






摘要:创造力是智能的一个基本方面,它涉及在不同情境下生成新颖且恰当的解决方案的能力。尽管大型语言模型(LLMs)的创造力已得到广泛评估,但多模态大型语言模型(MLLMs)在这一领域的评估在很大程度上仍未被探索。为填补这一空白,我们推出了Creation-MMBench,这是一个专门设计用于评估MLLMs在基于图像的实际任务中创造力表现的多模态基准测试集。该基准测试集包含765个测试用例,涵盖51个细粒度任务。为确保严格评估,我们为每个测试用例定义了特定的实例评估标准,以指导对通用响应质量和与视觉输入事实一致性的评估。实验结果表明,在创意任务中,当前的开源MLLMs与专有模型相比表现明显不佳。此外,我们的分析表明,视觉微调可能会对基础LLM的创造力产生负面影响。Creation-MMBench为提升MLLMs的创造力提供了宝贵见解,并为未来多模态生成智能的改进奠定了基础。完整的数据和评估代码已发布在https://github.com/open-compass/Creation-MMBench。Huggingface链接:Paper page,论文链接:2503.14478
研究背景和目的
研究背景
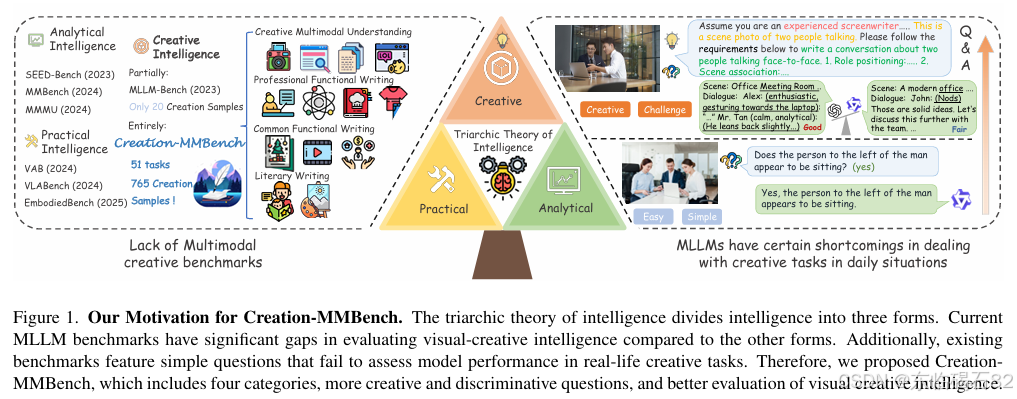
创造力是人类智能的核心组成部分,它涉及在不同情境下生成新颖且合适的解决方案的能力。随着人工智能技术的快速发展,特别是大规模语言模型(LLMs)和多模态大型语言模型(MLLMs)的兴起,评估这些模型在创造力方面的表现变得越来越重要。然而,现有的评估方法主要集中在对LLMs的评估上,而针对MLLMs的创造力评估则相对较少。此外,现有的评估基准往往侧重于单一领域的创造力表现,缺乏全面性和多样性。因此,开发一个专门用于评估MLLMs在多种实际情境下创造力表现的多模态基准测试集显得尤为重要。
当前,MLLMs在图像生成、文本生成、跨模态理解等方面取得了显著进展,但它们在整合视觉信息和语言信息以生成创意文本方面的能力尚未得到充分评估。这种能力对于开发具有上下文感知创造力的MLLMs至关重要,因为它们需要在理解图像内容的基础上,生成与图像紧密相关且富有创意的文本。然而,现有的评估方法往往无法全面反映MLLMs在这方面的能力,因此需要开发一个新的基准测试集来填补这一空白。
研究目的
本研究旨在开发一个专门用于评估MLLMs在真实世界、基于图像的任务中创造力表现的多模态基准测试集——Creation-MMBench。该基准测试集将涵盖多个领域和风格的创意任务,以确保评估的全面性和多样性。通过定义特定的实例评估标准,Creation-MMBench将能够严格评估MLLMs在生成创意文本方面的通用响应质量和与视觉输入的事实一致性。此外,本研究还将通过实验分析现有MLLMs在Creation-MMBench上的表现,揭示它们在创造力方面的优势和局限性,为未来的研究提供有价值的见解。
研究方法
基准测试集构建
- 任务设计:首先,通过头脑风暴和文献综述,确定了一系列涉及创意生成的任务类型,包括文学创作、日常功能写作、专业功能写作和创意多模态理解等。然后,利用大型语言模型生成候选任务,并通过人工精炼和整合,最终确定了51个细粒度任务。
- 数据收集:为每个任务收集了15个精心设计的测试用例,每个测试用例包含一张或多张图像以及详细的查询信息,包括角色、背景知识、指令和要求等。所有查询信息都使用统一的模板进行组织,并发送给MLLMs进行评估。
- 评估标准制定:为每个测试用例定义了特定的实例评估标准,包括通用主观标准和视觉事实性标准。通用主观标准用于评估生成文本的通用响应质量,如结构、风格、流畅性和对查询要求的遵循程度等。视觉事实性标准则用于评估生成文本与视觉输入之间的事实一致性。
实验设置
- 模型选择:选择了多个主流的MLLMs进行实验评估,包括开源模型和专有模型。
