






摘要:近期,语音对话系统在利用大型语言模型(LLM)进行多模态交互方面取得了进展,但仍受到微调需求、高计算开销以及文本与语音不对齐等问题的制约。现有的支持语音的LLM往往通过修改LLM来损害对话质量,从而削弱了其语言能力。相比之下,我们提出了LLMVoX,这是一个轻量级的3000万参数、与LLM无关的、自回归流式文本转语音(TTS)系统,它能够在低延迟下生成高质量语音,同时完全保留基础LLM的能力。我们的方法在与支持语音的LLM相当的延迟和UTMOS(一种评估指标)得分下,实现了显著更低的词错率。
通过多队列令牌流式系统,LLMVoX将语音合成与LLM处理解耦,从而支持无缝、无限长度的对话。其即插即用的设计也便于扩展到具有不同主干网络的各种任务。此外,LLMVoX仅需数据集适配即可泛化到新语言,在阿拉伯语语音任务上实现了低字符错率。
另外,我们已将LLMVoX与视觉-语言模型集成,创建了一个具备语音、文本和视觉能力的全能模型,而无需额外的多模态训练。我们的代码库和项目页面可在https://mbzuai-oryx.github.io/LLMVoX上访问。Huggingface链接:Paper page,论文链接:2503.04724
研究背景和目的
研究背景
随着人工智能技术的快速发展,大型语言模型(LLMs)在自然语言处理领域展现出了卓越的能力,尤其是在理解和生成人类语言方面。然而,在实际应用中,用户往往更倾向于通过语音而非文本与AI系统进行交互。这促使研究人员探索将语音技术与LLMs相结合,以实现更加自然和直观的人机对话系统。
传统的语音对话系统通常依赖于自动语音识别(ASR)和文本转语音(TTS)技术的串联使用,即先将用户语音转换为文本,再由LLM处理并生成回应文本,最后通过TTS技术将回应文本转换回语音。然而,这种方法存在几个显著的缺点:首先,ASR和TTS技术的串联使用导致系统延迟较高,影响用户体验;其次,为了使LLM能够直接处理语音输入和输出,往往需要对LLM进行大规模的微调,这不仅增加了计算成本,还可能损害LLM原有的语言能力;最后,传统方法难以实现文本与语音的完全对齐,影响对话的自然流畅性。
针对上述问题,研究人员开始探索如何在不修改LLM的情况下,实现高效的语音对话系统。近年来,虽然出现了一些能够直接处理语音的LLM变体,但这些模型通常依赖于对LLM的大规模微调,且计算开销较大,限制了其在实际应用中的推广。
研究目的
本研究旨在提出一种轻量级的、与LLM无关的、自回归流式文本转语音(TTS)系统——LLMVoX,以解决现有语音对话系统中存在的问题。具体而言,LLMVoX旨在实现以下目标:
- 低延迟高质量语音生成:在不牺牲语音质量的前提下,显著降低语音生成延迟,提高用户体验。
- 保留LLM能力:通过解耦语音合成与LLM处理,确保LLMVoX能够无缝集成到任何现有的LLM中,同时不损害LLM原有的语言能力。
- 支持无缝对话:通过多队列令牌流式系统,支持无限长度的无缝对话,提升对话的自然流畅性。
- 易于扩展:采用即插即用的设计,便于将LLMVoX扩展到具有不同主干网络的各种任务中。
- 跨语言泛化:通过简单的数据集适配,使LLMVoX能够泛化到新语言中,增强模型的通用性。
研究方法
系统架构
LLMVoX系统架构如图2所示,主要包括以下几个部分:
- 文本处理:LLM生成的文本通过基于ByT5的字母到音素(G2P)模型进行分词,生成字节级别的音素嵌入。
- 输入表示:将音素嵌入与前一语音令牌的特征向量进行拼接,并进行L2归一化处理,然后添加位置嵌入,形成最终的输入表示。
- 解码器:采用仅解码器的Transformer模型,以自回归的方式预测下一个语音令牌。
- 语音重建:通过神经音频编码器将预测的语音令牌解码为语音波形。
神经音频令牌化
