



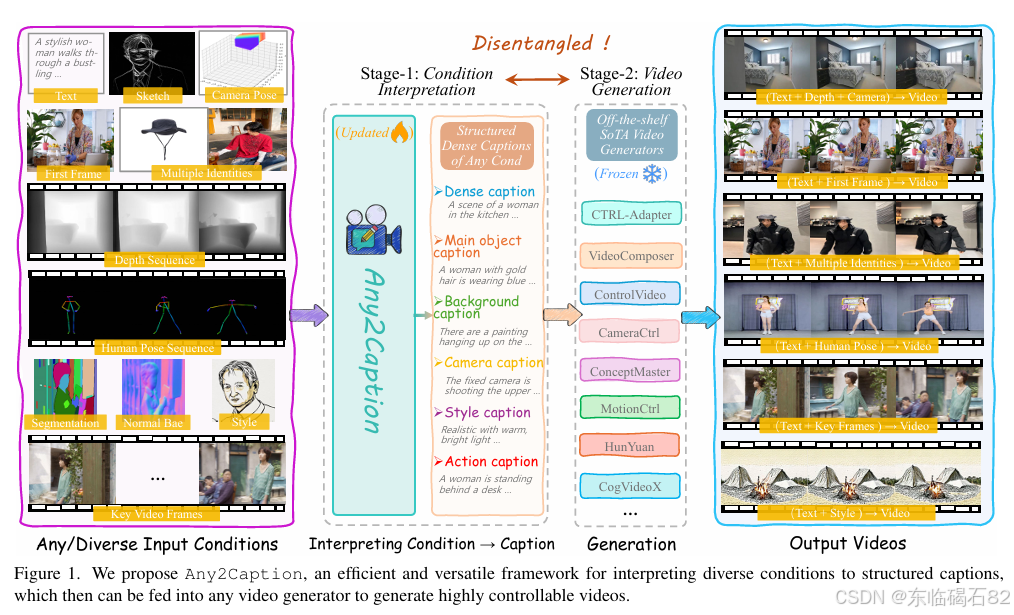
摘要:为解决当前视频生成领域中精准解读用户意图的瓶颈问题,我们提出了Any2Caption,这是一种可在任意条件下实现可控视频生成的新型框架。其核心思想是将各种条件解读步骤与视频合成步骤相分离。通过利用现代多模态大型语言模型(MLLMs),Any2Caption能够将文本、图像、视频以及区域、动作、相机姿态等专门提示等多样化的输入解读为密集且结构化的标题文本,从而为视频生成主干模型提供更优质的指导。此外,我们还引入了Any2CapIns,这是一个包含337K个实例和407K个条件的大规模数据集,专门用于任意条件到标题文本的指令微调。全面的评估结果显示,我们的系统在现有视频生成模型的可控性和视频质量等各个方面均取得了显著提升。项目页面:Any2Caption。Huggingface链接:,论文链接:
研究背景和目的
随着人工智能技术的飞速发展,视频生成作为人工智能领域的一个重要分支,正逐渐成为研究热点。视频作为一种能够捕捉现实世界动态信息的基本媒介,其生成技术在多个领域展现出巨大的应用潜力,如电影制作、动画制作、虚拟现实等。然而,当前视频生成领域面临着一个关键瓶颈,即如何准确解读用户的生成意图,以产生高质量、可控的视频内容。
传统的视频生成方法往往依赖于文本提示,但仅凭文本往往难以充分捕捉用户的复杂意图。为了更全面地理解用户意图,研究者们开始探索将图像、视频以及如区域、动作、相机姿态等专门提示等多样化条件融入视频生成过程。尽管已有一些研究尝试整合多种条件进行视频生成,但它们在处理多模态条件的综合可控性方面仍显不足,尤其是在理解复杂用户意图方面存在局限性。
基于上述背景,本研究旨在提出一种新型的视频生成框架——Any2Caption,以解决当前视频生成领域中精准解读用户意图的瓶颈问题。Any2Caption的核心目标是通过将各种条件解读步骤与视频合成步骤相分离,并利用现代多模态大型语言模型(MLLMs)来解读多样化的输入条件,从而生成密集且结构化的标题文本,为视频生成主干模型提供更优质的指导。这不仅有望提高视频生成的可控性,还能显著提升生成视频的质量。
研究方法
1. Any2Caption框架设计
Any2Caption框架的设计基于以下几个关键步骤:
- 条件解读:利用MLLMs将多样化的输入条件(包括文本、图像、视频以及专门提示等)解读为密集且结构化的标题文本。这些标题文本包含丰富的场景细节、主体描述、背景信息、相机动作、风格描述以及动作描述等,为视频生成提供了全面的指导。
- 视频生成:将生成的标题文本输入到现有的视频生成主干模型中,以产生可控的视频内容。由于标题文本已经对用户的生成意图进行了全面且准确的解读,因此生成的视频能够更好地满足用户的需求。
2. Any2CapIns数据集构建
为了有效训练Any2Caption模型,本研究构建了一个大规模的数据集——Any2CapIns。该数据集包含337K个实例和407K个条件,专门用于任意条件到标题文本的指令微调。数据集的构建过程包括以下几个关键步骤:
- 数据收集:系统地将条件分为四大类:空间条件(如深度图、草图、视频帧等)、动作条件(如人体姿态、动作等)、组成条件(如场景组成、多个身份等)和相机条件(如相机角度、运动轨迹等)。针对每类条件,收集具有代表性的数据集。
- 结构化视频标题生成:采用结构化标题格式,包括密集标题、主体标题、背景标题、相机标题、风格标题和动作标题等。通过独立生成每个标题组件,然后将其整合以构建最终的结构化标题。
- 用户中心化简短提示生成:从用户中心化的角度出发,考虑用户如何自然地表达其意图。利用GPT-4V等工具在条件特定约束下推断潜在的用户提示,并进行手动验证和过滤以进一步精炼数据集。
