







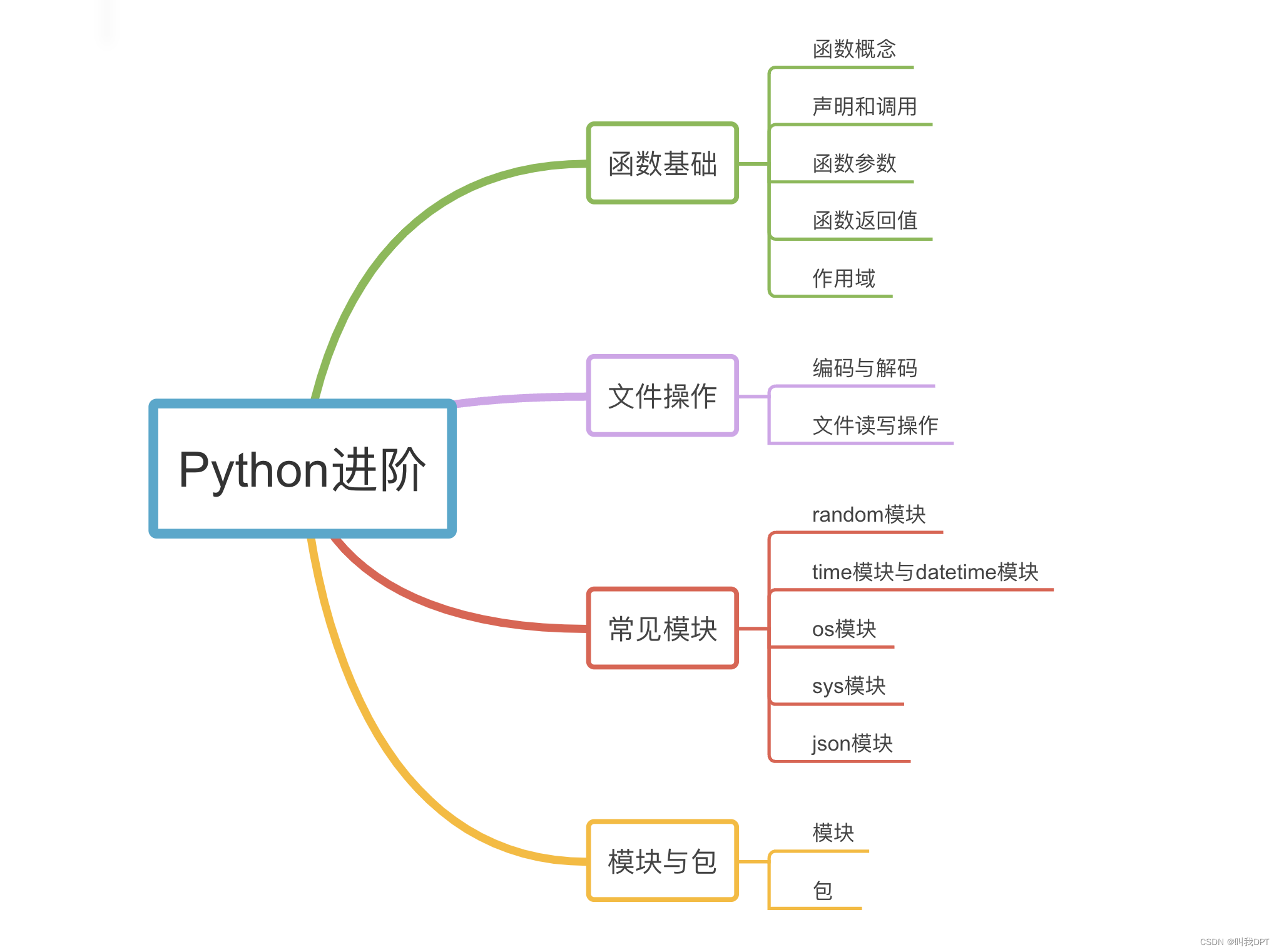
第二章:Python进阶
模块概述
函数是一段可重复使用的代码块,它接受输入参数并返回一个结果。函数可以用于执行特定的任务、计算结果、修改数据等,使得代码更具模块化和可重用性。
模块是一组相关函数、类和变量的集合,它们被封装在一个单独的文件中。模块提供了一种组织和管理代码的方式,使得代码更易于理解、维护和扩展。通过引入模块,我们可以直接使用其中定义的函数、类和变量,而无需重复编写代码。
函数和模块是Python中重要的概念,它们提供了一种有效的方式来组织和管理代码。函数可以增加代码的可读性、可维护性和可扩展性,而模块则进一步提供了命名空间的隔离和代码复用的机制。通过合理使用函数和模块,我们可以编写更加模块化、可维护和可扩展的代码。
Day07:函数基础
一个程序有些功能代码可能会用到很多次,如果每次都写这样一段重复的代码,不但费时费力、容易出错,而且交给别人时也很麻烦,所以编程语言支持将代码以固定的格式封装(包装)成一个独立的代码块,只要知道这个代码块的名字就可以重复使用它,这个代码块就叫做函数(Function)。
函数的本质是一功能代码块组织在一个函数名下,可以反复调用。
去重(函数可以减少代码的重复性。通过将重复的代码逻辑封装成函数,可以避免在不同的地方重复编写相同的代码)
解耦(函数对代码的组织结构化可以将代码分成逻辑上独立的模块,提高代码的可读性和可维护性,从而实现解耦)
# 案例1:
poke_types = ['♥️', '♦️', '♠️', '♣️']
poke_nums = [2, 3, 4, 5, 6, 7, 8, 9, 10, 'J', 'Q', 'K', 'A']
for p_type in poke_types:
for p_num in poke_nums:
print(f"{p_type}{p_num}", sep="\t", end="")
print()
美国人将函数称为“Function”。Function 除了有“函数”的意思,还有“功能”的意思,中国人将 Function 译为“函数”而不是“功能”,是因为C语言中的函数和数学中的函数在使用形式上有些类似。
函数是一种数学概念,它描述了两个数集之间的关系。通俗地说,函数就是一种将输入映射为输出的规则,它可以将一个或多个输入值转换为一个输出值。
如果定义一个函数 f(x) = x^2,那么当输入为 3 时,函数的输出值为 9。
1. 函数声明与调用
# (1) 函数声明
def 函数名():
# 函数体【功能代码块】
# (2)函数调用
函数名()
案例1:
# 函数声明
def print_pokes():
print("=" * 40)
poke_types = ['♥️', '♦️', '♠️', '♣️']
poke_nums = [2, 3, 4, 5, 6, 7, 8, 9, 10, 'J', 'Q', 'K', 'A']
for p_type in poke_types:
for p_num in poke_nums:
print(f"{p_type}{p_num}", sep="\t", end="")
print()
print("=" * 40)
# 函数调用
print_pokes()
# 函数调用
print_pokes()
# 函数调用
print_pokes()
2. 函数参数
在编程中,函数的参数指的是函数定义中声明的变量,用于接收函数调用时传递的数据。参数允许我们将值或引用传递给函数,以便在函数内部使用这些值进行计算、操作或处理。
函数参数可以有多个,每个参数都有一个名称和类型。函数定义中的参数称为形式参数(或简称为形参),而函数调用 时传递的实际值称为实际参数(或简称为实参)。
函数的参数允许函数在不同的上下文中接收不同的数据,并且增加了函数的灵活性和可复用性。通过合理使用函数参数,可以编写出更通用、灵活的函数。
# 案例1:
def cal(n):
ret = 0
for i in range(1, n + 1):
ret += i
print(ret)
cal(100)
- 内置函数:print,type都需要传参数
- 函数传递参数本质是变量赋值,且该变量只在函数运行时存在,运行结束销毁
【1】位置参数
位置参数是按照定义时的顺序进行传递的参数。调用函数时,实参的位置必须与形参的位置一一对应。
# 案例1
def add(x, y): # x,y是形式参数,简称形参
print(x + y)
# add(10, 20) # 10,20是实际参数,简称实参
a = 1
b = 2
add(a, b)
# 案例2
def cal(start, end):
ret = 0
for i in range(start, end + 1):
ret += i
print(ret)
cal(100, 1000)
# 案例3
def send_email(recipient, subject, content):
print("发送邮件...")
