







好恭喜各位找到一篇宝藏博文。
本系列篇解释RNN和LSTM的参数详解和训练过程,说的较为详细。
这一篇1.0先写原理和参数解释。理解RNN的结构,注意结合参数理解时间序列展开,空间序列展开。
一、从MLP和CNN引起
总的来说,全连接神经网络或者说MLP的训练和结构是好理解的。一个一维长度为n的输入,中间过几个全连接层,都是一维若干的长度,输出为几分类就是多少维的向量,节点到节点的参数构成weight矩阵,隐藏层每个节点又有bias值,这就是一个全连接网络的参数。训练就是想得出这weight矩阵和Bias值,利用后向传播算法得出。这就是MLP训练的本质,一堆矩阵乘法和加法,当然有激活函数可以实现非线性变换。这一块不懂可以去看MLP训练。
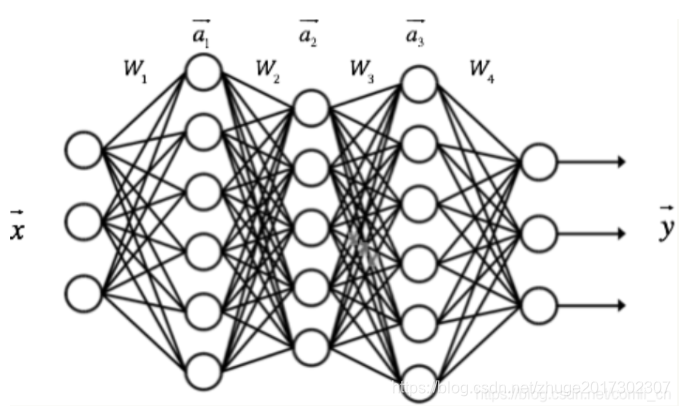
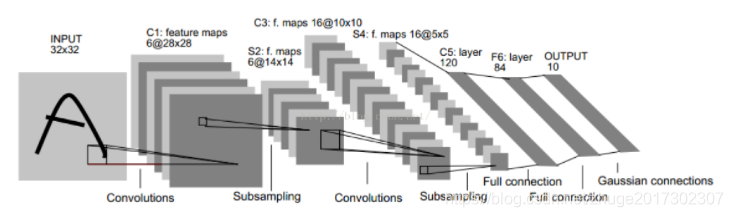
接下来到了CNN,CNN跟MLP不同,但还是很简单,卷积核跟原图的一小部分区域做矩阵乘法,结果新图的一个值代表原图的一小块区域,这就实现了提取特征,然后在原图上不断移动,直到把整个原图按规定的步长stride移动完毕,特征也就提取完毕。当然此时有若干个卷积核,可以把同一个原图提取成若干个小图。接下来一般过池化层进行再压缩,最后转换成一维向量,作为紧跟在后面的全连接层的输入最后分类。参数就是卷积核的参数,比如卷积核是5*5,那么一个卷积核就有5*5个参数要求,因为卷积核很多,所以很多个5*5的参数。而且一般后面连全连接层,也有如上的参数要求。
二、RNN和LSTM的训练模式
先来看两个图:
下图是LRNN训练图:

下图是LSTM训练图:
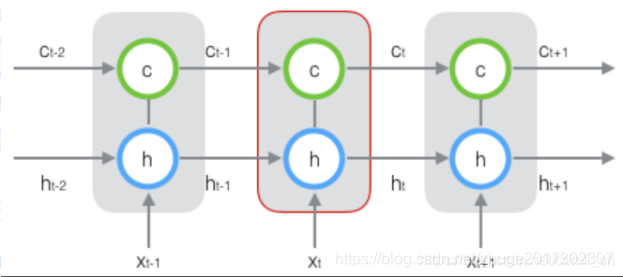
我自学的时候一直看见这两个图,也逐渐看懂了这两图啥意思,但讲道理,没有真懂。
其实上图是RNN和LSTM按时间序列展开的效果图,即在时间节点上展开,比如上面两个图貌似有三层,但其实是一层,只是在t-1,t,t+1时刻,将同一个东西连了起来。
其实上面这个东西如果你是按空间序列展开,那就说明你有三个LSTM(RNN)层,懂了吧。强调,如果按空间序列展开,但其实上图是按时间序列展开,它只有一层。
在这里小小的提一下cell的概念。当你是按时间序列展开,你就有若干个cell。因为cell是同一个RNN(也是LSTM,以下省略)单元,但同一个单元的不同时间,它的状态是不同的,也就成为不同的cell。因为你一层RNN是只有一个的,但上面连起来了,好像有三个,但它们是时间序列展开,其实是同一个RNN单元在不同时间的状态,即cell。
那么我们再来看下图。
下图将LSTM与全连接神经网络做了对比。
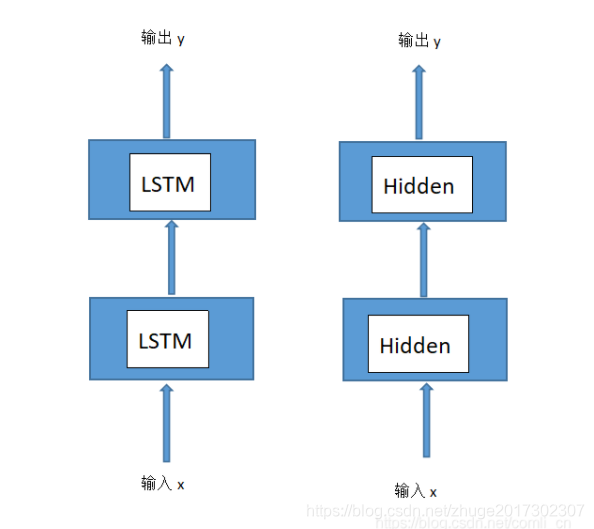
这样就可以看到,其实LSTM跟MLP是一模一样的。一个LSTM层对应一个MLP层。
那么顺便解释以下隐藏层节点个数。LSTM层是有隐藏层节点个数的,可能是128,64之类你随意设置的数字,这不跟MLP隐藏层节点个数一样的吗?所以你看本质上都是求矩阵乘法和加法,求的是weight矩阵和节点代表的bias值。
但为什么LSTM有时间上的展开序列呢?这就是问题的本质了。显然MLP没有时间上展开序列一说,因为就是单纯的输入一个数据,然后过几个隐藏层,然后输出就行,一次训练代表一个数据一个隐藏层过一遍即可。但是一个LSTM层可不是过一遍,显然一次训练,一个输入输进去,要在一个LSTM层上过好几遍才输出,这导致它有了时间序列上的展开。为什么过好几遍呢?两个方面来说,首先这是由LSTM本身的功能和结构决定的,人家就是求时间序列数据,找规律的;其次,LSTM也有这个参数,导致它的输入要经过好几个时间步才输出,这个参数是seq_len,参数后面解释。
