






摘要:多模态大语言模型(MLLM)目前正在经历快速增长,这是由LLM的先进功能推动的。 与早期的专家不同,现有的MLLM正在向多模态通才范式发展。 最初仅限于理解多种模态,这些模型已经发展到不仅能够理解,而且能够跨模态生成。 他们的能力已经从粗粒度的多模态理解扩展到细粒度的多模态理解,从支持有限模态扩展到任意模态。 虽然存在许多基准来评估MLLM,但一个关键问题出现了:我们能否简单地假设,跨任务的更高性能表明MLLM能力更强,使我们更接近人类水平的人工智能? 我们认为,答案并不像看起来那么简单。 该项目引入了通用级,这是一个评估框架,定义了MLLM性能和通用性的5个等级,提供了一种方法来比较MLLM,并衡量现有系统向更强大的多模态通才,并最终向AGI发展的进展。 该框架的核心是协同的概念,它衡量模型在理解和生成以及多种模态之间是否保持一致的能力。 为了支持这一评估,我们提出了通用基准,它包含了更广泛的技能、模式、格式和能力,包括700多个任务和325800个实例。 涉及100多个现有的最先进的MLLM的评估结果揭示了通才的能力排名,突出了实现真正人工智能的挑战。我们希望这个项目为下一代多模态基础模型的未来研究铺平道路,提供一个强大的基础设施来加速实现AGI。 项目主页:https://generalist.top/。Huggingface链接:Paper page,论文链接:2505.04620
研究背景和目的
研究背景
随着人工智能技术的飞速发展,多模态学习(Multimodal Learning)已成为当前研究的前沿领域。传统的单模态学习模型,如仅处理文本或图像的模型,已经难以满足复杂应用场景的需求。多模态学习旨在整合来自不同模态(如文本、图像、音频、视频等)的信息,以实现更全面、准确的理解和生成能力。近年来,大型语言模型(LLMs)在自然语言处理领域取得了显著成功,其强大的语言理解和生成能力为多模态学习提供了新的思路和方法。
多模态大语言模型(Multimodal Large Language Models, MLLMs)作为多模态学习和大型语言模型的结合体,正逐渐成为研究的热点。MLLMs不仅能够处理文本信息,还能整合图像、音频等多种模态的数据,实现跨模态的理解和生成。然而,现有的MLLMs大多仍处于初级阶段,主要聚焦于特定任务或模态的理解,缺乏对多种模态的综合处理能力和通用性。
在此背景下,构建一个全面、细粒度的多模态基准测试集(Benchmark)显得尤为重要。一个好的基准测试集能够客观评估MLLMs的性能,揭示其优势和不足,为后续的研究提供方向。然而,现有的多模态基准测试集大多存在任务覆盖不全、模态支持有限、评估指标单一等问题,难以全面反映MLLMs的真实能力。
研究目的
本研究旨在解决上述问题,通过构建一个名为General-Bench的多模态基准测试集,为MLLMs提供一个全面、细粒度的评估平台。具体而言,本研究的目的包括:
-
扩大任务覆盖范围:General-Bench将涵盖超过700个任务,涉及图像、文本、视频、音频、3D点云等多种模态,以及理解、生成、推理、规划等多种能力,确保对MLLMs进行全面评估。
-
细化评估指标:针对不同任务和模态,设计详细的评估指标和评分标准,确保评估结果的客观性和准确性。
-
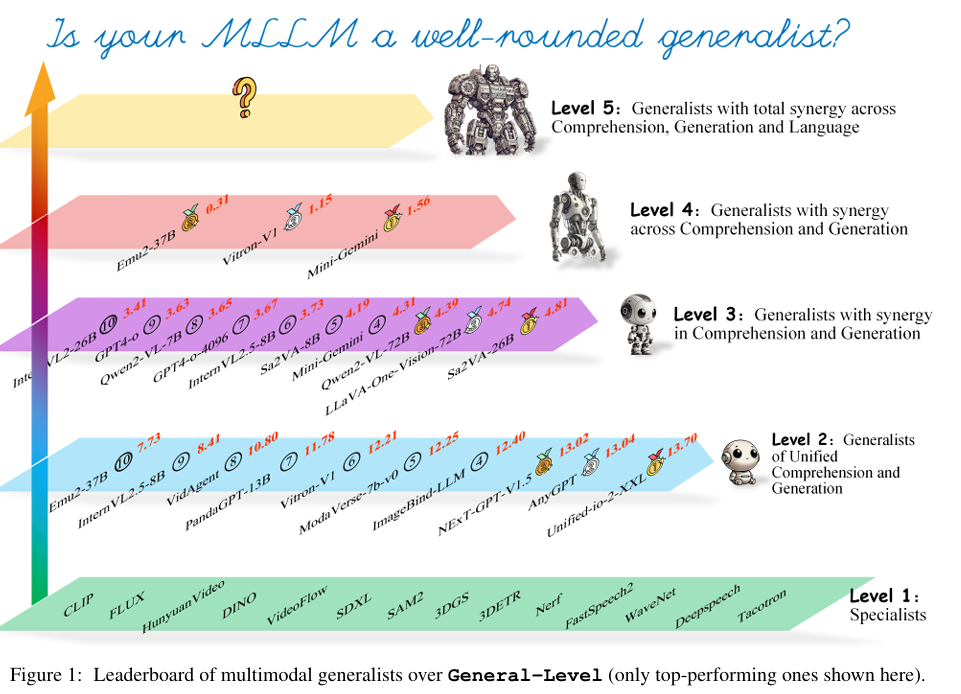