print(f"收件人:{recipient}", )
print(f"主题:{subject}")
print(f"内容:{content}")
r = "alex@example.com"
s = "重要通知"
c = "Alex,你已经被解雇,明天不用来公司了!"
send_email(r, s, c)
r = "yuan@example.com"
s = "重要通知"
c = "yuan老师,您太辛苦了,给您涨薪十万!!"
send_email(r, s, c)
【2】默认参数
默认参数是在函数声明时为参数指定默认值。如果在函数调用时没有传递该参数的值,函数将使用默认值。
# 案例1:
def show_info(name, age, height, weight, gender):
print(f"【姓名:{name}】")
print(f"【年龄:{age}】")
print(f"【身高:{height}】")
print(f"【体重:{weight}】")
print(f"【性别:{gender}】")
show_info("yuan", 18, 185, 60, "男")
# 案例2
shopping_cart = [
{
"name": "mac电脑",
"price": 14999,
"quantity": 1
},
{
"name": "iphone15",
"price": 9980,
"quantity": 3
}
]
def cal_total(shopping_cart,discount):
# 计算总价
total = 0
for goods in shopping_cart:
total += goods["price"] * goods["quantity"]
# 最后再算一个折扣
total = round(total * discount)
print(total)
cal_total(shopping_cart,0.8)
注意,如果有默认参数,默认参数一定放在非默认参数后面
练习案例:累加和案例,传一个参数,则为end,传两个值,分别是start和end
【3】关键字参数
关键字参数是通过指定参数名来传递的参数。调用函数时,可以根据参数名来传递实参,而不必遵循形参的顺序。
def show_info(name, age, height, weight):
print(f"【姓名:{name}】")
print(f"【年龄:{age}】")
print(f"【身高:{height}】")
print(f"【体重:{weight}】")
show_info("yuan", height=180, weight=60, age=18)
show_info("yuan", height=180, weight=60, 18)
关键字参数一定要在位置参数后面
关键字参数+默认参数
# 经典用法:默认参数+关键字参数
def show_info(name, age, height=None, weight=None, gender="男"):
print(f"【姓名:{name}】")
print(f"【年龄:{age}】")
if height:
print(f"【身高:{height}】")
if weight:
print(f"【体重:{weight}】")
print(f"【性别:{gender}】")
show_info("yuan", 18, None, 60)
show_info("yuan", 18, weight=60)
show_info("june", 18, gender="女")
【4】可变参数
这节课讲了*和*args,*是python的一个语法糖,用于参数解包,可以将若干个个参数分解为独立的参数。*args可以接受任意数量的位置参数
可变数量参数允许函数接受不定数量的参数。在函数定义中,可以使用特殊符号来表示可变数量的参数,如==*args用于接收任意数量的位置参数,**kwargs用于接收任意数量的关键字参数。==
*args的用法:
a, b, *c = [1, 2, 3, 4, 5]
def add(*args):
s = 0
for i in args:
s += i
print(s)
add(1, 2, 3, 4)
**kwargs的用法:
# 用法1:函数调用的时候使用
def my_function(a, b, c):
print(a, b, c)
a = {'a': 1, 'b': 2, 'c': 3}
my_function(**a)
# 用法2:函数声明的时候使用
def send_email(recipient, subject, body, **kwargs): # **kwargs处理默认参数太多的情况
cc = kwargs.get('cc')
bcc = kwargs.get('bcc')
# 发送邮件的逻辑
print("Sending email...")
print(f"Subject: {subject}")
print(f"Body: {body}")
print(f"To: {recipient}")
print(f"CC: {cc}")
print(f"BCC: {bcc}")
r = "alex@example.com"
s = "重要通知"
c = "Alex,你已经被解雇,明天不用来公司了!"
# 示例调用
send_email(r, s, c, cc="bob@example.com", bcc="charlie@example.com")
def test(a, *b, **c):
print("a", a)
print("b", b)
print("c", c)
test(1, 2, 3, 4, x=10, y=20, z=30)
3. 函数作用域
函数的作用域,访问一个变量时,Python 会按照 LEGB 的顺序进行查找。当然全局变量也不易太多,容易造成全局变量污染,以及对内存造成压力。
global和nonlocal两个关键字声明:global是告诉函数这个变量是全局的变量,不是我函数里的变量,就直接找LEGB中的G了。而nonlocal的使用前提是必须要有函数的嵌套,告诉函数这个变量不是local的变量,所以就在LEGB中的E中找变量。且只能在E中找,不论几层嵌套。
匿名函数lambda的基本使用。这种方式很适合做一些简单的且这使用一次的函数,这样不会占用内存空间。
在模块中定义的叫做全局变量,可以说:函数中定义的一定不是全局变量,除非使用了global关键字
====
作用域(Scope)是指在程序中定义变量或函数时,这些变量或函数可被访问的范围。在不同的作用域中,变量和函数的可见性和访问性是不同的。
当访问一个变量时,Python 会按照 LEGB 的顺序进行查找,直到找到第一个匹配的变量,然后停止查找。如果在所有作用域中都找不到变量的定义,就会引发 NameError。
- L(Local):局部作用域。包括函数内部定义的变量和参数。在函数内部最先进行变量查找。
- E(Enclosing):嵌套函数的父函数的作用域。如果在当前函数内部找不到变量,就会向上一层嵌套的函数中查找。
- G(Global):全局作用域。在模块层次定义的变量,对于整个模块都是可见的。
- B(Built-in):内置作用域。包括 Python 的内置函数和异常。
x = 10 # 全局作用域
def outer_func():
x = 20 # 外部函数作用域
def inner_func():
x = 30 # 内部函数作用域
print(x) # 在内部函数中访问变量 x
inner_func()
outer_func()
print(x) # 在全局作用域中访问变量 x
与函数相关的变量尽量放在函数中,防止全局变量污染
# 案例1
def add(x, y): # x,y是形式参数,简称形参
print(x + y)
x = 10
y = 20
add(x , y) # 10,20是实际参数,简称实参
-
global关键字用于在函数内部声明一个变量为全局变量,表示在函数内部对该变量的修改将影响到全局作用域中的变量。例如:x = 10 def my_function(): global x x = 20 print(x) my_function() # 输出结果为 20 print(x) # 输出结果为 20在函数
my_function内部,使用global关键字声明了变量x为全局变量,然后对其进行了修改。这样,变量x的作用域扩展到了全局范围,所以在函数外部也可以访问到修改后的值。 -
nonlocal关键字用于在函数内部声明一个变量为非本地变量,表示在函数内部对该变量的修改将影响到上一级的嵌套作用域中的变量。例如:def outer_function(): x = 10 def inner_function(): nonlocal x x = 20 print(x) inner_function() # 输出结果为 20 print(x) # 输出结果为 20 outer_function()在
inner_function内部,使用nonlocal关键字声明了变量x为非本地变量,然后对其进行了修改。这样,变量x的作用域扩展到了outer_function的作用域,所以在outer_function内部和外部都可以访问到修改后的值。
4. 函数返回值
函数的返回值是指函数执行完毕后,通过 return 语句返回给调用者的结果。
使用 return 语句可以将一个值或对象作为函数的返回值返回。这个返回值可以是任何有效的Python对象,例如数字、字符串、列表、字典等。函数执行到 return 语句时,会立即结束函数的执行,并将指定的返回值传递给调用者。
如果函内没有return,默认返回None,代表没有什么结果返回
下面是一个简单的函数示例,演示了如何使用返回值:
# 案例1
def add_numbers(a, b):
s = a + b
return s
result = add_numbers(3, 5)
print(result) # 输出: 8
在案例1 中,add_numbers 函数接受两个参数 a 和 b,将它们相加得到 sum,然后通过 return 语句将 sum 返回给调用者。在函数被调用时,返回值被赋值给变量 result,然后可以在后续的代码中使用。
5. 常用的内置函数
str和repr的区别:str是将值转换成字符串,repr是返回对象的字符串表示形式。总而言之:str得到的字符串更易于人类阅读,repr更易于计算机操作。
高阶函数的概念:一函数作为参数或者返回值的函数叫做高阶函数。重点讲了filter,map,sorted这三个高阶函数:他们都通常与lambda表达式一起使用。filter:接收一个函数和一个可迭代对象,将可迭代对象中符合函数要求的元素保留,不符合就过滤。map:接收一个函数和一个可迭代对象,将可迭代对象的元素一一经函数的运算后返回。sorted:接收一个函数和一个可迭代对象,将元素中的元素,通过参数函数指定按什么键进行排序,然后返回结果。这三个高阶函数的参数函数的形参必须要有且尽可以有一个!!!