总的来说,RNN和MLP其实是一样的,就像上图的空间展开序列,大家都是一层对一层,RNN隐藏层节点数也等价于MLP隐藏层节点数,没有什么差别。只是因为二者性质和功能不一样,导致RNN有时间序列上的结构展开,看起来好像凶一点,其实并没有。它们的本质都是输入向量,做矩阵乘法和加法,然后变换到输出,乘法和加法所需的矩阵和节点的值就是要求的参数。
三、RNN和LSTM参数解释
大家先别急着看下篇的训练过程,先看一下参数解释,能更好的帮你理解训练过程。当然可以跟训练过程结合起来看,只看参数解释也可能看不懂的。
1、参数集合
首先集中解释,具体见下面实例。
(1)batch:把数据分为多少批,一批更新一次参数。
(2)batch_size:每批有多少个序列或称有多少组数据。注意是多少组数据,因为RNN的一个输入是一个序列,是由若干个数据组成的。比如(batch=5,seq_len=3,batch_size=2),表示有5批数据,每批有2个输入序列,每个序列长度为3即由3个数据组成。
(3)seq_len:输入序列长度。决定了RNN按时间序列展开有多长(或有多少个cell)。等价于time_step。
(4)num_layers:RNN的层数。设置了多少个RNN层,空间序列上展开或者物理展开有多少个RNN层。
(5)input_size:每个数据的属性向量的长度。官方文档的解释为:输入X的特征数目。严格来说是每个时间步的特征数量。这说的很别扭。三个看着好像有差别,其实没有。在每个batch里,有batch_size个序列,每个序列的长度决定了循环多少次,即决定了时间步数,每个时间步数上有一个输入x,这个x的长度就是Input_size。这是等价于,单纯的每个输入是多长的向量,就是输入数据的特征向量的长度。
(6)hidden_size:隐藏层神经元的个数。对应于MLP隐藏层神经元的个数,即这一个RNN层内部有多少个节点,决定了参数值有多少。
(7)time_step:时间步长,即循环的次数,即输入的数据序列。等价于seq_len,即输入的数据序列有多长,由多少个数据组成,决定了一个RNN要经过几次循环,也决定了RNN的时间展开有多少个cell。
2、参数实例
(1)当你用pytorch调用LSTM实现:rnn = torch.nn.LSTM(input_size,hidden_size,num_layers)
——input_size:输入向量的维度;
——hidden_size:隐藏层神经元的个数,对应于MLP隐藏层神经元的个数;
——num_layers:循环层的数量,即有几个LSTM层;
(2)当你生成RNN的输入数据:input = torch.randn(seq_len, batch, input_size)
——seq_len:序列长度。表示每个小batch需要几个时间步进行处理;
——batch:将输入数据划成了多少组,即多少个batch。(即数据批量化。这里是指每训练完一批之后更新一次参数,如果不把数据分成一批一批更新数据而是一个一个更新的话运算量太大,时间太长,如果整个计算完再更新参数的话最终误差会比较大)
——input_size:输入向量的维度。