为了将语音生成建模为自回归任务,LLMVoX使用神经音频编码器将连续音频波形离散化为固定词汇表中的令牌序列。这些令牌由单层残差向量量化(RVQ)生成,并支持高质量的语音重建,同时保持序列长度可控。
字节级别字母到音素嵌入
为了在不增加额外计算开销的情况下为合成过程注入音素信息,LLMVoX采用基于ByT5的G2P模型的嵌入层。该模型经过100多种语言的微调,其嵌入能够捕捉细微的音素相似性和差异,确保准确的发音。
多队列令牌流式系统
为了支持无缝、无限长度的对话,LLMVoX采用多队列令牌流式系统。具体而言,LLM生成的文本令牌被交替放入两个先进先出(FIFO)队列中,两个复制的TTS模块并行地从这些队列中取出令牌并预测语音令牌。每生成一定数量的语音令牌后,就将其解码为语音并播放,从而实现低延迟的语音生成。
训练与优化
LLMVoX的训练目标是最小化真实语音令牌序列的交叉熵损失。在训练过程中,使用AdamW优化器,并采用梯度裁剪和闪速注意力机制来提高训练效率和稳定性。模型在多个GPU上进行分布式训练,并使用半精度浮点数(bfloat16)来减少内存占用。
研究结果
性能比较
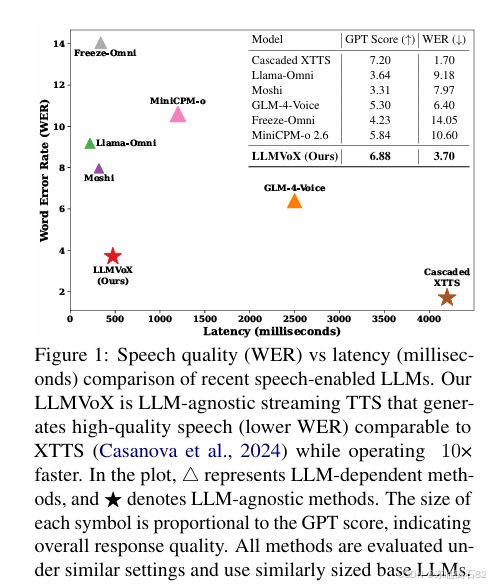
LLMVoX在多个任务上与其他先进的支持语音的LLM进行了性能比较。实验结果表明,LLMVoX在保持较低延迟的同时,实现了与其他模型相当的UTMOS得分,并且在词错率(WER)方面显著优于其他模型(如表1所示)。此外,在阿拉伯语语音任务上,LLMVoX也取得了较低的字符错率(CER),证明了其跨语言泛化能力。
人类评价
为了更全面地评估LLMVoX的性能,研究人员还进行了人类评价实验。实验结果表明,与Freeze-Omni等基线模型相比,LLMVoX在答案相关性和语音清晰度方面均获得了更高的用户评分(如图4所示)。这进一步证明了LLMVoX在生成自然流畅语音方面的优势。
延迟分析
延迟分析实验表明,LLMVoX的端到端延迟远低于传统的串联ASR和TTS系统(如图5所示)。此外,通过增加初始令牌块大小,可以在不显著增加延迟的情况下提高语音质量(如图6所示)。
多模态集成
研究人员还将LLMVoX与视觉-语言模型(VLM)进行了集成,创建了一个具备语音、文本和视觉能力的全能模型。实验结果表明,该模型在视觉语音问答任务上取得了良好的性能,证明了LLMVoX在多模态交互中的潜力。
研究局限
尽管LLMVoX在多个方面表现出色,但其仍存在一些局限性:
- 缺乏声音克隆能力:LLMVoX目前无法生成具有特定说话人特征的语音,限制了其在个性化交互中的应用。
- ASR未完全集成:在当前的系统中,ASR模块并未完全集成到流式处理管道中,这可能限制了延迟的进一步降低。
- 数据集限制:LLMVoX的性能可能受到训练数据集规模和质量的限制。特别是在处理新语言或特定领域的对话时,可能需要更多的数据进行微调。
未来研究方向
针对上述局限性,未来的研究可以从以下几个方面展开:
- 声音克隆与个性化:探索将声音克隆技术集成到LLMVoX中,以实现具有特定说话人特征的语音生成。这将增强模型在个性化交互中的应用潜力。
- ASR流式集成:进一步研究如何将ASR模块完全集成到LLMVoX的流式处理管道中,以进一步降低延迟并提高系统的实时性能。
- 数据集扩展与优化:收集更多样化和高质量的训练数据,特别是针对新语言和特定领域的对话数据。这将有助于提升LLMVoX在这些场景下的性能。
- 多模态交互优化:继续研究如何优化LLMVoX与VLM等其他模态模型的集成方式,以实现更加自然和流畅的多模态交互体验。
综上所述,LLMVoX作为一种轻量级的、与LLM无关的、自回归流式文本转语音系统,在语音对话系统中展现出了巨大的潜力。未来的研究将进一步推动LLMVoX的发展和完善,为实现更加自然和智能的人机交互提供有力支持。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