Python提供了许多内置函数,这些函数是Python语言的一部分,无需导入任何模块即可使用。
Day08:文件操作

1. 字符编码
这节课讲了常见的编码方式:首先诞生的是ASCII码,一个字符代表一个一个字节(8比特),一共可以表示256个字符,对于老美来说够用,但是对中文来说远远不够。所以GBK中文编码就诞生了:GBK使用两个字节表示一个字符。一个可以表示65536个字符。但是此时各个国家又各个国家的编码方式很难统一。此时unicode编码就此诞生,他用4个字节表示一个字符,但是此时内存就大大浪费。所以就有了现在使用广泛的utf-8编码方式,这是一种可变长的编码方式,ASCII 字符使用一个字节表示,而其他字符使用多个字节表示。注意:后面几种编码方式统统支持ASCII编码,也就是说任何编码的前127位都是ASCII编码。
这节课讲了在文件中写入时编辑器会自动通过某种方式进行编码,当打开查看某文档时会自动解码。当编码方式与解码方式不同时,就会导致乱码
这节课讲了encode和decode,编码和解码的函数,字符的编码通常会运用大磁盘存储和网络传输。一般是将字典等高级数据类型先转换为字符串,再转成字节码进行传输。

计算机存储信息的大小,最基本的单位是字节。
-
1KB=1024B
-
1MB=1024KB
-
1GB=1024MB
-
1TB=1024GB
字符编码是将字符集中的字符映射到二进制表示形式的规则集。ASCII、GBK、Unicode和UTF-8是常见的字符编码标准。下面我将对每种编码进行简要介绍:

- ASCII(American Standard Code for Information Interchange):ASCII 是最早的字符编码标准,使用 7 位二进制数(0-127)表示 128 个常用字符,包括英文字母、数字和一些常见的符号。ASCII 编码是单字节编码,每个字符占用一个字节的存储空间。
- GBK(GuoBiao/Kuòbiāo):GBK 是中文编码标准,是国家标准 GB 2312 的扩展,支持汉字字符。GBK 使用双字节编码,其中一个字节表示高位,另一个字节表示低位,可以表示大约 21000 个汉字和其他字符。GBK 编码兼容 ASCII 编码,即 ASCII 字符可以用一个字节表示。
- Unicode(统一码):Unicode 是一种字符编码标准,旨在为全球所有的字符提供唯一的标识符。它使用固定长度的编码单元表示字符,最常见的编码单元是 16 位(如 UTF-16)。Unicode 可以表示几乎所有语言的字符。
- UTF-8(Unicode Transformation Format-8):UTF-8 是一种可变长度的 Unicode 编码标准,通过使用不同长度的字节序列来表示字符。UTF-8 是互联网上最常用的字符编码标准,因为它兼容 ASCII 编码,可以表示全球各种语言的字符。它使用 8 位字节编码,根据字符的不同范围使用不同长度的字节,ASCII 字符使用一个字节表示,而其他字符使用多个字节表示。
编码和解码是在字符编码过程中使用的两个关键概念。编码是将字符转换为特定编码标准下的二进制表示形式,而解码则是将二进制数据转换回字符形式。
在字符编码中,编码器用于将字符转换为相应编码标准下的二进制数据,而解码器用于将二进制数据转换回字符形式。编码和解码的过程是互逆的,可以通过相应的编码和解码算法进行转换。
text = "Hello, 你好"
# 编码过程
encoded = text.encode('utf-8') # 使用 UTF-8 编码将文本转换为二进制数据
print("编码后的数据:", encoded)
# 解码过程
decoded = encoded.decode('utf-8') # 使用 UTF-8 解码将二进制数据转换为文本
print("解码后的文本:", decoded)
输出结果如下:
编码后的数据: b'Hello, \xe4\xbd\xa0\xe5\xa5\xbd'
解码后的文本: Hello, 你好
需要注意的是,在编码和解码过程中,要确保使用相同的编码标准进行处理。否则,编码和解码的结果可能会不正确,导致乱码或数据损坏。
2. 文件操作
open函数用来进行文件操作,返回一个句柄。
重点
open的encoding参数:是用来告诉操作系统用何种解码方式来对该文件进行操作的。
app和硬盘中的文件数据是不能直接进行联系的,这两者需要通过操作系统才能传递信息。操作系统在硬盘中拿到的数据是字节码,然后会根据encoding定义的解码方式进行解码(windows默认是GBK,Mac默认是utf-8),在解码完成后才会将字符串返回给app。
在 Python 中,如果想要操作文件,首先需要创建或者打开指定的文件,并创建一个文件对象,而这些工作可以通过内置的 open() 函数实现。
open() 函数用于创建或打开指定文件,该函数的常用语法格式如下:
def open(file, mode='r', encoding=None,): # known special case of open
【1】读文件
文件的读操作,f.read(),f.readline(),f.readlines(),f.tell可以查看现在光标所在位置,f.seek可以修改光标的位置。
通常不使用 file.read() line = file.readline() lines = file.readlines()这三种读取文件的方式,因为这三种都是直接将文件内容全部读取,如果文件内容特别多的话就会出现问题。一般推荐使用:for line in f:print(line) 的方式,这种对句柄进行循环的操作,会先读取一行内容后打印,在读取下一行此时变量line就重新指向下一行内容,上一行内容就会被自动回收清除。
file = open("example.txt", "r") # 以只读模式打开文件
content = file.read() # 读取整个文件内容
line = file.readline() # 读取一行内容
lines = file.readlines() # 读取所有行,并返回列表
file.close() # 关闭
【2】写文件
在写模式中,open函数的encoding是设置:操作系统在往存储器中写入时的编码方式
在读模式中,open函数的encoding是设置:操作系统在读取到存储器中的内容后以什么方式解码而后返回给APP
file = open("example.txt", "w") # 以只写模式打开文件
file.write("Hello, World!") # 向文件写入内容
# Python 的文件对象中,不仅提供了 write() 函数,还提供了 writelines() 函数,可以实现将字符串列表写入文件中。
# file.writelines(f.readlines())
file.close() # 关闭
注意,写入函数只有 write() 和 writelines() 函数,而没有名为 writeline 的函数。
【3】with open
任何一门编程语言中,文件的输入输出、数据库的连接断开等,都是很常见的资源管理操作。但资源都是有限的,在写程序时,必须保证这些资源在使用过后得到释放,不然就容易造成资源泄露,轻者使得系统处理缓慢,严重时会使系统崩溃。
例如,前面在介绍文件操作时,一直强调打开的文件最后一定要关闭,否则会程序的运行造成意想不到的隐患。但是,即便使用 close() 做好了关闭文件的操作,如果在打开文件或文件操作过程中抛出了异常,还是无法及时关闭文件。
为了更好地避免此类问题,不同的编程语言都引入了不同的机制。在Python中,对应的解决方式是使用 with as 语句操作上下文管理器(context manager),它能够帮助我们自动分配并且释放资源。
with open("example.txt", "r") as file:
content = file.read()
# 在这里进行文件操作,文件会在代码块结束后自动关闭
此外,还有其他文件操作函数和方法可供使用,例如重命名文件、删除文件等。
【4】文件操作案例
在open函数中使用rb和wb模式时,是不需要使用encoding参数的:因为在两种模式下,操作系统不需要编码或者解码,只负责传递信息。
对于图品,视频,音频类的文件,都字符操作无关,这类文件都是由字节码直接构成的,所以使用字节读写操作。
# 版本1:
with open("卡通.jpg", "rb") as f_read:
data = f_read.read()
with open("卡通2.jpg", "wb") as f_write:
f_write.write(data)
# 版本2:
with open("卡通3.jpg", "wb") as f_write:
with open("卡通.jpg", "rb") as f_read:
f_write.write(f_read.read())
Day09:常用模块
1. random模块
random模块是Python的标准库之一,提供了生成伪随机数的功能。它包含了各种生成随机数的函数,以及随机选择和操作的工具函数。下面是random模块的一些常用函数和方法:
