






 本文介绍了Python中字符串的基本操作,如大小写转换、分隔、查找、替换、格式化字符串、字符编码解码、数据验证、字符串处理以及正则表达式的使用方法,包括match、search和sub函数的应用。
本文介绍了Python中字符串的基本操作,如大小写转换、分隔、查找、替换、格式化字符串、字符编码解码、数据验证、字符串处理以及正则表达式的使用方法,包括match、search和sub函数的应用。
字符串不可变
1.常用操作
# 大小写转换
s1 = 'HelloWorld'
print('s1:', s1)
s2 = s1.lower()
print('s2:', s2)
s3 = s2.upper()
print('s3:', s3)
print()
# 字符串分隔
e_mail = 'lmao@126.com'
lst = e_mail.split('@')
print('邮箱名:', lst[0], '邮件服务器域名:', lst[1])
print()
# find count index
print(s1.count('o'))
print(s1.find('o'))
print(s1.find('x'))
print(s1.index('o'))
# 若index()的没有 则报错
print()
# 判断前缀后缀
print('danm.py'.endswith('.py'))
print(s1.startswith('H'))
print(s1.startswith('j'))
print()
# 替换 占位
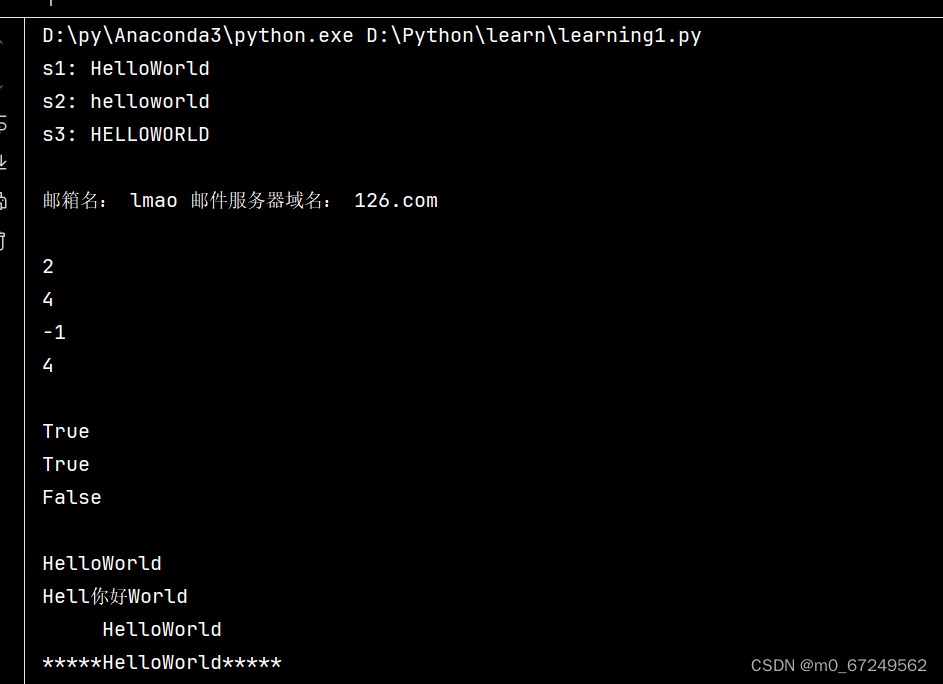
print(s1)
new_s = s1.replace('o', '你好', 1)
print(new_s)
print(s1.center(20))
print(s1.center(20, '*'))
print()
# 去掉空格,指定字符
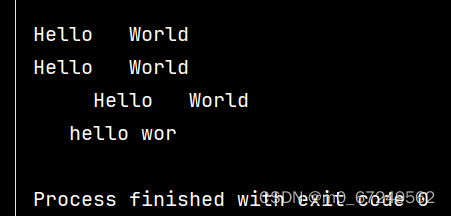
ss = ' Hello World '
print(ss.strip())
print(ss.lstrip())
print(ss.rstrip())
s5 = ' hello world' # 后面不能有空格,但与顺序无关
print(s5.strip('dl'))
2.格式化字符串
# 格式化字符串
name = '小丽'
age = 3
score = 99.5
print('姓名:%s 年龄:%d 成绩:%.2f' % (name, age, score))
print(f'姓名:{name} 年龄:{age} 成绩:{score}')
print('姓名:{0} 年龄:{1} 成绩:{2}'.format(name, age, score))
print()
s = 'helloworld'
print('{0:*>20}'.format(s))
# 显示宽度20,右对齐,空白部分*填充
print('{0:*^20}'.format(s))
print(s.center(20,'*'))
print()
# 千位分隔符 只用于整数和浮点数
print('{0:,}'.format(123456789))
print('{0:,}'.format(123456789.3456))