以input = torch.randn(5, 3, 10)为例,第二个参数3训练数据划分成3个batch,即3批,每训练一批更新一次参数。比如共有1500个训练数据,那么每500个训练数据为一个batch,训练完500个更新一次参数。下批数据训练时,网络的初始状态就是更新后的状态,不是第一次的初始状态。第一个参数5为seq_len,代表每个batch需要几个时间步进行处理,可以看出来它意为序列长度。MLP的输入是一次输入一个数据x进去,这个数据x一般是一维向量。但RNN的输入虽然也是输入数据,但是是输入一个序列,这个序列由若干个单独的数据x组成,这个序列长度为5,说明它有x1到x5,分别作为t1到t5的输入,这导致这个RNN层在时间序列上展开会有5个cell。
(3)如果要输入的数据是一维数据,则input_size为1,因为是一维数据,且长度为1。
例如:我们有原始数据data = 1,2,3,4,5,6,7,8,9,10 一共10个sample,接下来要将这些数据放进LSTM中进行处理,在处理之前我们需要对数据的形式进行变换,首先我们设定seq_len是3,则此时的数据形式为:
1-2-3,2-3-4,3-4-5,4-5-6,5-6-7,6-7-8,7-8-9,8-9-10,9-10-0,10-0-0(最后两个数据不完整,进行补零)
我们设定batch_size为2,则每个batch有两组数据,当然每组数据长度为3(seq_len),则我们取出的第一个batch为1-2-3,2-3-4,这个batch的数据就为(2,3,1)。
接下来第二个batch为3-4-5,4-5-6;第三个batch为5-6-7,6-7-8;第四个batch为7-8-9,8-9-10;第五个batch为9-10-0,10-0-0。我们的数据一共生成了5个batch。
(4)当要输入的数据为二维,input_size表示每个数据的属性向量的长度。
例如,
data_ = [[1, 10, 11, 15, 9, 100],
[2, 11, 12, 16, 9, 100],
[3, 12, 13, 17, 9, 100],
[4, 13, 14, 18, 9, 100],
[5, 14, 15, 19, 9, 100],
[6, 15, 16, 10, 9, 100],
[7, 15, 16, 10, 9, 100],
[8, 15, 16, 10, 9, 100],
[9, 15, 16, 10, 9, 100],
[10, 15, 16, 10, 9, 100]]seq_len=3,batch=2,input_size=6。这时我们
第一个batch:
tensor([[[ 1., 10., 11., 15., 9., 100.],
[ 2., 11., 12., 16., 9., 100.],
[ 3., 12., 13., 17., 9., 100.]],
[[ 2., 11., 12., 16., 9., 100.],
[ 3., 12., 13., 17., 9., 100.],
[ 4., 13., 14., 18., 9., 100.]]])
第二个batch:
tensor([[[ 9., 15., 16., 10., 9., 100.],
[ 10., 15., 16., 10., 9., 100.],
[ 0., 0., 0., 0., 0., 0.]],
[[ 10., 15., 16., 10., 9., 100.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.]]])

















 1438
1438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