3. Any2Caption模型训练
Any2Caption模型采用两阶段训练过程:
- 对齐学习阶段:在这一阶段,主要关注将人体姿态特征和相机运动特征与LLM主干模型的词嵌入进行对齐。通过冻结LLM和视觉编码器,仅优化运动编码器和相机编码器,以确保与相机相关的条件被嵌入到模型的潜在空间中。
- 条件解读学习阶段:在已对齐的编码器和预训练的Qwen2-VL权重基础上,对Any2Caption模型进行微调,以解读多模态条件。为了防止直接微调导致的灾难性遗忘,采用渐进式混合训练策略,逐步引入额外的视觉/文本指令数据集进行联合训练。
研究结果
1. 标题生成质量评估
通过实验评估,Any2Caption模型在标题生成质量方面表现出色。在结构性完整性、词汇匹配度、语义匹配度和意图推理得分等多个评估指标上均取得了优异成绩。特别是在相机相关细节的解读方面,模型展现出了最强的性能。此外,模型还能够可靠地将用户偏好融入其结构化输出中。
2. 视频生成质量评估
将Any2Caption生成的标题文本输入到现有的视频生成主干模型中后,生成的视频在多个方面均表现出显著提升。在运动平滑度、动态程度、美学质量和图像完整性等关键维度上,生成的视频均优于直接使用简短提示或简短提示结合条件标题的视频。此外,Any2Caption在处理组合条件时也表现出色,能够准确理解并综合用户约束,生成与用户期望紧密一致的视频内容。
3. 泛化能力评估
通过对未见条件(如风格、分割、草图和掩码图像等)的评估,Any2Caption模型展现出了强大的泛化能力。生成的标题文本能够一致性地提升现有T2V框架的性能,在运动平滑度、美学质量和生成控制准确性等方面均表现出色。这主要归功于MLLM主干的强大推理能力以及渐进式混合训练策略的有效应用。
研究局限
尽管Any2Caption模型在多个方面均取得了显著成果,但仍存在一些局限性:
- 数据多样性受限:当前标注数据的多样性受到现有标注工具能力的限制,这可能影响生成内容的多样性。此外,真实世界数据的稀缺性也可能导致模型在实际场景中的泛化能力受限。
- 幻觉问题:由于模型本身的局限性,可能会产生幻觉现象,导致生成的结构化标题不准确,进而降低生成视频的质量。未来可以考虑开发端到端的方法,联合解读复杂条件并处理视频生成过程。
- 推理时间增加:为了增强对条件的理解能力,Any2Caption模型引入了额外的条件理解模块,这不可避免地增加了推理时间。尽管实验结果显示性能提升显著,但未来仍需探索更高效的架构或优化技术来平衡速度和准确性。
未来研究方向
针对当前研究的局限性,未来可以从以下几个方面展开进一步研究:
- 增强数据多样性:开发更先进的标注工具和方法,以收集更多样化的数据集。这将有助于提升模型的泛化能力和生成内容的多样性。
- 优化模型架构:探索更高效的模型架构和优化技术,以减少推理时间并提高性能。例如,可以采用轻量化模型设计或模型压缩技术来降低计算复杂度。
- 联合解读与生成:开发端到端的方法,联合解读复杂条件并处理视频生成过程。这将有助于减少幻觉现象的发生,并进一步提升生成视频的质量和可控性。
- 拓展应用领域:将Any2Caption模型应用于更多实际场景,如电影制作、动画制作、虚拟现实等。通过实际应用来检验模型的性能和效果,并不断优化和完善模型。
综上所述,Any2Caption作为一种新型的视频生成框架,在解决当前视频生成领域中精准解读用户意图的瓶颈问题方面取得了显著成果。通过不断优化和完善模型架构和数据集构建方法,Any2Caption有望在未来实现更广泛的应用和更高的性能表现。

















 3504
3504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









