






摘要:摄像机轨迹设计在视频制作中起着至关重要的作用,是传达导演意图和增强视觉叙事的基本工具。 在电影摄影中,摄影指导精心设计摄影机运动,以实现富有表现力和有意的构图。 然而,现有的相机轨迹生成方法仍然有限:传统方法依赖于几何优化或手工程序系统,而最近基于学习的方法往往继承了结构偏差或缺乏文本对齐,限制了创意合成。 在这项工作中,我们引入了一种受摄影指导专业知识启发的自回归模型,以生成具有艺术性和表现力的相机轨迹。 我们首先介绍DataDoP,这是一个大规模的多模态数据集,包含29K个真实场景镜头,具有自由移动的相机轨迹、深度图和特定动作的详细说明、与场景的交互以及导演意图。 得益于全面而多样的数据库,我们进一步训练了一个自动回归的、仅解码器的Transformer,用于基于文本指导和RGBD输入的高质量、上下文感知的相机运动生成,名为GenDoP。 大量实验证明,与现有方法相比,GenDoP具有更好的可控性、更细粒度的轨迹调整和更高的运动稳定性。 我们相信我们的方法为基于学习的电影摄影树立了新的标准,为未来相机控制和电影制作的发展铺平了道路。 我们的项目网站:https://kszpxxzmc.github.io/GenDoP/。Huggingface链接:Paper page,论文链接:2504.07083
研究背景和目的
研究背景
在视频制作中,摄像机轨迹设计是传达导演意图和增强视觉叙事效果的关键工具。在电影摄影中,摄影指导通过精心设计的摄像机运动来实现富有表现力和意图明确的构图。然而,现有的摄像机轨迹生成方法存在局限性。传统方法主要依赖于几何优化或手工程序系统,这些方法往往难以处理复杂和多样化的场景。近年来,虽然出现了一些基于学习的方法,但这些方法通常存在结构偏差或缺乏文本对齐的问题,从而限制了创意合成的灵活性。
当前,随着深度学习和人工智能技术的发展,自动生成具有艺术性和表现力的摄像机轨迹成为可能。这种方法不仅能够提高视频制作的效率,还能够为电影制作者提供更多的创意空间。然而,要实现这一目标,需要解决多个挑战,包括如何准确捕捉和理解导演意图,如何生成符合场景和情节需求的摄像机轨迹,以及如何确保生成的轨迹在视觉上连贯和稳定。
研究目的
本研究旨在提出一种新颖的自回归模型GenDoP,用于生成高质量、具有艺术性和表现力的摄像机轨迹。GenDoP模型受摄影指导专业知识的启发,能够基于文本指导和RGBD输入,自动生成符合导演意图和场景需求的摄像机轨迹。通过引入大规模多模态数据集DataDoP,本研究旨在为GenDoP模型提供丰富的训练数据,以提高其生成轨迹的多样性和准确性。最终,本研究希望为基于学习的电影摄影树立新的标准,推动未来相机控制和电影制作技术的发展。
研究方法
数据集构建
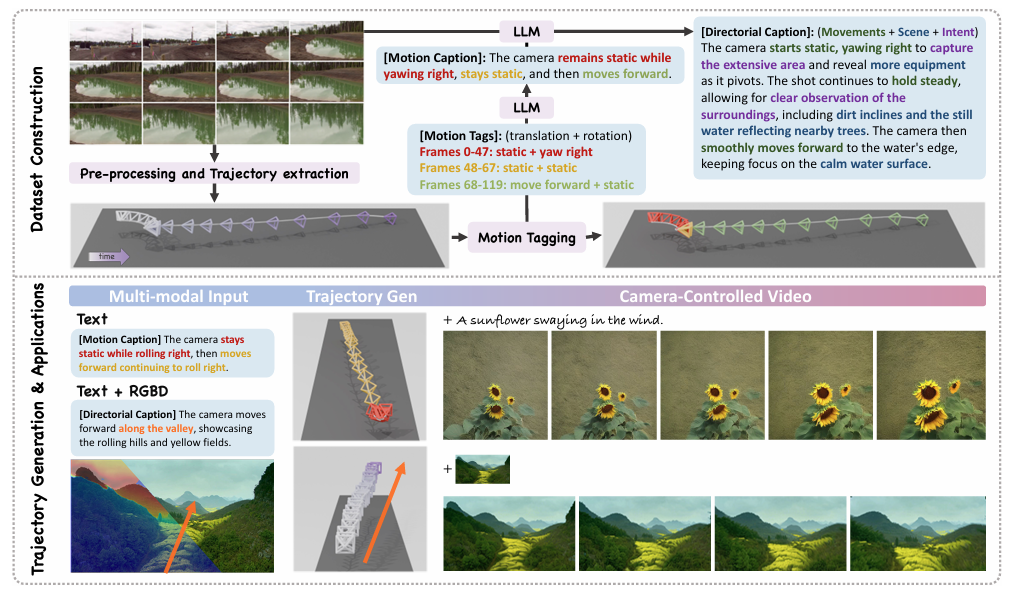
为了训练GenDoP模型,本研究首先构建了一个大规模多模态数据集DataDoP。该数据集包含29K个真实场景镜头,每个镜头都具有自由移动的摄像机轨迹、深度图和详细的轨迹说明。轨迹说明包括摄像机运动的具体动作、与场景的交互以及导演意图。这些说明信息是通过GPT-4o等自然语言处理工具生成的,确保了数据集的准确性和多样性。
在数据集构建过程中,本研究采用了多种预处理和提取技术。首先,使用PySceneDetect等工具对视频进行镜头分割,并使用VSR等工具去除文本覆盖。然后,利用MonST3R等工具估计动态场景的几何信息,提取摄像机轨迹和深度图。最后,对轨迹进行清洗、平滑和插值处理,以确保其适合后续的深度学习训练。
模型设计
GenDoP模型是一种自回归的、仅解码器的Transformer模型。它能够将摄像机参数表示为离散令牌,并利用自回归机制生成摄像机轨迹。GenDoP模型包含文本编码器、RGBD编码器和自回归解码器三个主要部分。
文本编码器用于提取文本说明的语义特征,这些特征随后被传递给自回归解码器以指导轨迹生成。RGBD编码器则用于提取初始帧的RGBD图像特征,这些特征提供了场景的几何和上下文信息,有助于生成更准确的摄像机轨迹。自回归解码器则基于文本和RGBD编码器的输出,逐步生成摄像机轨迹的令牌序列。
在训练过程中,GenDoP模型采用交叉熵损失和正则化项的加权和作为损失函数。通过优化该损失函数,模型能够学习到如何从文本和RGBD输入中生成高质量的摄像机轨迹。
实验设置
