






Lstm预测上证指数
实验1:
参数:
class HyperParameters:
input_size = 1
hidden_size = 128
output_size = 1
num_layers = 1
batch_size = 16
dropout = 0.1
num_epochs = 100
learning_rate = 0.001
time_step = 20
test_size = 0.2
train_x = 'data/00001/train_x.pt'
train_y = 'data/00001/train_y.pt'
test_x = 'data/00001/test_x.pt'
test_y = 'data/00001/test_y.pt'
# model_path = 'model/model.pkl'
device = 'cuda' if torch.cuda.is_available() else 'cpu'
LSTM(
(lstm): LSTM(1, 64, num_layers=2, batch_first=True)
(fc): Sequential(
(0): Tanh()
(1): Linear(in_features=64, out_features=64, bias=True)
(2): Tanh()
(3): Linear(in_features=64, out_features=1, bias=True)
)
)
进程已结束,退出代码0
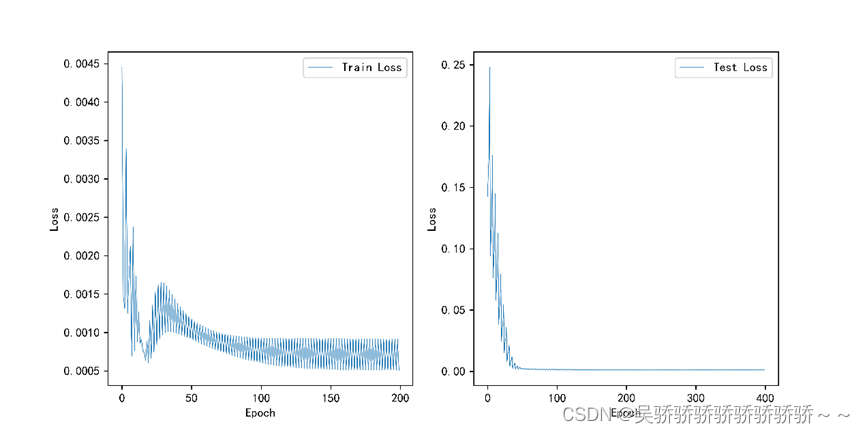
loss:
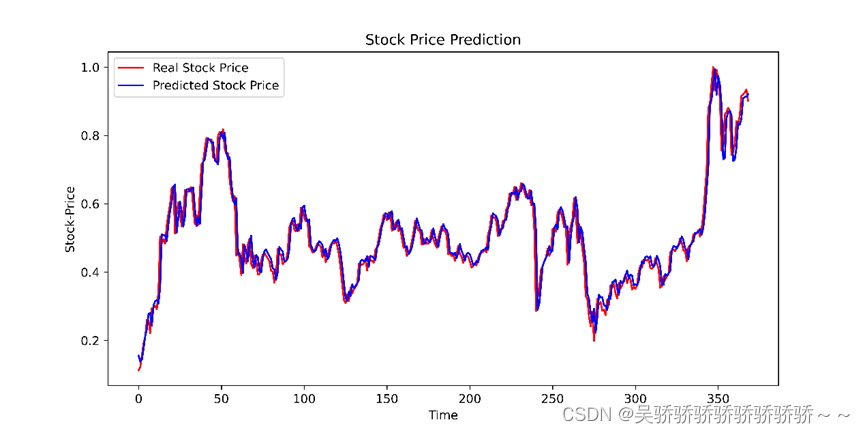
训练集预测结果:
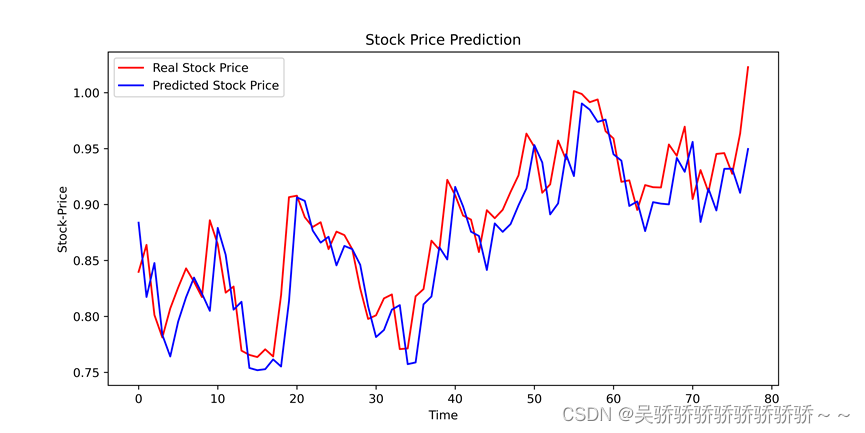
测试集预测结果:
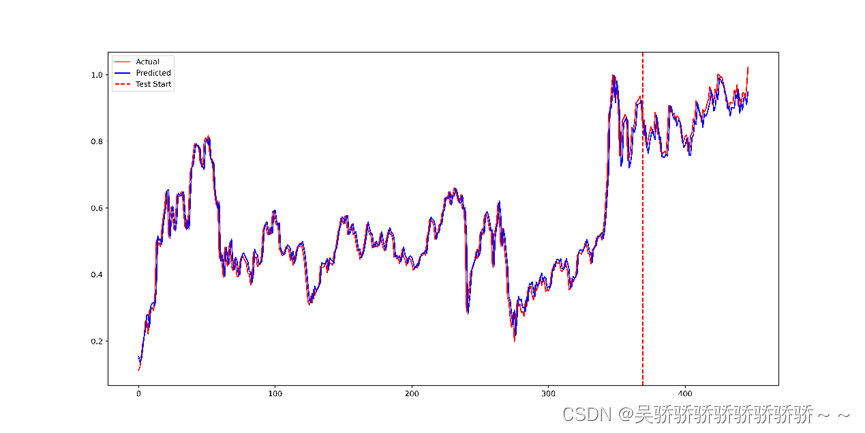















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









