






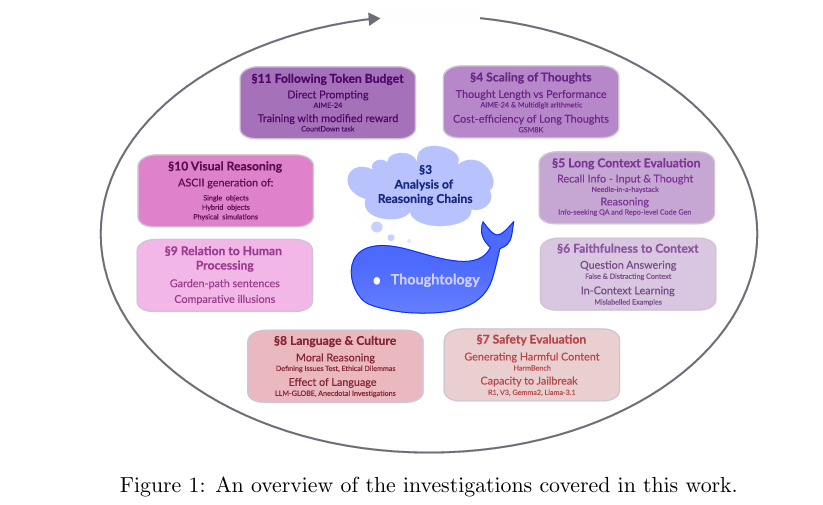
摘要:像DeepSeek-R1这样的大型推理模型标志着LLM在处理复杂问题的方式上发生了根本性的转变。 DeepSeek-R1不是直接为给定的输入生成答案,而是创建详细的多步骤推理链,在提供答案之前似乎“思考”了问题。 这个推理过程对用户是公开的,为研究模型的推理行为创造了无限的机会,并开辟了思维学领域。 从DeepSeek-R1推理的基本构建块的分类学出发,我们对DeepSeek-R1的分析研究了思维长度的影响和可控性、对长或混乱的背景的管理、文化和安全问题,以及DeepSeek-R1相对于认知现象(如类人语言处理和世界建模)的地位。 我们的研究结果描绘了一幅细致入微的画面。 值得注意的是,我们显示DeepSeek-R1有一个推理的“最佳点”,额外的推理时间会损害模型性能。 此外,我们发现DeepSeek-R1倾向于持续思考以前探索过的问题公式,阻碍了进一步的探索。 我们还注意到,与非推理的DeepSeek-R1相比,DeepSeek-R1存在严重的安全漏洞,这也可能危及安全对齐的LLM。Huggingface链接:Paper page,论文链接:2504.07128
研究背景和目的
研究背景
随着人工智能技术的快速发展,大型语言模型(LLMs)在处理自然语言任务方面取得了显著进展。然而,尽管LLMs在生成文本和回答问题方面表现出色,但它们在解决复杂推理任务时仍面临挑战。传统的LLMs往往缺乏系统性的推理能力,倾向于快速给出答案而忽略推理过程,这导致它们在面对需要多步骤逻辑推理的问题时表现不佳。
为了提升LLMs的推理能力,研究者们提出了多种方法,如链式思考(Chain-of-Thought, CoT)提示。然而,这些方法大多依赖于静态的任务特定适应,缺乏动态性和灵活性。此外,随着大型推理模型(Large Reasoning Models, LRMs)如DeepSeek-R1的出现,LLMs的推理能力得到了进一步提升。这些模型不仅能够生成详细的推理链,还能够在推理过程中进行自我验证和探索,从而在解决复杂问题方面表现出色。
尽管LRMs在推理能力上取得了显著进步,但我们对它们的推理行为仍缺乏深入的理解。特别是,关于LRMs如何生成推理链、推理链的长度如何影响模型性能、LRMs如何处理长或混乱的背景信息等问题,我们仍知之甚少。此外,LRMs在道德、文化、安全等方面的表现也亟待研究。
研究目的
本研究旨在深入探索DeepSeek-R1等LRMs的推理行为,理解其生成推理链的机制,并分析推理链长度、背景信息管理、文化和安全考量等因素对模型性能的影响。具体研究目的包括:
- 分析DeepSeek-R1推理链的基本构建块:通过标注和分析DeepSeek-R1生成的推理链,识别其推理过程中的关键步骤和模式。
- 研究推理链长度对模型性能的影响:通过实验分析不同长度的推理链对模型准确性和效率的影响,找出最佳推理长度。
- 探讨DeepSeek-R1对长或混乱背景信息的处理能力:评估DeepSeek-R1在处理复杂或误导性背景信息时的表现,揭示其推理过程的鲁棒性。
- 分析DeepSeek-R1在道德、文化、安全等方面的表现:通过实验评估DeepSeek-R1在道德判断、文化适应性、安全性等方面的表现,探讨其在现实世界应用中的潜在风险和挑战。
- 比较DeepSeek-R1与人类推理过程的异同:通过将DeepSeek-R1的推理链与人类的心理语言学实验数据进行比较,揭示LRMs与人类在推理过程中的相似性和差异性。
研究方法
数据集与模型
本研究使用了多个数据集来评估DeepSeek-R1的推理能力,包括数学推理数据集(如AIME-24、MATH500、GSM8K)、语言处理数据集(如CoQA、SQuAD)、心理语言学数据集(如花园路径句子、比较幻觉)以及视觉推理数据集(如ASCII艺术生成)。此外,本研究还使用了DeepSeek-R1模型,该模型是一个公开的、具备多步骤推理能力的大型语言模型。
实验设计
为了达成研究目的,本研究设计了以下实验:
- 推理链分析:通过标注和分析DeepSeek-R1生成的推理链,识别其推理过程中的问题定义、分解、重构和最终决策等关键步骤。
- 推理链长度实验:通过控制推理链的长度,评估不同长度的推理链对模型准确性和效率的影响。实验包括无约束推理链生成和固定长度推理链生成两种设置。
- 长背景信息处理实验:通过提供长而复杂的背景信息,评估DeepSeek-R1在处理这些信息时的表现。实验包括信息检索任务和长文本理解任务。