- 评估方法:采用MLLM-as-a-judge方法进行评估,即利用一个大型语言模型(如GPT-4o)作为评判模型,对生成文本的质量进行评估。评估过程包括单元评分和成对比较两种方式。
- 实验流程:首先,将视觉输入替换为相应的文本描述,生成Creation-MMBench-TO版本,以评估仅依赖文本输入的MLLMs的创造力表现。然后,在完整的Creation-MMBench上进行实验,评估MLLMs在整合视觉信息和语言信息以生成创意文本方面的能力。
研究结果
实验分析
- 模型性能比较:实验结果表明,在创意任务中,当前的开源MLLMs与专有模型相比表现明显不佳。这可能是由于专有模型在训练数据和计算资源方面的优势,以及它们在处理复杂任务时的更强能力。
- 视觉微调的影响:分析表明,视觉微调可能会对基础LLM的创造力产生负面影响。这可能是由于视觉微调过程中使用的指令长度相似,限制了模型在处理较长文本时把握详细内容的能力,从而导致视觉事实性评分的下降。
- 任务难度分析:在不同类型的任务中,专业功能写作任务表现出相对较弱的性能,而日常功能写作任务则表现出最佳性能。这可能是由于专业功能写作任务需要更广泛的领域知识和对图像内容的深入理解,而日常功能写作任务则相对简单,涉及的是日常生活中的常见任务。
质性分析
通过详细的质性分析,揭示了不同模型在生成创意文本方面的优势和局限性。例如,一些模型在理解图像内容和遵循查询要求方面表现出色,但在生成文本的流畅性和创意性方面存在不足。另一些模型则能够在生成文本的创意性方面取得较好成绩,但在遵循查询要求和保持与视觉输入的事实一致性方面存在挑战。
研究局限
- 数据集规模:尽管Creation-MMBench涵盖了多个领域和风格的创意任务,但其数据集规模仍相对较小。未来可以通过扩展数据集规模来涵盖更多类型的任务和情境,以提高评估的全面性和准确性。
- 评估标准:尽管为每个测试用例定义了特定的实例评估标准,但这些标准可能仍不够细致和完善。未来可以通过引入更多的评估指标和维度来更全面地评估MLLMs的创造力表现。
- 模型选择:本研究仅选择了部分主流的MLLMs进行实验评估,可能无法全面反映当前MLLMs在创造力方面的表现。未来可以引入更多的模型进行实验评估,以更全面地了解MLLMs在创造力方面的优势和局限性。
未来研究方向
- 数据集扩展:未来可以通过扩展Creation-MMBench的数据集规模来涵盖更多类型的任务和情境,以提高评估的全面性和准确性。同时,可以引入更多的图像来源和类型,以增加数据集的多样性和复杂性。
- 评估标准优化:未来可以通过引入更多的评估指标和维度来优化Creation-MMBench的评估标准,以更全面地评估MLLMs的创造力表现。例如,可以引入与创造性相关的心理学指标或用户满意度调查等。
- 模型改进:基于本研究的实验结果和分析,未来可以针对MLLMs在创造力方面的局限性进行改进和优化。例如,可以通过引入更先进的注意力机制、记忆网络等组件来增强模型的上下文感知能力和创造力表现;同时,也可以采用更灵活的训练策略来优化模型的性能。
- 跨模态融合:未来可以进一步探索如何将视觉信息和语言信息更有效地融合在一起,以生成更具创意和相关性的文本。例如,可以开发新的跨模态融合方法和模型架构,以提高MLLMs在整合不同模态信息以生成创意文本方面的能力。
总之,本研究通过开发Creation-MMBench基准测试集,为评估MLLMs在真实世界、基于图像的任务中创造力表现提供了一个新的平台和工具。未来的研究可以在此基础上进一步扩展和优化数据集和评估标准,以更全面地了解MLLMs在创造力方面的表现和潜力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