random():生成一个0到1之间的随机浮点数。randint(a, b):生成一个指定范围内的随机整数,包括a和b。choice(seq):从给定的序列中随机选择一个元素。sample(seq, k):从给定序列中随机选择k个元素,返回一个新的列表。shuffle(seq):随机打乱给定序列的顺序。
案例
import random
# (1) 模拟硬币投掷
def flip_coin():
if random.random() < 0.5:
return "Heads"
else:
return "Tails"
result = flip_coin()
print("Coin landed on:", result)
# (2) 掷骰子
def roll_dice():
return random.randint(1, 6)
dice_roll = roll_dice()
print("You rolled:", dice_roll)
# (3) 抽奖名单
participants = ['Alice', 'Bob', 'Charlie', 'David', 'Eve']
winner = random.choice(participants)
print("The winner is:", winner)
# (4) 双色球案例:
"""
双色球是中国国家彩票中心发行的一种彩票游戏,其规则如下:
双色球号码池:
红色球号码池:由1到33的红色球号码构成。
蓝色球号码池:由1到16的蓝色球号码构成。
玩法:
玩家需要选择6个红色球号码和1个蓝色球号码来进行投注。
红色球号码可以是任意6个1到33之间的号码,顺序不限。
蓝色球号码是从1到16中选择一个号码。
注意: 6个红色球号码是不能相同的
"""
def lotto():
lotto_list = []
for red_temp in random.sample(range(1, 34), 6):
lotto_list.append(str(red_temp))
blue = str(random.randint(1, 17))
lotto_list.append(blue)
return lotto_list
ret = lotto()
print(f"红球:{' '.join(ret[:-1])}\n蓝球:{ret[-1]}")
# (5) 洗牌
def get_pokes():
poke_list = []
poke_types = ['♥️', '♦️', '♠️', '♣️']
poke_nums = [2, 3, 4, 5, 6, 7, 8, 9, 10, 'J', 'Q', 'K', 'A']
for p_type in poke_types:
for p_num in poke_nums:
poke_list.append(f"{p_type}{p_num}")
return poke_list
poke_list = get_pokes()
random.shuffle(poke_list)
print(poke_list)
2. time模块
time模块是Python标准库中的一个模块,提供了与时间相关的功能和操作。它允许您获取当前时间、进行时间的格式化、进行时间的延迟等操作。下面是time模块的一些主要功能和函数:
- 获取当前时间:
time():返回从1970年1月1日午夜开始经过的秒数(Unix时间戳)。
- 时间延迟和暂停:
sleep(secs):暂停指定的秒数。
- 时间戳和时间元组互换:
localtime([secs]):将秒数转换为当前时区的struct_time对象。mktime(t):将struct_time对象转换为秒数。gmtime([secs]):将秒数转换为UTC时间的struct_time对象。
- 时间格式化:
strftime(format, t):将时间元组对象t按照指定的格式format进行格式化输出。
time模块中的函数返回的时间格式通常是以秒为单位的数值或struct_time对象。如果需要更高级的时间操作,可以考虑使用datetime模块,它提供了更多的时间处理功能。
3. datetime模块
datetime模块,首先说了datetime模块中有四个类分贝是datetime,date,time,timedelta。datetime类的对象的创建与获取;datetime类型对象的属性;datetime对象与格式化字符串的转换。
datetime 模块是Python标准库中的一个模块,提供了处理日期和时间的功能。它建立在 time 模块的基础之上,提供了更高级的日期和时间操作。它提供了多个类和函数,用于创建、操作和格式化日期时间对象,以及执行日期时间的计算和比较。
下面是一些 datetime 模块中常用的功能:
(1)datetime类
datetime类是Python标准库中datetime模块中的一个重要类,用于表示日期和时间。它是一个组合了日期和时间的对象,提供了各种属性和方法来进行日期和时间的处理。下面是datetime类的一些主要属性和方法:
import datetime
# (1) 获取datetime对象
datetime.datetime.now():返回当前的本地日期和时间。
datetime.datetime.today():返回当前日期的datetime对象(时间部分为0时0分0秒)
# 创建特定日期和时间的对象:
datetime.datetime(year, month, day, hour=0, minute=0, second=0, microsecond=0):创建一个代表特定日期和时间的 datetime 对象。
# (2) datetime对象属性:
datetime_obj.year:年份。
datetime_obj.month:月份。
datetime_obj.day:日期。
datetime_obj.hour:小时。
datetime_obj.minute:分钟。
datetime_obj.second:秒数。
# (3) datetime对象和格式化字符串转换
# datetime对象转为格式化字符串
current_datetime = datetime.datetime.now()
format = "%Y-%m-%d %H:%M:%S"
formatted_datetime = current_datetime.strftime(format)
print(formatted_datetime) # 输出:2022-01-01 12:30:45
print(type(formatted_datetime)) # 输出:<class 'str'>
# 时间字符串转为datetime对象
date_string = "2022-01-01 12:30:45"
format = "%Y-%m-%d %H:%M:%S"
parsed_datetime = datetime.datetime.strptime(date_string, format)
print(parsed_datetime) # 输出:2022-01-01 12:30:45
(2)date类
date类是Python标准库中datetime模块中的一个类,用于表示日期。它提供了各种属性和方法来进行日期的处理。下面是date类的一些主要属性和方法:
import datetime
# (1) 获取当前日期对象
today = datetime.date.today()
print(today)
# (2) 日期对象属性:
date_obj.year:年份。
date_obj.month:月份。
date_obj.day:日期。
# (3) date对象转为格式化字符串
today = datetime.date.today()
formatted_date = today.strftime("%Y-%m-%d")
print(formatted_date) # 输出:2024-02-13
(3)timedelta类
用于表示时间间隔的对象,可以进行日期时间的加减运算。常用的方法包括:
timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0):创建一个 timedelta 对象。
timedelta.total_seconds():返回时间间隔的总秒数。
import datetime
# 案例1
from datetime import date
today = date.today()
birthday = date(1998, 5, 15)
age = today - birthday
print("Age:", age.days)
# 案例2
now = datetime.datetime.now()
ret = now + datetime.timedelta(days=3)
print(ret)
4. sys模块
sys模块,是与python解释器打交道的模块。sys.argv返回一个列表,列表中存储命令行执行时传入的参数;sys.version返回解释器的版本信息;sys.exit(0)强制退出程序.
