改进,从而允许模型学习更细致和有效的修复策略。
四、贡献与局限性
1. 主要贡献
- 提出了SWE-RL方法,这是首个将基于RL的LLM推理扩展到现实世界软件工程领域的方法。
- 开发了Llama3-SWE-RL-70B模型,并在SWE-bench Verified数据集上实现了领先的解决率。
- 展示了通过RL在软件演化数据上训练LLMs可以获得泛化推理能力。
2. 局限性
- 奖励实现仅比较了预测补丁与真实补丁之间的序列相似度,而非语义等价性。这可能限制了策略LLM探索替代的、功能上等效的解决方案的能力。
- 在Agentless Mini中,定位过程被简化为将仓库结构映射到文件路径,这缺乏全面的上下文。
- 作为基于管道的方法,Agentless Mini将所有步骤分解为独立的推理阶段。这种“外部结构”阻止了模型通过交互反馈进行学习,并阻碍了其考虑整个问题的整体性的能力。
- 本文的方法需要大量的采样预算才能达到最佳结果,这对于具有高执行成本的项目可能不切实际。
五、未来工作
为了解决上述局限性,未来的工作将集成代理强化学习到SWE-RL框架中。这将使模型能够独立学习定位和修复策略,而无需依赖外部结构。此外,还将融入执行功能,使模型能够直接与仓库环境进行交互。同时,还将关注提高推理过程中的样本效率,以在保持或提高性能的同时减少样本数量。最终目标是增强SWE-RL的实用性,为活跃的GitHub问题解决提供更强大、更可靠且完全开源的解决方案。
六、结论
本文提出了SWE-RL方法,通过开放软件演化中的强化学习来推进LLMs的推理能力。实验结果显示,Llama3-SWE-RL-70B模型在SWE-bench Verified数据集上实现了领先的解决率,并展现出泛化推理能力。尽管本文的方法存在一定的局限性,但通过未来的工作有望解决这些问题,并为SE领域提供更强大的LLM解决方案。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