引入通用层级(General-Level)评估框架:定义5个等级的MLLM性能和通用性标准,通过Synergy(协同)概念衡量模型在理解和生成、多种模态之间的一致性能力,为MLLMs的发展提供明确的方向。
-
推动MLLMs向通用人工智能(AGI)发展:通过General-Bench的评估,揭示现有MLLMs的不足,为后续研究提供改进方向,加速MLLMs向更强大的多模态通才和AGI的发展。
研究方法
数据集构建
-
任务收集与分类:从公开资源中收集大量多模态任务,并按照模态(图像、文本、视频、音频、3D点云等)和能力(理解、生成、推理、规划等)进行分类。
-
数据清洗与标注:对收集到的任务数据进行清洗,去除噪声和无关信息,并进行必要的标注,确保数据的质量和可用性。
-
数据集划分:将数据集划分为训练集、验证集和测试集,确保评估的公正性和准确性。同时,为了保持评估的开放性和领导板(Leaderboard)的完整性,将测试集进一步划分为开放集(Open Set)和封闭集(Close Set)。
评估框架设计
-
通用层级(General-Level)定义:根据MLLMs在多种模态和任务上的表现,定义5个等级的通用性标准。每个等级对应不同的能力要求和评估指标。
-
Synergy(协同)概念引入:衡量模型在理解和生成、多种模态之间的一致性能力。通过计算模型在不同任务和模态上的性能差异,评估其协同能力。
-
评估指标细化:针对不同任务和模态,设计详细的评估指标和评分标准。例如,对于图像理解任务,采用准确率(Accuracy)、召回率(Recall)等指标;对于文本生成任务,采用BLEU、ROUGE等指标。
模型评估与比较
-
选择代表性模型:从公开资源中选择超过100个现有的最先进的MLLMs进行评估,包括但不限于GPT-4、LLaVA、MiniGPT-4等。
-
零样本(Zero-shot)评估:在General-Bench数据集上对选定的MLLMs进行零样本评估,即模型在训练过程中未见过测试集中的任务和数据,直接进行评估以反映其泛化能力。
-
性能比较与分析:根据评估结果,对不同MLLMs的性能进行比较和分析,揭示其优势和不足。同时,结合通用层级和Synergy概念,评估模型向AGI发展的潜力。
研究结果
数据集特性
-
任务覆盖广泛:General-Bench涵盖了超过700个任务,涉及多种模态和能力,为MLLMs提供了全面的评估平台。
-
模态支持多样:数据集支持图像、文本、视频、音频、3D点云等多种模态的数据,满足了不同MLLMs的评估需求。
-
评估指标详细:针对不同任务和模态,设计了详细的评估指标和评分标准,确保评估结果的客观性和准确性。
模型性能评估
-
性能排名:通过对超过100个现有的最先进的MLLMs进行评估,得出了各模型在General-Bench上的性能排名。结果显示,不同模型在不同任务和模态上的表现存在显著差异。
-
协同能力分析:通过计算Synergy得分,评估了各模型在理解和生成、多种模态之间的一致性能力。结果显示,部分模型在特定模态或任务上表现出色,但在协同能力上仍有待提高。
-
通用层级评估:根据通用层级标准,对各模型进行了等级划分。结果显示,大多数模型仍处于较低等级,距离实现真正的多模态通才和AGI仍有较大差距。
具体发现
-