sys 模块是 Python 标准库中的一个模块,提供了与 Python 解释器和系统交互的功能。它提供了许多与系统相关的函数和变量,可以访问和操作解释器的运行时环境、命令行参数、标准输入输出等。
下面是 sys 模块中一些常用的函数和变量:
sys.argv:命令行参数的列表,包括脚本名称和传递给脚本的参数。
sys.exit([arg]):退出当前程序的执行,并返回可选的错误代码 arg。
sys.path:一个列表,包含用于查找模块的搜索路径。
sys.version:当前 Python 解释器的版本信息。
5. os模块
os模块时控制操作系统的:讲了进程管理和文件操作
os模块的执行系统命令和对路径的操作
os 模块是 Python 标准库中的一个模块,提供了与操作系统交互的功能。它允许你访问操作系统的文件系统、执行系统命令等。
下面是os模块一些常用功能的介绍:
- 文件和目录操作:
os.getcwd(): 获取当前工作目录的路径。os.chdir(path): 修改当前工作目录为指定路径。os.listdir(path): 返回指定目录中的文件和目录列表。os.mkdir(path): 创建一个新的目录。os.makedirs(path): 递归创建目录,包括中间目录。os.remove(path): 删除指定的文件。os.rmdir(path): 删除指定的空目录。os.removedirs(path): 递归删除目录,包括所有子目录。os.rename(src, dst): 将文件或目录从src重命名为dst。
- 操作系统命令:
os.system(command): 执行操作系统命令。os.popen(command): 执行操作系统命令,并返回一个文件对象。
- 路径操作:
os.path.join(path1, path2, ...): 将多个路径组合成一个路径。os.path.split(path): 将路径分割成目录和文件名。os.path.dirname(path): 返回路径的目录部分。os.path.basename(path): 返回路径的文件名部分。os.path.exists(path): 检查路径是否存在。
6. json模块
为什么要将数据类型转换为json字符串:方便计算机存储和进行数据传递
序列化:是通过python语言与json对应的格式将数据对象转化为JSON格式的字符串
反序列化:将JSON格式的字符串还原为数据对象
JSON字符串的格式:最外层一定是用单引号包裹且数据中不会出现单引号,数据中的字符串类型都有双引号包裹,true和false一定要小写,JSON格式中的空值为null。
【1】基本概念与语法
序列化是将数据结构或对象转换为字节流(二进制数据)以便存储或传输
反序列化是将字节流还原为原始数据结构或对象的过程。
序列化最重要的就是json序列化。
JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
+-------------------+---------------+
| Python | JSON |
+===================+===============+
| dict | object |
+-------------------+---------------+
| list, tuple | array |
+-------------------+---------------+
| str | string |
+-------------------+---------------+
| int, float | number |
+-------------------+---------------+
| True | true |
+-------------------+---------------+
| False | false |
+-------------------+---------------+
| None | null |
+-------------------+---------------+
json模块是Python标准库中的一个模块,用于处理JSON(JavaScript Object Notation)数据。它提供了一组函数来解析和生成JSON数据,使得在Python中处理JSON变得非常方便。
import json
# 序列化 :将本语言支持的高级数据对象转为json格式字符串的过程
num = 3.14
name = 'yuan'
l = [1, 2, 3]
t = (4, 5, 6)
d = {'name': "yuan", 'age': 18, "is_married": False, "gf": None}
print(repr(json.dumps(num))) # '3.14'
print(repr(json.dumps(name))) # '"yuan"'
print(repr(json.dumps(l))) # '[1, 2, 3]'
print(repr(json.dumps(t))) # '[4,5,6]'
print(repr(json.dumps(d))) # '{"name":"yuan","age":18,"is_married":false,"gf":null}'
# 存储和传输
# 反序列化:将json格式字符串转为本语言支持的数据对象格式
# 案例1
d = {'name': "yuan", 'age': 18, "is_married": False, "gf": None}
json_d = json.dumps(d)
print(json_d, type(json_d))
data = json.loads(json_d)
print(data, type(data))
name = data.get("name")
print(name)
# 案例2:
s = '{"name":"yuan","age":18,"isMarried":False}'
# 重点:反序列化前提数据得是json格式的字符串
data = json.loads(s)
print(data, type(data))
s2 = '[{"name":"yuan","age":18,"isMarried":false},{"name":"rain","age":28,"isMarried":true}]'
data2 = json.loads(s2)
print(data2,type(data2))
print(data2[1].get("name"))
# 思考:json.loads('{"name": "yuan", "age": 23, "is_married": 0}') 可以吗?
【2】应用之持久化存储
import json
dic={'name':'yuan','age':23,'is_married':False}
data=json.dumps(dic) # 序列化,将python的字典转换为json格式的字符串
print("type",type(data)) # <class 'str'>
with open('json.txt','w') as f:
f.write(data) # 等价于json.dump(dic,f)
with open('json.txt') as f:
# 反序列化成为python的字典,等价于dic=json.load(f)
data = f.read()
dic = json.loads(data)
print(type(dic))
【3】应用之网络传输
JSON在网络传输中的应用,就是进行dumps和loads操作,JS中是JSON.stringfy和JSON.parse
前端
// 序列化
data = {user:"yuan",pwd:123}
console.log(JSON.stringify(data)) // '{"user":"yuan","pwd":123}'
// 反序列化
res_json = '{"name": "yuan", "age": 23, "is_married": 0}'
let res = JSON.parse(res_json)
console.log(res)
后端
import json
# 反序列化
data = '{"user":"yuan","pwd":123}'
data_dict = json.loads(data)
print(type(data_dict))
# 序列化
res = {'name':'yuan','age':23,'is_married':0}
res_json = json.dumps(res) # 序列化,将python的字典转换为json格式的字符串
print(repr(res_json)) # '{"name": "yuan", "age": 23, "is_married": 0}'
JSON细节补充!!!
