






摘要:我们介绍了一种基于自回归变换器的文本到语音(TTS)模型MiniMax-Speech,它可以生成高质量的语音。 一个关键的创新是我们的可学习说话人编码器,它从参考音频中提取音色特征,而不需要转录。 这使得MiniMax-Speech能够以零样本的方式产生与参考一致的音色,同时支持与参考语音具有极高相似性的单样本语音克隆。 此外,通过提出的Flow-VAE,合成的音频的整体质量得到了提高。 我们的模型支持32种语言,并在多个客观和主观评估指标上表现出色。 值得注意的是,它在客观语音克隆指标(单词错误率和说话者相似度)上取得了最先进(SOTA)的结果,并在公共TTS Arena排行榜上取得了领先地位。 MiniMax-Speech的另一个关键优势在于,它具有稳健且解耦的说话人编码器表示,无需修改基础模型即可扩展,支持各种应用,例如:通过LoRA进行任意语音情感控制; 通过直接从文本描述中合成音色特征进行文本到语音(T2V); 以及通过利用附加数据微调音色特征的专业语音克隆(PVC)。 我们鼓励读者访问Github。Huggingface链接:Paper page,论文链接:2505.07916
研究背景和目的
研究背景
随着深度学习技术的飞速发展,文本到语音(Text-to-Speech, TTS)技术取得了显著进步,广泛应用于对话式人工智能、博客音频内容创作、交互式语音助手以及沉浸式电子书朗读等多个领域。然而,传统的TTS系统往往面临诸多限制,如对大量标注数据的依赖、语音克隆功能对文本转录的依赖、跨语言合成能力有限以及语音自然度和表现力的不足等。
具体而言,大多数自回归(Autoregressive, AR)TTS模型在进行语音克隆时,需要同时提供语音和转录作为提示,这种方法被归类为单样本学习。然而,提示语音与目标语音之间的语义或语言不匹配,加上解码长度的限制,往往导致生成质量不佳。此外,非自回归(Non-Autoregressive, NAR)扩散模型虽然因其快速推理能力而受到关注,但这些模型通常采用持续时间建模技术,可能限制语音的自然度和多样性。
研究目的
本研究旨在解决上述问题,提出一种名为MiniMax-Speech的新型TTS模型。该模型基于自回归变换器架构,并配备了一个可学习的说话人编码器,旨在实现高质量、零样本的语音克隆,并支持多语言合成。具体目标包括:
- 开发一种能够从参考音频中提取音色特征而无需转录的可学习说话人编码器,以实现零样本语音克隆,并支持单样本语音克隆,同时保持与参考语音的高度相似性。
- 通过引入Flow-VAE架构,提升合成音频的整体质量,包括音频的自然度和说话人相似度。
- 验证MiniMax-Speech模型在多种语言上的性能,并通过客观和主观评估指标评估其表现。
- 探索MiniMax-Speech模型在情感控制、文本到语音(T2V)生成以及专业语音克隆(PVC)等下游应用中的扩展性。
研究方法
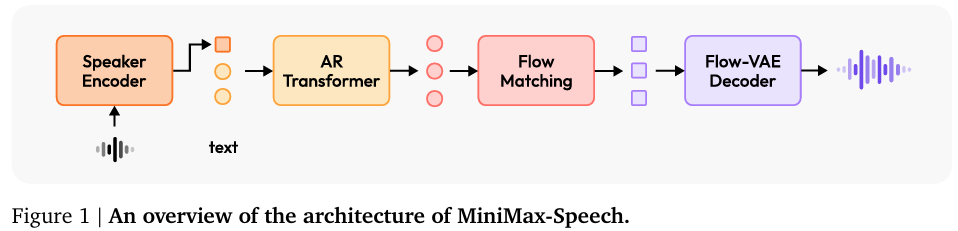
模型架构
MiniMax-Speech模型主要由三个组件构成:文本标记器、自回归变换器和潜在流匹配模型(包括流匹配模块和Flow-VAE模块)。
- 文本标记器:采用字节对编码(Byte Pair Encoding, BPE)技术。
- 自回归变换器:基于Vaswani等人提出的变换器架构,用于从文本输入生成离散音频标记。该变换器通过整合可学习的说话人编码器,实现了强大的零样本语音克隆能力。
- 潜在流匹配模型:包括一个从音频中提取连续语音特征的编码器、一个将这些特征还原为波形的解码器,以及一个将连续语音特征分布转换为标准正态分布的流模型。Flow-VAE通过引入流模型,灵活地转换潜在空间,以更准确地捕捉数据中的复杂模式,从而提升数据建模的准确性。
说话人编码器
说话人编码器从参考音频中提取显著的说话人特征,如音色和韵律风格,并将这些特征转换为固定大小的条件向量,以指导自回归模型生成具有所需说话人身份的目标语音。该编码器与自回归变换器联合训练,以更好地适应语音合成任务,提供更丰富和相关的说话人特定信息。
训练与优化
- 数据集:MiniMax-Speech模型在涵盖32种语言的多语言语音数据集上进行训练。训练过程中,实施了严格的双重自动语音识别(ASR)验证过程,以确保转录的准确性。
- 损失函数:在Flow-VAE模型中,使用KL散度作为约束,以提供足够的后验编码器信息。具体而言,通过流模型将编码器输出的正态分布可逆地转换为标准正态分布,并计算KL损失。