本研究在多个实验设置下评估了GenDoP模型的性能。首先,为了验证模型的有效性,本研究在DataDoP数据集上进行了广泛的定量和定性实验。定量实验采用了对比语言-轨迹嵌入(CLaTr)等指标来评估模型生成的轨迹与文本说明的对齐程度和质量。定性实验则通过专家评估和案例分析来验证模型生成的轨迹的视觉连贯性和稳定性。
此外,为了评估模型的泛化能力,本研究还在不同的输入条件下进行了实验。例如,在仅使用文本说明的条件下生成摄像机轨迹,以及在同时使用文本说明和RGBD输入的条件下生成轨迹。这些实验结果表明,GenDoP模型在不同的输入条件下都能够生成高质量的摄像机轨迹。
研究结果
定量结果
在定量实验中,GenDoP模型在多个指标上均表现出色。与现有方法相比,GenDoP模型在文本-轨迹对齐、轨迹质量和覆盖范围等方面均取得了显著的提升。具体来说,GenDoP模型在CLaTr-CLIP和CLaTr-FID等指标上分别取得了0.400和22.714的优异成绩,远远超过了其他基线方法。
此外,本研究还进行了用户研究以验证模型生成轨迹的感知质量。通过邀请27名领域专家对生成的轨迹进行评估,本研究发现GenDoP模型在轨迹一致性、质量和复杂性等方面均获得了较高的排名。这些结果表明,GenDoP模型能够生成符合导演意图和场景需求的摄像机轨迹,并且具有出色的视觉连贯性和稳定性。
定性结果
在定性实验中,GenDoP模型同样表现出色。通过对比分析生成的轨迹和文本说明,本研究发现GenDoP模型能够准确地捕捉和理解导演意图,并生成符合场景和情节需求的摄像机轨迹。此外,GenDoP模型还能够处理复杂的摄像机运动模式,如旋转、平移和缩放等,并生成连贯和稳定的轨迹。
案例分析进一步验证了GenDoP模型的有效性。在不同的输入条件下,GenDoP模型都能够生成高质量的摄像机轨迹,并准确地捕捉场景中的关键元素和情节发展。这些结果表明,GenDoP模型具有出色的泛化能力和创意合成能力,能够为电影制作者提供更多的创意空间。
研究局限
尽管GenDoP模型在摄像机轨迹生成方面取得了显著的进展,但仍然存在一些局限性。首先,由于DataDoP数据集规模有限,模型的泛化能力可能受到一定影响。未来需要收集更多的真实场景镜头来扩展数据集规模,并提高模型的泛化能力。
其次,当前的GenDoP模型主要依赖于文本和RGBD输入来生成摄像机轨迹。然而,在实际的电影制作过程中,可能还需要考虑其他因素,如演员表演、场景布置和灯光效果等。未来需要将这些因素纳入模型输入中,以进一步提高生成的摄像机轨迹的质量和真实感。
此外,当前的GenDoP模型在处理极端复杂的摄像机运动模式时仍存在一定的挑战。例如,在处理快速旋转和缩放等运动时,模型可能无法生成足够平滑和稳定的轨迹。未来需要进一步优化模型结构和训练策略,以提高其在处理复杂运动模式时的性能。
未来研究方向
扩展数据集规模
为了进一步提高GenDoP模型的泛化能力,未来需要收集更多的真实场景镜头来扩展DataDoP数据集规模。通过引入更多样化的场景和摄像机运动模式,可以帮助模型学习到更丰富的特征和模式,从而提高其生成轨迹的质量和多样性。
融合多模态信息
除了文本和RGBD输入外,未来还可以考虑将其他模态的信息纳入GenDoP模型中,如演员表演、场景布置和灯光效果等。通过融合多模态信息,可以帮助模型更全面地理解场景和情节需求,从而生成更符合实际需求的摄像机轨迹。
优化模型结构和训练策略
为了进一步提高GenDoP模型在处理复杂运动模式时的性能,未来需要优化模型结构和训练策略。例如,可以引入更先进的Transformer架构和注意力机制来提高模型的表达能力和泛化能力;同时,还可以采用更高效的训练策略和正则化方法来加速模型收敛并防止过拟合。
拓展应用场景
除了电影制作外,GenDoP模型还可以应用于其他领域,如虚拟现实(VR)、增强现实(AR)和游戏开发等。通过在这些领域中的应用实践,可以进一步验证GenDoP模型的有效性和实用性,并为其未来的发展和改进提供有益的反馈和指导。
综上所述,本研究提出的GenDoP模型在摄像机轨迹生成方面取得了显著的进展,但仍存在一些局限性和挑战。未来需要继续努力扩展数据集规模、融合多模态信息、优化模型结构和训练策略以及拓展应用场景等方面的工作,以推动摄像机轨迹生成技术的不断发展和进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