- 当数据中有中文时,JSON会默认根据unicode编码将中文转换,如果不想的话可以在dumps时设置ensure_ascii参数为False
- 当字典的键值为整形时,使用JSON序列化会将键全部转化为字符串的形式,在反序列化回来仍然时字符串形式,所以如果不是非要使用整形作为键时,干脆就全部设为字符串。或者也可以在最后对字典进行操作{int(k):v for k,v in ret_dict.items()}
- 当使用python对字典进行序列化时,字典元素之间的逗号和键值之间的冒号 之后都会有一个空格。而JS序列化之后就不会有。如果需要两者一直的话:可以在dumps时设置separate参数。separatec参数是一个元组,第一个设置元素间的间隔方式,第二个设置键值之间的间隔方式。
7. 日志模块
python中的日志库logging配置通常比较复杂,构建日志服务器时也不是方便。标准库logging的替代品是loguru,使用起来就简单的多。开箱即用,使用方便得多;另外,日志输出内置了彩色功能,颜色和非颜色控制很方便,更加友好。
是非标准库,需要事先安装,命令是:
pip3 install loguru
loguru的基本使用
日志模块的基本操作:loguru模块中的logger,六种级别的日志,默认在控制台打印,使用add添加到.log日志文件中,可以通过level参数设置只有大于等于该级别时才添加到日志文件;还可以通过rotation参数设置当文件大小(或者日期)超过多少时就不再往该文件存储,会自动生成新的日志文件存储。
使用rotation时,当超过指定的文件的大小时,会创建一个新的文件,将所有内容全部放到新文件,腾出指定的文件空间门,之后在存储日志还是往指定文件存储。
from loguru import logger
# 写入到文件
# logger.remove(handler_id=None)
# rotation 配置日志滚动记录的机制:rotation="200 MB"
logger.add("mylog.log",level='ERROR',rotation="200 MB")
# 基本使用,可以打印到console,也可以打印到文件中去。
logger.debug('这是一条测试日志')
logger.info('这是一条信息日志')
logger.success('这是一条成功日志')
logger.warning('这是一条警告日志')
logger.error('这是一条错误日志')
logger.critical('这是一条严重错误日志')
默认的输出格式是:时间、级别、模块、行号以及日志内容。
loguru的基本配置
import sys
from loguru import logger
logger.configure(handlers=[
{
"sink": sys.stderr, # 表示输出到终端
# 表示日志格式化
"format": "<g><b>{time:YYYY-MM-DD HH:mm:ss.SSS}</b></g> |<lvl>{level:8}</>| {name} : {module}:{line:4} | <c>mymodule</> | - <lvl>{message}</>",
"colorize": True, # 表示显示颜色。
"level": "WARNING" # 日志级别
},
{
"sink": 'first.log',
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |{level:8}| {name} : {module}:{line:4} | mymodule | - {message}",
"colorize": True
},
])
logger.debug('this is debug')
logger.info('this is info')
logger.warning('this is warning')
logger.error('this is error')
logger.critical('this is critical')
常见的key及其描述
| Key | Description |
|---|---|
| time | 发出日志调用时的可感知的本地时间 |
| level | 用于记录消息的严重程度 |
| name | 进行日志记录调用的__name__ |
| module | 进行日志记录调用的模块 |
| line | 源代码中的行号 |
| message | 记录的消息(尚未格式化) |
| function | 进行日志记录调用的函数 |
| thread | 进行日志记录调用的线程名 |
| process | 进行日志记录调用的进程名 |
| file | 进行日志记录调用的文件 |
| extra | 用户绑定的属性字典(参见bind()) |
| exception | 格式化异常(如果有),否则为’ None ’ |
| elapsed | 从程序开始经过的时间差 |
常用的颜色和样式标签
| 颜色(简称) | 样式(简称) |
|---|---|
| 黑色(k) | 粗体(b) |
| 蓝色(e) | 暗淡(d) |
| 青色(c) | 正常(n) |
| 绿色(g) | 斜体(i) |
| 洋红色(m) | 下划线(u) |
| 红色(r) | 删除线(s) |
| 白色(w) | 反转(v |
| 黄色(y) | 闪烁(l) |
Day10:模块与包
在Python中,模块(Module)是指一个包含了函数、变量和类等定义的文件,而包(Package)是指包含了多个模块的目录。类似于计算机文件和文件夹的管理数据方式,模块和包的概念是组织和管理Python代码的重要方式
1. 模块(Module)
【1】模块介绍
模块本质上就是一个py文件
模块一共有三种:
- python标准库
- 第三方模块
- 应用程序自定义模块
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。而这样的一个py文件在Python中称为模块(Module)。
模块是组织代码的更高级形式,大大提高了代码的阅读性和可维护性。
另外,使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。
【2】案例解析

单文件程序
main.py
def add(x, y):
return x + y
def sub(x, y):
return x - y
def mul(x, y):
return x * y
def div(x, y):
return x - y
def mysql_init():
print("mysql初始化")
def mysql_insert():
print("mysql添加记录")
def mysql_delete():
print("mysql删除记录")
def mysql_update():
print("mysql更改记录")
def mysql_query():
print("mysql查询记录")
while 1:
print("1. 科学计算")
print("2. 数据库操作")
choice = input("请选择:")
if choice == "1":
print(add(1, 2))
print(sub(1, 2))
print(mul(1, 2))
print(div(1, 2))
else:
mysql_init()
mysql_insert()
mysql_delete()
mysql_update()
mysql_query()
多模块程序:
cal.py
def add(x, y):
return x + y
def sub(x, y):
return x - y
def mul(x, y):
return x * y
def div(x, y):
return x - y
mysql.py
def mysql_init():
print("mysql初始化")
def mysql_insert():
print("mysql添加记录")
def mysql_delete():
print("mysql删除记录")
def mysql_update():
print("mysql更改记录")
def mysql_query():
print("mysql查询记录")
main.py
from cal import *
from mysql import *
while 1:
print("1. 科学计算")
print("2. 数据库操作")
choice = input("请选择:")
if choice == "1":
print(add(1, 2))
print(sub(1, 2))
print(mul(1, 2))
print(div(1, 2))
else:
mysql_init()
mysql_insert()
mysql_delete()
mysql_update()
mysql_query()
【3】导入模块语法
模块导入的关键点:
- 命名:小写字母+下划线
- 导入的模块都是一等公民
- 导入模块的本质:在内存中加载并运行该模块,将整个模块内容赋值给与该模块名同名的变量
- 不管导入几次,只运行一次