内容理解优于生成:在图像和视频理解任务上,许多模型表现出色,甚至超过了特定任务的专家模型。然而,在生成任务上,如图像生成和文本生成,模型的表现普遍较差。
-
跨模态能力有限:尽管MLLMs旨在整合多种模态的信息,但现有模型在跨模态任务上的表现仍不理想。例如,在视频问答任务中,模型需要同时理解视频和文本信息,但现有模型的准确率普遍较低。
-
NLP任务表现突出:在自然语言处理(NLP)任务上,MLLMs表现出色,尤其是在常识推理、因果推理等领域。然而,在数学和代码问题解决任务上,模型的表现仍有待提高。
研究局限
-
数据集规模与多样性:尽管General-Bench已经涵盖了超过700个任务和多种模态的数据,但相对于现实世界的复杂性和多样性而言,其规模和多样性仍有待提高。未来需要进一步扩大数据集规模,增加更多样化的任务和模态。
-
评估指标局限性:现有的评估指标主要关注模型的准确性和召回率等客观指标,但难以全面反映模型的真实能力和用户体验。未来需要探索更多元化的评估指标,如用户满意度、可解释性等。
-
模型泛化能力:在零样本评估中,尽管模型在未见过的任务和数据上表现出了一定的泛化能力,但在面对极端情况或复杂场景时,其性能仍可能大幅下降。未来需要进一步研究如何提高模型的泛化能力和鲁棒性。
-
计算资源限制:评估大量MLLMs需要巨大的计算资源支持。本研究在评估过程中受到了一定计算资源的限制,可能影响了评估结果的全面性和准确性。未来需要寻求更高效的评估方法和计算资源支持。
未来研究方向
-
扩大数据集规模与多样性:继续收集和整理更多样化的多模态任务和数据,扩大General-Bench的规模和覆盖范围。同时,探索如何利用无监督学习、自监督学习等方法自动生成更多样化的训练数据。
-
完善评估指标体系:除了现有的准确性和召回率等客观指标外,探索更多元化的评估指标,如用户满意度、可解释性、公平性等。同时,研究如何将这些指标有机结合起来,形成更全面的评估体系。
-
提高模型泛化能力:研究如何提高MLLMs在未见过的任务和数据上的泛化能力。这包括但不限于改进模型架构、优化训练算法、引入更多先验知识等方法。
-
探索多模态融合机制:深入研究多模态信息之间的融合机制,探索如何更有效地整合来自不同模态的信息。这包括但不限于注意力机制、图神经网络、跨模态变换器等方法。
-
推动MLLMs向AGI发展:结合通用层级和Synergy概念,持续推动MLLMs向更强大的多模态通才和AGI发展。这包括但不限于设计更复杂的评估任务、引入更多元化的评估指标、探索新的模型架构和训练方法等。
-
关注伦理与社会影响:随着MLLMs能力的不断提升,其伦理和社会影响也日益凸显。未来研究需要关注MLLMs在隐私保护、偏见与歧视、就业影响等方面的问题,并提出相应的解决方案和策略。
综上所述,本研究通过构建General-Bench多模态基准测试集,为MLLMs提供了一个全面、细粒度的评估平台。通过对超过100个现有的最先进的MLLMs进行评估,揭示了现有模型的性能排名和不足,为后续研究提供了改进方向。未来研究将继续扩大数据集规模与多样性、完善评估指标体系、提高模型泛化能力、探索多模态融合机制,并推动MLLMs向AGI发展。同时,关注伦理与社会影响,确保MLLMs的健康发展和社会福祉。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