# 小数精度
print('{0:.2f}'.format(3.1415926535))
# 字符串类型,显示长度
print('{0:.5}'.format('helloworld'))
# 进制转换
a = 423
print('二进制:{0:b} 十进制:{0:d} 八进制{0:o} 十六进制{0:x}'.format(a))
# 浮点数
b = 3.1415926
print('{0:.2f} {0:.2E} {0:.2e} {0:.2%}'.format(b))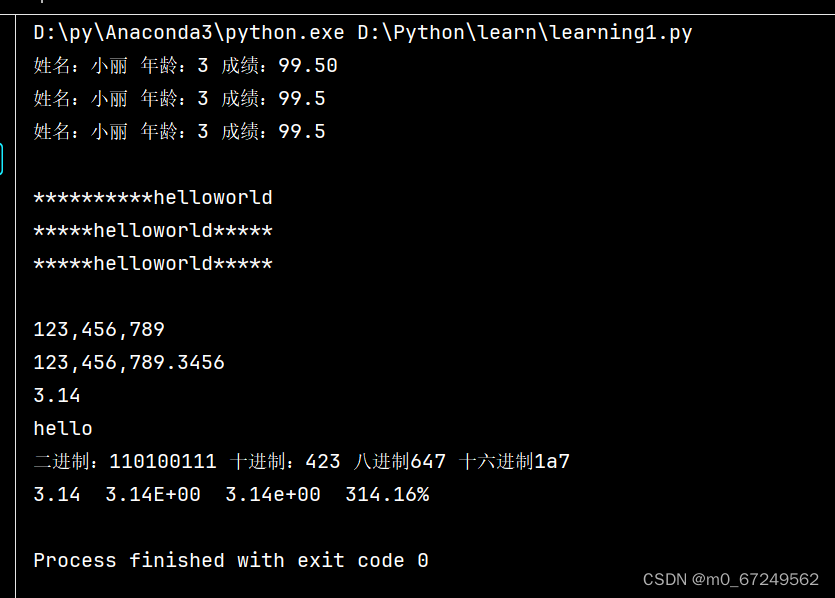

3.字符编码解码

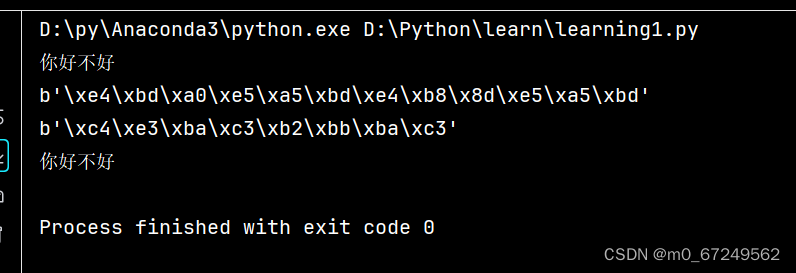
s = '你好不好'
print(s)
scode = s.encode(errors='replace')
print(scode)
# utf——8中文占三个字节
scode_gbk=s.encode('gbk',errors='replace')
print(scode_gbk)
# gbk中文占两字符
#解码
print(bytes.decode(scode_gbk,'gbk'))
4.数据的验证
print('123'.isdigit()) # True
print('一二三'.isdigit()) # False
print()
print('123'.isnumeric()) # True
print('壹贰叁'.isnumeric()) # True
print('0b1010'.isnumeric()) # False
print()
print('hello你好'.isalpha()) # True
print('hello你好一二三'.isalpha()) # True
print('hello你好123'.isalpha()) # False
print()
print('hello你好'.isalnum()) # True
print('hello123'.isalnum()) # True
print()
print('helloWorld'.islower()) # False
print('hello你好'.islower()) # True
print('HELLO你好'.isupper()) # True
print()
print('Hello'.istitle()) # True
print('HelloWorld'.istitle()) # False
print()
print('\t'.isspace()) # True
print(' '.isspace()) # True5.字符串的处理
s1 = 'hello'
s2 = 'world'
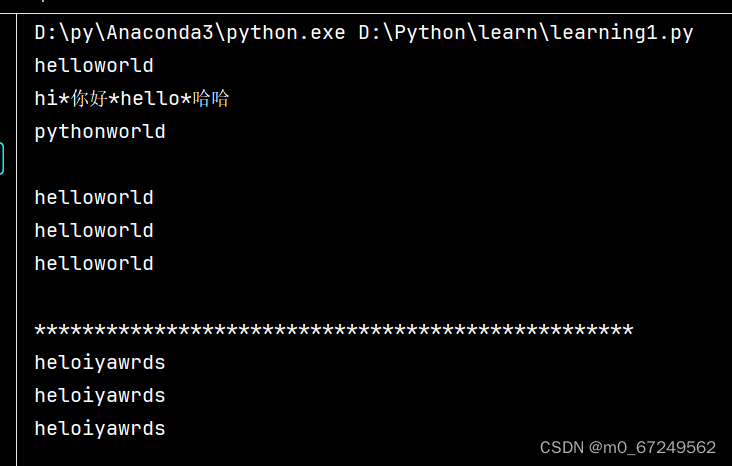
print(''.join([s1, s2]))
print('*'.join(['hi', '你好', 'hello', '哈哈']))
print('python''world')
print()
# 格式化
print('%s%s' % (s1, s2))
print(f'{s1}{s2}')
print('{0}{1}'.format(s1, s2))