- __pycache__文件夹:Python 为每个模块都生成一个 *.cpython-36.pyc 文件,该文件其实是 Python 为模块编译生成的字节码,用于提升该模块的运行效率
这节课讲了模块的名称空间:就是各自独立的空间,通过.可以获取和修改空间内的变量,当然一个模块也可以作为某个被导入模块的子模块,此时如果还重复导入该模块,就不会重复执行但是会将新的变量名执行旧的变量名,共享一块空间
(1)导入模块关键点
-
模块与包的命名遵从小写+下划线
-
导入的模块名和函数一样是一等公民。
在编程语言中,“一等公民”(first-class citizen)是指某个实体(通常是数据类型或值)具有与其他实体相同的权利和特权。它表示在语言中,这些实体可以被像任何其他实体一样对待,可以作为参数传递给函数、赋值给变量、存储在数据结构中,以及作为函数的返回值。
-
使用“import module”导入模块的本质就是,将 module.py 中的全部代码加载到内存并执行,然后将整个模块内容赋值给与模块同名的变量。
-
导入同一个模块多次,Python只执行一次。
-
在导入模块后,可以在模块文件所在目录下看到一个名为“pycache”的文件夹,打开该文件夹,可以看到 Python 为每个模块都生成一个 *.cpython-36.pyc 文件,该文件其实是 Python 为模块编译生成的字节码,用于提升该模块的运行效率。
(2)导入模块语法
import 有很多用法,主要有以下两种:
import 模块名1 [as 别名1], 模块名2 [as 别名2],…:使用这种语法格式的 import 语句,会导入指定模块中的所有成员(包括变量、函数、类等)。不仅如此,当需要使用模块中的成员时,需用该模块名(或别名)作为前缀,否则 Python 解释器会报错。from 模块名 import 成员名1 [as 别名1],成员名2 [as 别名2],…: 使用这种语法格式的 import 语句,只会导入模块中指定的成员,而不是全部成员。同时,当程序中使用该成员时,无需附加任何前缀,直接使用成员名(或别名)即可。
注意,
- import 语句也可以导入指定模块中的所有成员,即使用 form 模块名 import *,但此方式不推荐使用。
__all__可以控制*
from cal import add as new_add, sub, mul, div
import cal
from cal import *
print(new_add(1, 2))
print(cal.add(1, 2))
【4】 __name__=='__main__'
这节课讲了__name__在作为运行模块时:值永远为__main__;在作为到导入模块时:值为文件名的字符串。所以我们可以定义自己的模块时if __name__ == __main__来测试这个单独模块的代码
def mysql_init():
print("mysql初始化")
def mysql_insert():
print("mysql添加记录")
def mysql_delete():
print("mysql删除记录")
def mysql_update():
print("mysql更改记录")
def mysql_query():
print("mysql查询记录")
if __name__ == "__main__":
print(__name__)
mysql_query()
mysql_insert()
mysql_delete()
mysql_update()
可以看到,当前运行的程序,其 __name__ 的值为 __main__,而导入到当前程序中的模块,其 __name__ 值为自己的模块名。
因此,if __name__ == '__main__': 的作用是确保只有单独运行该模块时,此表达式才成立,才可以进入此判断语法,执行其中的测试代码;反之,如果只是作为模块导入到其他程序文件中,则此表达式将不成立,运行其它程序时,也就不会执行该判断语句中的测试代码。
【5】循环导入的bug
这节课讲了循环导模块的bug,
首先两个模块互相导入并不是循环导入,因为模块的导入只导入一次所以不是,只有在特定情况下才会出现循环导入。
循环导模块是因为在两个模块在代码最初都要单独导入一个对方目前都没有的一个变量。解决方法:可以将导包语句放在变量被创建之后
# m1.py
from m1 import x
y = 1000
# m2.py
from m2 import y
x = 100
2. 包
用来组织模块的,相当于文件夹
【1】包介绍
实际开发中,一个大型的项目往往需要使用成百上千的Python模块,如果将这些模块都堆放在一起,势必不好管理。而且,使用模块可以有效避免变量名或函数名重名引发的冲突,但是如果模块名重复怎么办呢?因此,Python提出了包(Package)的概念。
什么是包呢?简单理解,包就是文件夹,只不过在该文件夹下必须存在一个名为“__init__.py” 的文件,其作用就是告诉 Python 要将该目录当成包来处理
注意,这是 Python 2.x 的规定,而在 Python 3.x 中,
__init__.py对包来说,并不是必须的。
包的主要作用是组织和管理模块,使得代码更加结构化和可维护。包的层次结构可以是多层的,即可以包含子包(子目录)和子模块。
【2】创建包
包其实就是文件夹,更确切的说,是一个包含“__init__.py”文件的文件夹。因此,如果我们想手动创建一个包,只需进行以下 2 步操作:
- 新建一个文件夹,文件夹的名称就是新建包的包名;
- 在该文件夹中,创建一个
__init__.py文件(前后各有 2 个下划线‘_’),该文件中可以不编写任何代码。当然,也可以编写一些 Python 初始化代码,则当有其它程序文件导入包时,会自动执行该文件中的代码
创建好包之后,我们就可以向包中添加模块(也可以添加包)。
【3】案例解析
├── pycache
├── db
│ ├── __init__.py
│ ├── pycache
│ │ ├── init.cpython-312.pyc
│ │ └── mysql.cpython-312.pyc
│ ├── mysql.py
│ ├── postgre.py
│ └── redis.py
├── main.py
└── utils
├── __init__.py
├── pycache
│ ├── init.cpython-312.pyc
│ └── cal.cpython-312.pyc
└── cal.py
from utils.cal import *
from db.mysql import *
【4】导包语法
通过前面的学习我们知道,包其实本质上还是模块,因此导入模块的语法同样也适用于导入包。无论导入我们自定义的包,还是导入从他处下载的第三方包,导入方法可归结为以下 3 种:
import 包名[.模块名 [as 别名]]from 包名1.包名2 import 模块名 [as 别名]from 包名1.包名2.模块名 import 成员名 [as 别名]
用 [] 括起来的部分,是可选部分,即可以使用,也可以直接忽略。
【5】导入模块和包本质
导入模块与导入包的本质:在一个项目中,任何模块导入都是从该项目的主函数执行文件所在的目录开始的
在sys.path列表变量中:sys.path的第一个值永远是主函数执行文件所在的目录的路径
如果要修改sys.path列表的第一个路径值:可以通过BASE_URL=os.path.dirname(os.path.abspath(__file__))这样的方式拿到想要的路径,再通过sys.path.insert(0,BASE_URL)的方式修改
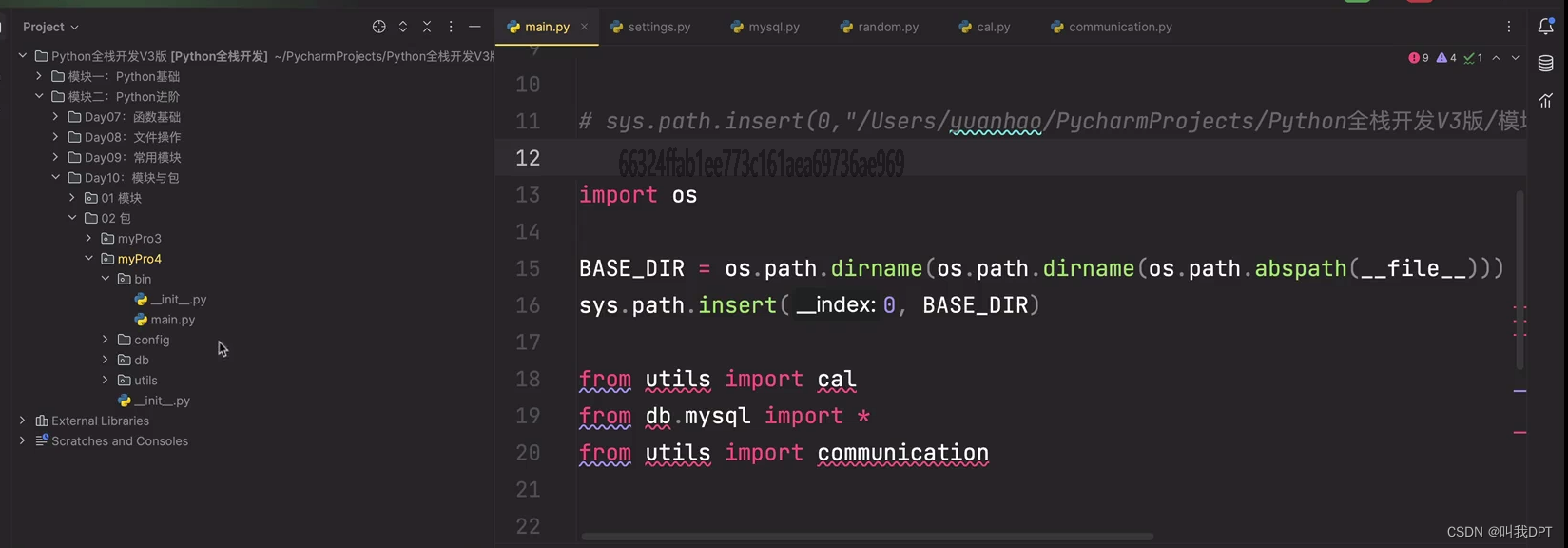
通常情况下,当使用 import 语句导入模块后,Python 会按照以下顺序查找指定的模块文件:
- 在当前目录,即当前执行的程序文件所在目录下查找;
- 到 PYTHONPATH(环境变量)下的每个目录中查找;
- 到 Python 默认的安装目录下查找。
以上所有涉及到的目录,都保存在标准模块 sys 的 sys.path 变量中,通过此变量我们可以看到指定程序文件支持查找的所有目录。换句话说,如果要导入的模块没有存储在 sys.path 显示的目录中,那么导入该模块并运行程序时,Python 解释器就会抛出 ModuleNotFoundError(未找到模块)异常。
解决“Python找不到指定模块”的方法有 3 种,分别是:
- 向 sys.path 中临时添加模块文件存储位置的完整路径;
- 将模块放在 sys.path 变量中已包含的模块加载路径中;
- 设置 path 系统环境变量。
功能模块导入功能 模块,import
【6】__init__.py
前面章节中,已经对包的创建和导入进行了详细讲解,并提供了大量的实例,这些实例虽然可以正常运行,但存在一个通病,即为了调用包内模块的成员(变量、函数或者类),代码中包含了诸多的 import 导入语句,非常繁琐。
通过在 __init__.py 文件使用 import 语句将必要的模块导入,这样当向其他程序中导入此包时,就可以直接导入包名,也就是使用import 包名(或from 包名 import *)的形式即可。