- 评估指标:使用单词错误率(WER)和说话人相似度(SIM)作为客观评估指标,通过人工偏好测试进行主观评估。
研究结果
语音克隆性能
- 零样本与单样本克隆:在Seed-TTS-eval测试集上,MiniMax-Speech模型在零样本和单样本克隆场景下均取得了显著低于Seed-TTS和CosyVoice2的WER,表明其合成的语音具有清晰稳定的发音和较低的发音错误率。同时,在SIM指标上,MiniMax-Speech在零样本克隆中达到了与真实语音相当的水平,单样本克隆中则超过了真实语音,优于CosyVoice2,与Seed-TTS相当。
- 主观评估:在Artificial Arena公共TTS模型排行榜上,MiniMax-Speech凭借其先进的零样本说话人克隆能力,获得了最高的ELO分数,显著优于其他领先模型,包括OpenAI、ElevenLabs、Google、Microsoft和Amazon的模型。
多语言与跨语言合成
- 多语言评估:在24种语言的测试集上,MiniMax-Speech在大多数语言上的WER和SIM指标均优于ElevenLabs Multilingual v2模型,特别是在具有复杂声调结构或多样音素库的语言(如中文、粤语、泰语、越南语和日语)上表现出色。
- 跨语言评估:在跨语言合成任务中,MiniMax-Speech的零样本克隆方法在所有测试语言上的WER均显著低于单样本方法,表明其说话人编码器架构在跨语言合成方面具有优势。
下游应用扩展
- 情感控制:通过LoRA技术实现精确的情感控制,定义离散情感类别,并为每个类别训练独立的LoRA模块。实验结果表明,该方法在情感表达的准确性和自然度上相比现有方法有显著提升。
- 文本到语音(T2V)生成:提出了一种结合开放自然语言描述与结构化标签信息的T2V框架,通过压缩后的音色表示与结构化属性和文本描述一起输入到紧凑的音色生成模型中,实现了高度灵活和可控的音色生成。
- 专业语音克隆(PVC):通过微调特定说话人的条件嵌入,实现了高效快速的专业语音克隆。实验结果表明,PVC方法能够在保持高说话人相似度和自然度的同时,显著提升合成语音对目标说话人独特音色和整体感知质量的 fidelity。
研究局限
- 数据依赖:尽管MiniMax-Speech在零样本语音克隆方面表现出色,但其性能仍然依赖于训练数据的质量和多样性。对于某些稀有语言或特定领域的语音数据,模型可能无法达到最佳性能。
- 计算资源:训练和推理MiniMax-Speech模型需要较高的计算资源,特别是在处理大规模多语言数据集时。这可能限制了模型在某些资源受限环境中的应用。
- 情感表达的复杂性:虽然LoRA技术在情感控制方面取得了显著进展,但情感表达的复杂性仍然是一个挑战。模型可能无法完全捕捉和再现人类语音中的所有细微情感变化。
- 跨语言合成的挑战:尽管MiniMax-Speech在跨语言合成方面表现出色,但在某些语言对之间,特别是当源语言和目标语言在音系结构上存在显著差异时,合成语音的自然度和可懂度可能受到影响。
未来研究方向
- 优化数据利用:探索更高效的数据利用方法,如数据增强、迁移学习和领域自适应技术,以提高模型在稀有语言和特定领域语音数据上的性能。
- 降低计算成本:研究模型压缩和加速技术,如量化、剪枝和知识蒸馏,以降低MiniMax-Speech模型的计算资源需求,使其更易于在资源受限环境中部署。
- 提升情感表达能力:进一步探索情感表达的建模方法,如引入更丰富的情感标注数据、开发更复杂的情感模型或结合多模态信息(如面部表情、手势等)来提升情感控制的准确性和自然度。
- 加强跨语言合成研究:深入研究跨语言合成的挑战和解决方案,如开发更强大的语言无关特征表示、改进跨语言对齐算法或结合多语言预训练模型来提升跨语言合成的性能。
- 探索更多下游应用:除了情感控制、T2V生成和PVC之外,还可以探索MiniMax-Speech模型在其他下游应用中的潜力,如语音转换、语音增强、语音合成中的风格迁移等。
综上所述,MiniMax-Speech模型通过其创新的架构和算法设计,在零样本语音克隆、多语言合成以及下游应用扩展方面取得了显著成果。然而,仍存在一些局限性和挑战需要进一步研究和解决。未来的研究方向将聚焦于优化数据利用、降低计算成本、提升情感表达能力、加强跨语言合成研究以及探索更多下游应用潜力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