print()
print('*'*50)
# 去重
s = 'hellohiyahyahelloworldwowohellohheilso'
new_s=''
for item in s:
if item not in new_s:
new_s += item
print(new_s)
new_s2 = ''
for i in range(len(s)):
if s[i] not in new_s2:
new_s2+=s[i]
print(new_s2)
# 集合去重+列表排序
new_s3 = set(s)
lst = list(new_s3)
lst.sort(key=s.index) # 按原来顺序排好
print(''.join(lst))
6.正则表达式
import re
pattern = '\d\.\d+' # 限定符 \d 0-9出现一次或多次
# match 函数
s = 'I study Python 3.12 every day' # 待匹配字符串
match = re.match(pattern, s, re.I) #不区分大小写
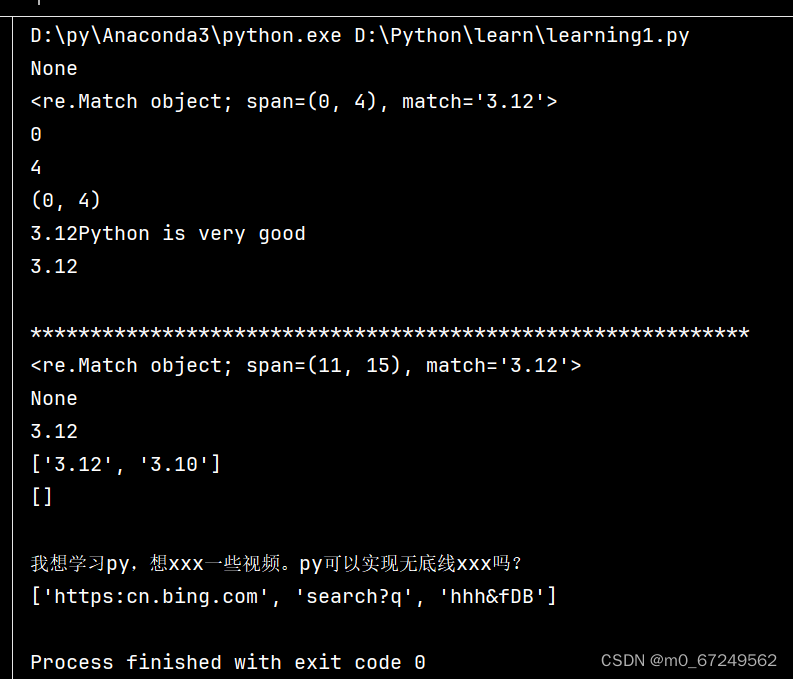
print(match)
s2 = '3.12Python is very good'
match2 = re.match(pattern, s2)
print(match2)
print(match2.start())
print(match2.end())
print(match2.span()) # 匹配区间的位置元素
print(match2.string) # 待匹配的字符串
print(match2.group()) # 匹配的数据
print()
print('*'*60)
# search() findall()
s21 = 'I study py 3.12 and 3.10 everyday'
match3 = re.search(pattern, s21) # 只找第一个
print(match3)
s22 = 'I study py haha'
match4 = re.search(pattern, s22)
print(match4)
print(match3.group())
# findall()以列表形式输出
lst = re.findall(pattern, s21)
lst2 = re.findall(pattern, s22)
print(lst)
print(lst2)
print()
# sub()
pattern2 ='黑客|破解|反爬'
s31 = '我想学习py,想破解一些视频。py可以实现无底线反爬吗?'
new_s31 = re.sub(pattern2, 'xxx', s31)
print(new_s31)
pattern3 = '[/|=]'
s32 = 'https:cn.bing.com/search?q=hhh&fDB'
lst = re.split(pattern3, s32) # split()输出为列表
print(lst)















 2084
2084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









