






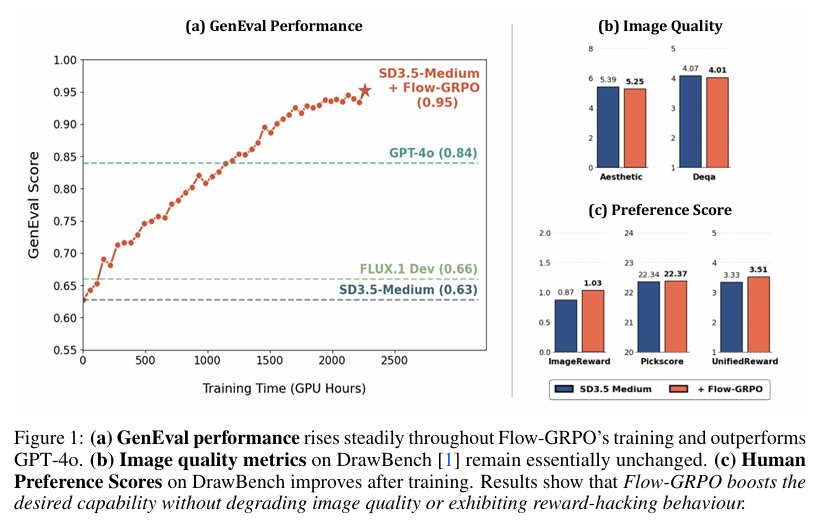
摘要:我们提出了Flow-GRPO,这是第一种将在线强化学习(RL)集成到流匹配模型中的方法。 我们的方法使用两个关键策略:(1)ODE到SDE的转换,将确定性常微分方程(ODE)转换为等价的随机微分方程(SDE),该方程在所有时间步长上与原始模型的边际分布相匹配,从而为RL探索提供统计采样; 以及(2)一种降噪减少策略,该策略减少了训练降噪步骤,同时保留了原始推理时间步数,在不降低性能的情况下显著提高了采样效率。 从经验上来看,Flow-GRPO在多个文本到图像任务中都是有效的。 对于复杂的组合,RL调谐的SD3.5生成了近乎完美的对象计数、空间关系和细粒度属性,将GenEval的准确率从63%提高到95%。 在视觉文本渲染中,其准确率从59%提高到92%,显著增强了文本生成。 Flow-GRPO 在人类偏好对齐方面也取得了实质性的进展。 值得注意的是,几乎没有奖励黑客行为发生,这意味着奖励并没有以牺牲图像质量或多样性为代价,在我们的实验中,这两者都保持稳定。Huggingface链接:Paper page,论文链接:2505.05470
研究背景和目的
研究背景
随着深度学习技术的快速发展,图像生成领域取得了显著进展,其中流匹配(Flow Matching)模型因其坚实的理论基础和在高质量图像生成中的卓越表现而占据主导地位。然而,这些模型在处理复杂场景时,如包含多个对象、属性和关系的图像生成,以及文本渲染任务中,往往面临挑战。同时,在线强化学习(Online Reinforcement Learning, RL)已被证明在提升大型语言模型(LLMs)的推理能力方面非常有效,但在推动流匹配生成模型的发展方面,其潜力尚未得到充分探索。
流匹配模型依赖于确定性生成过程,基于常微分方程(ODEs),这意味着在推理过程中它们无法进行随机采样。相比之下,RL依赖于随机采样来探索环境,通过尝试不同的动作并接收反馈来学习。这种对随机性的需求与流匹配模型的确定性特性相冲突,使得直接将RL应用于流匹配模型面临挑战。此外,在线RL需要高效的采样来收集训练数据,但流模型通常涉及许多迭代步骤来生成每个样本,这在大型、先进的模型中尤为显著,导致计算成本高昂,采样效率低下。
研究目的
本研究旨在探索如何利用在线RL有效改进流匹配模型,以解决其在复杂场景生成和文本渲染任务中的局限性。具体而言,研究目的包括:
-
提出一种新的方法:将在线RL集成到流匹配模型中,通过解决流匹配模型的确定性和采样效率问题,提升其在复杂文本到图像(T2I)生成任务中的表现。
-
验证方法的有效性:通过实验评估新方法在多个T2I任务上的性能,包括组合图像生成、视觉文本渲染和人类偏好对齐任务,证明其在提高生成图像的准确性、文本渲染能力和人类偏好对齐方面的有效性。
-
探索关键策略:研究ODE到SDE的转换策略和降噪减少策略对流匹配模型性能的影响,以及如何通过这些策略在保持图像质量的同时提高采样效率。
研究方法
方法概述
本研究提出了Flow-GRPO方法,通过将在线RL集成到流匹配模型中,利用两个关键策略来克服现有挑战:
-
ODE到SDE的转换:将基于ODE的确定性流模型转换为等价的基于SDE的随机模型,从而在保持原始模型边际分布的同时引入随机性,满足RL探索的需求。
-
降噪减少策略:在训练过程中减少降噪步骤,同时保留完整的推理时间步数,以在不降低性能的情况下显著提高采样效率。
具体实现
- ODE到SDE的转换:
- 理论基础:通过构建一个反向SDE公式,其边际分布与原始ODE模型的边际分布相匹配。具体来说,通过引入扩散系数σt,将ODE dxt = vt dt转换为SDE dxt = vt(xt) - (σ²t/2)∇log pt(xt) dt + σt dw,其中dw表示维纳过程增量。
- 离散化实现:使用Euler-Maruyama方法对SDE进行离散化,得到更新规则:xt+Δt = xt + vθ(xt, t) + (σ²t/2t)(xt + (1-t)vθ(xt, t))Δt + σt√Δtϵ,其中ϵ∼N(0, I)引入随机性。