mysql包中的__init__.py
# 案例1
from . import mysql
# 案例2
from .mysql import mysql_init, mysql_insert
mysql_init()
main.py
# 案例1
import db
db.mysql.mysql_insert()
# 案例2
import db
db.mysql_insert()
3. 虚拟环境
【1】pip命令
进行 Python 程序开发时,除了使用 Python 内置的标准模块以及我们自定义的模块之外,还有很多第三方模块可以使用,
使用第三方模块之前,需要先下载并安装该模块,然后就能像使用标准模块和自定义模块那样导入并使用了。因此,本节主要讲解如何下载并安装第三方模块。
下载和安装第三方模块,可以使用 Python 提供的 pip 命令实现。pip 命令的语法格式如下:
pip install|uninstall|list 模块名
其中,install、uninstall、list 是常用的命令参数,各自的含义为:
- install:用于安装第三方模块,当 pip 使用 install 作为参数时,后面的模块名不能省略。
- uninstall:用于卸载已经安装的第三方模块,选择 uninstall 作为参数时,后面的模块名也不能省略。
- list:用于显示已经安装的第三方模块。
【2】虚拟环境命令
虚拟环境(Virtual Environment)是 Python 中用于隔离项目依赖和运行环境的工具。它允许你在同一台计算机上同时管理多个项目,每个项目都有自己独立的 Python 解释器和第三方库,互相之间不会相互干扰。
使用虚拟环境的好处包括:
- 隔离依赖:每个项目可以有自己的依赖库,不同项目之间的依赖冲突不会发生。
- 简化部署:可以将项目的依赖库和运行环境一起打包,方便在其他计算机上部署和运行。
- 灵活性:可以在不同的项目中使用不同的 Python 版本,以满足项目的特定需求。
在 Python 3.3 及以后的版本中,Python 内置了 venv 模块,用于创建和管理虚拟环境。以下是使用 venv 模块创建和激活虚拟环境的基本步骤:
- 创建虚拟环境:
打开终端(命令行),进入你想要创建虚拟环境的目录,然后运行以下命令:
# 这是 Python 内置的 venv 模块的命令语法。
# 它通过调用 Python 解释器的 -m 参数来执行 venv 模块内建的创建虚拟环境的功能。
python3 -m venv <env_name>
-
激活虚拟环境:
在终端中运行以下命令来激活虚拟环境:# 在 macOS/Linux 系统上: source myenv/bin/activate # 在 Windows 系统上: myenv\Scripts\activate
激活虚拟环境后,终端的提示符会显示虚拟环境的名称。
-
使用虚拟环境:
在激活的虚拟环境中,你可以安装和管理项目所需的依赖库,运行项目的代码等。所有的操作都将在虚拟环境中进行,不会影响全局 Python 环境和其他虚拟环境。 -
退出虚拟环境:
在终端中运行以下命令即可退出虚拟环境:deactivate -
导出和导入依赖:
# 导出依赖到文件 pip freeze > requirements.txt # 从文件中导入依赖: pip install -r requirements.txt
4. 软件目录开发规范
在软件开发中,一个良好的目录结构可以提高代码的可维护性和可扩展性,使团队成员更容易理解和协作。尽管目录结构可以因项目类型和团队偏好而异,但以下是一些常见的软件开发目录规范和最佳实践:
- 项目根目录:在项目的根目录下,应包含与项目相关的文件和文件夹,如README、LICENSE等。这是整个项目的起点。
- 源代码目录:通常将源代码放在一个独立的目录中。这个目录应该有一个具有描述性的名称,如src、lib或app。在源代码目录下,可以按照项目的模块、功能或层次结构创建子目录。
- 测试目录:测试代码通常位于一个独立的目录中。可以使用名称如tests、test或spec的目录来存放单元测试、集成测试和其他测试相关的文件。
- 文档目录:为了方便团队成员和用户了解项目和代码的使用方式,可以创建一个文档目录,其中包含项目文档、API文档、用户手册等。
- 配置目录:存放项目的配置文件,如数据库配置、日志配置、环境变量配置等。可以将这些配置文件放在一个名为config或conf的目录下。
- 资源目录:存放项目所需的资源文件,如图像、样式表、静态文件等。可以将这些资源文件放在一个名为assets或resources的目录下。
- 日志目录:存放项目的日志文件,包括运行日志、错误日志等。可以将这些日志文件放在一个名为logs的目录下。
- 其他目录:根据项目的具体需求,可以创建其他目录来存放特定类型的文件,如缓存目录、备份目录等。
在设计目录结构时,要考虑项目的规模、复杂性和团队的需求。重要的是要保持一致性,并与团队成员共享并遵循相同的目录规范,以便于项目维护和协作。
以下是一个常见的目录规范示例,可以作为参考:
project/
├── docs/ # 文档目录
│ ├── requirements/ # 需求文档
│ ├── design/ # 设计文档
│ └── api/ # API 文档
├── # 源代码目录
│ ├── app/ # 应用代码
│ │ ├── models/ # 模型定义
│ │ ├── views/ # 视图逻辑
│ │ ├── controllers/ # 控制器逻辑
│ │ └── utils/ # 工具函数
│ ├── config/ # 配置文件
│ ├── tests/ # 测试代码
│ └── scripts/ # 脚本文件
├── static/ # 静态资源目录
│ ├── css/ # 样式文件
│ ├── js/ # JavaScript 文件
│ ├── images/ # 图片文件
│ └── fonts/ # 字体文件
├── templates/ # 模板文件目录
├── data/ # 数据文件目录
├── logs/ # 日志文件目录
├── dist/ # 分发版本目录
├── run.py # 用于启动应用程序或执行相关操作的文件。
├── vendor/ # 第三方依赖目录
├── requirements.txt # 依赖包列表
├── README.md # 项目说明文档
└── LICENSE # 许可证文件
上述示例中,主要包含以下目录:
docs/:用于存放项目的文档,包括需求文档、设计文档和API文档等。src/:存放项目的源代码,按照模块进行组织,例如app/目录下存放应用代码,config/目录下存放配置文件,tests/目录下存放测试代码等。static/:存放静态资源文件,例如CSS样式文件、JavaScript文件、图片文件和字体文件等。templates/:存放模板文件,用于生成动态内容的页面。data/:存放数据文件,例如数据库文件或其他数据存储文件。logs/:存放日志文件,记录项目的运行日志。dist/:存放项目的分发版本,例如编译后的可执行文件或打包后的软件包。vendor/:存放第三方依赖,例如外部库或框架。requirements.txt:列出项目所需的依赖包及其版本信息。README.md:项目说明文档,包含项目的介绍、使用指南和其他相关信息。LICENSE:许可证文件,定义项目的使用和分发条款。
5. 客户关系管理系统【多目录版】
将客户关系管理系统项目改版为多目录版本,包括数据库文件,日志文件,配置文件等
目录设计:
myapp/
├── logs/
│ └── customers.log
├── conf/
│ └── settings.py
├── db/
│ └── customers.json
├── src/
│ ├── __init__.py
│ ├── customer.py
│ ├── data_access.py
│ └── main.py
└── run.py
第二章总结&模块作业
1. 总结
- 理解函数的概念,能够定义和调用函数,并了解函数的参数和返回值的使用。
- 熟悉常用的内置函数,如
map、sorted、sum等,并能够正确使用它们。 - 熟悉函数的参数传递方式,包括位置参数、关键字参数和默认参数,并能够正确传递参数。
- 能够使用函数进行模块化编程,将代码划分为逻辑单元,提高代码的可读性和重用性。
- 理解和使用文件操作相关的函数和方法,如打开文件、读取和写入文件内容等。
- 熟悉常用的文件操作模式,如读取模式(‘r’)、写入模式(‘w’)、追加模式(‘a’)等,并能够正确选择和使用模式。
- 熟悉如何利用文件操作下载各类文件,包括图片,视频等。
- 掌握好常用模块,如json模块,日志模块,os模块等,分别可以完成序列化,日志记录以及文件和文件夹操作等。
- 理解模块和包的概念,能够导入和使用模块,并了解模块的搜索路径和命名空间的概念。
- 能够编写简单的模块和包,将代码组织成可复用的模块,并能够正确导入和使用模块和包。
若有错误与不足请指出,关注DPT一起进步吧!!!
















 1029
1029

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