- 文化与安全实验:通过设计道德判断任务、文化适应性任务和安全性任务,评估DeepSeek-R1在这些方面的表现。实验包括多语言道德推理任务、有害内容生成任务和越狱攻击生成任务。
- 心理语言学实验:通过将DeepSeek-R1的推理链与人类在心理语言学实验中的表现进行比较,揭示LRMs与人类在推理过程中的相似性和差异性。实验包括花园路径句子处理和比较幻觉任务。
数据分析
本研究采用了定量和定性相结合的分析方法。对于定量数据,如准确性和效率指标,使用统计软件进行假设检验和相关性分析。对于定性数据,如推理链的标注和分析,采用人工标注和主题分析等方法。
研究结果
推理链分析
通过对DeepSeek-R1生成的推理链进行标注和分析,本研究识别了其推理过程中的四个关键步骤:问题定义、分解、重构和最终决策。这些步骤与人类的推理过程相似,表明DeepSeek-R1具备了一定程度的系统性推理能力。
推理链长度实验
实验结果表明,推理链的长度对模型性能有显著影响。对于大多数任务,存在一个最佳推理长度,超过这个长度后,模型的性能会下降。这表明,在推理过程中,过多的思考并不总是有益的,反而可能导致性能下降。此外,本研究还发现,通过限制推理链的长度,可以在不显著降低准确性的前提下显著降低计算成本。
长背景信息处理实验
实验结果显示,DeepSeek-R1在处理长而复杂的背景信息时表现出色,能够在信息检索和长文本理解任务中取得较高准确性。然而,当背景信息过于复杂或包含误导性信息时,DeepSeek-R1的性能会受到影响。这表明,尽管DeepSeek-R1具备一定的鲁棒性,但在处理极端复杂或误导性信息时仍需谨慎。
文化与安全实验
在文化适应性方面,本研究发现DeepSeek-R1在不同语言和文化背景下的表现存在差异。特别是在道德推理任务中,DeepSeek-R1在不同语言和文化背景下的回答反映了不同的文化和价值观。在安全性方面,本研究揭示了DeepSeek-R1存在显著的安全漏洞,能够生成有害内容并越狱其他安全对齐的LLMs。这些发现强调了在使用LRMs时需要谨慎考虑其潜在的安全风险。
心理语言学实验
通过将DeepSeek-R1的推理链与人类在心理语言学实验中的表现进行比较,本研究发现LRMs与人类在推理过程中存在相似之处。特别是在处理花园路径句子和比较幻觉任务时,DeepSeek-R1的推理链长度与人类处理这些任务的认知负荷显著相关。然而,本研究也指出,尽管存在这些相似性,但LRMs的推理过程与人类仍存在显著差异。
研究局限
尽管本研究在探索DeepSeek-R1的推理行为方面取得了显著进展,但仍存在一些局限性:
- 数据集局限性:本研究使用的数据集虽然涵盖了多个领域和任务类型,但仍无法全面反映现实世界中的复杂性和多样性。未来研究需要收集更广泛、更多样化的数据集来进一步验证和扩展本研究的结果。
- 模型局限性:本研究仅针对DeepSeek-R1模型进行了分析,而其他LRMs可能具有不同的推理行为和性能表现。未来研究需要探索更多类型的LRMs,以更全面地理解LRMs的推理机制。
- 人类数据局限性:在将DeepSeek-R1的推理链与人类数据进行比较时,本研究使用了现有的心理语言学实验数据。然而,这些数据可能无法完全反映人类在处理特定任务时的推理过程。未来研究需要设计更精细的实验来收集更准确的人类推理数据。
- 分析局限性:本研究对DeepSeek-R1的推理链进行了标注和分析,但这种方法可能存在一定的主观性和误差。未来研究需要开发更客观、更准确的推理链分析方法,以提高分析结果的可靠性和有效性。
未来研究方向
针对上述研究局限,未来研究可以从以下几个方面展开:
- 扩展数据集:收集更广泛、更多样化的数据集来验证和扩展本研究的结果。特别是在视觉推理、跨语言理解等领域收集更多数据,以更全面地评估LRMs的推理能力。
- 探索更多模型:分析更多类型的LRMs,以更全面地理解LRMs的推理机制。特别是探索那些具有不同架构、不同训练方法和不同应用场景的LRMs。
- 设计更精细的实验:设计更精细的实验来收集更准确的人类推理数据,以便更准确地比较LRMs与人类的推理过程。特别是针对特定任务设计更具针对性的实验范式和评估指标。
- 开发更准确的推理链分析方法:开发更客观、更准确的推理链分析方法,以提高分析结果的可靠性和有效性。特别是结合自然语言处理和机器学习技术来自动化推理链的标注和分析过程。
- 研究LRMs的安全性和可控性:针对LRMs存在的安全漏洞和不可控性问题进行深入研究,提出有效的解决方案来确保LRMs的安全性和可控性。特别是探索如何通过训练数据、模型架构和推理过程等方面的优化来提高LRMs的安全性和可靠性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