- 降噪减少策略:
- 训练过程优化:在训练过程中,将降噪时间步数从默认的40步减少到10步,以降低数据生成成本。在推理过程中,仍使用完整的40步降噪步骤,以确保生成高质量图像。
- 实验验证:通过实验证明,减少降噪步骤不会显著影响模型性能,反而能显著提高训练效率。
- Flow-GRPO算法:
- 目标函数:结合GRPO(Group Relative Policy Optimization)算法,优化目标函数包括累积奖励和KL散度约束,以防止奖励黑客行为(即奖励增加但图像质量或多样性下降)。
- 策略更新:通过计算每个图像的优势函数,并使用裁剪目标函数和KL惩罚项来更新策略。
研究结果
实验设置
本研究在三个代表性任务上评估了Flow-GRPO的性能:组合图像生成(使用GenEval基准测试)、视觉文本渲染和人类偏好对齐(使用PickScore奖励模型)。实验设置包括详细的提示和奖励定义,以及超参数和计算资源的具体说明。
主要结果
- 组合图像生成:
- Flow-GRPO显著提高了SD3.5-Medium模型在GenEval基准测试上的准确性,从63%提升至95%,超越了最先进的GPT-4o模型。
- 生成的图像在对象计数、空间关系和细粒度属性方面表现近乎完美。
- 视觉文本渲染:
- Flow-GRPO将SD3.5-Medium模型在视觉文本渲染任务上的准确性从59%提升至92%,显著增强了文本生成能力。
- 人类偏好对齐:
- Flow-GRPO在人类偏好对齐任务上也取得了显著进展,使用PickScore奖励模型证明其任务独立性和鲁棒性。
- 实验中未观察到显著的奖励黑客行为,图像质量和多样性保持稳定。
详细分析
- 奖励黑客行为:
- 通过KL散度约束有效防止了奖励黑客行为,确保奖励增加不以牺牲图像质量或多样性为代价。
- 实验结果表明,去除KL约束会导致图像质量下降和多样性减少,而适当的KL约束能保持高质量和多样性。
- 降噪减少策略的影响:
- 降噪减少策略显著加速了训练过程,减少了数据生成成本。
- 实验表明,减少降噪步骤不会显著影响最终奖励,反而提高了训练效率。
- 噪声水平的影响:
- 适中的噪声水平(如a=0.7)能最大化OCR准确性,噪声过小会限制探索,噪声过大则会降低图像质量。
研究局限
尽管Flow-GRPO在多个T2I任务上取得了显著成果,但仍存在一些局限性:
- 任务特定性:
- 本研究主要关注T2I任务,Flow-GRPO在视频生成等其他多模态任务上的适用性尚未得到充分验证。
- 奖励设计:
- 对于视频生成等复杂任务,定义有效的奖励模型仍然是一个挑战。简单的启发式方法可能不足以促进物理现实主义和时间一致性,需要更复杂的模型。
- 计算资源:
- 尽管降噪减少策略提高了训练效率,但视频生成等任务仍然需要大量计算资源。如何进一步优化数据收集和训练管道,以支持更大规模的任务,是未来的研究方向。
未来研究方向
基于本研究的结果和局限性,未来的研究方向可以包括:
- 多模态任务扩展:
- 探索Flow-GRPO在视频生成、3D模型生成等其他多模态任务上的适用性,定义适合这些任务的奖励模型。
- 奖励模型优化:
- 开发更复杂的奖励模型,以更好地捕捉视频生成等任务中的物理现实主义、时间一致性和其他关键特征。
- 计算效率提升:
- 研究更高效的数据收集和训练管道,以支持更大规模的多模态任务,减少计算资源需求。
- 跨任务泛化能力:
- 评估Flow-GRPO在不同任务和数据集上的泛化能力,探索如何通过迁移学习等技术提高模型在不同场景下的适应性。
- 可解释性和安全性:
- 研究Flow-GRPO生成内容的可解释性,确保生成图像和视频的可靠性和安全性,特别是在敏感领域的应用中。
综上所述,本研究提出了Flow-GRPO方法,通过在线RL有效改进了流匹配模型,在多个T2I任务上取得了显著成果。未来的研究将进一步探索其在多模态任务上的适用性,优化奖励模型,提升计算效率,并关注可解释性和安全性问题。

















 780
780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









