







1,数据介绍,字段了解
尽可能熟悉业务,多知道字段的含义,字段字段间的逻辑关系,后期数据分析思路才能更清晰,结果才能更准确
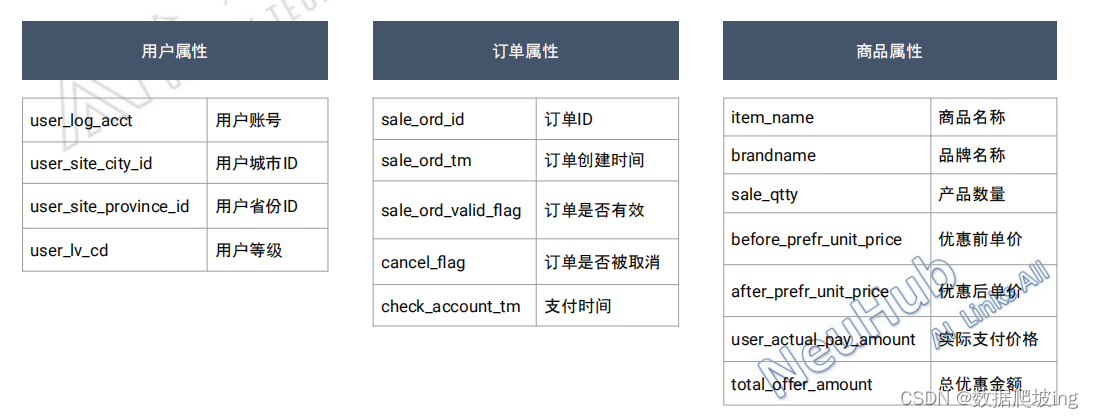
2,订单数据分析基本思路
维度下钻

3,代码实现全流程+思路
导包+绘图报错
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
#加上了绘图-全局使用中文+解决中文报错的代码
from matplotlib.ticker import FuncFormatter
plt.rcParams['font.sans-serif']=['Arial Unicode MS']
import warnings
warnings.filterwarnings('ignore')读取数据,观察表格特点(间隔符)
#虽然直接打开的文件显得很乱,需要去发现还是以/t作为分隔符的
order = 'course_order_d.csv'
df = pd.read_csv(order,sep='\t', encoding="utf-8", dtype=str)数据简单查看
df.head()
#查看数据是否为空+数据类型
df.info()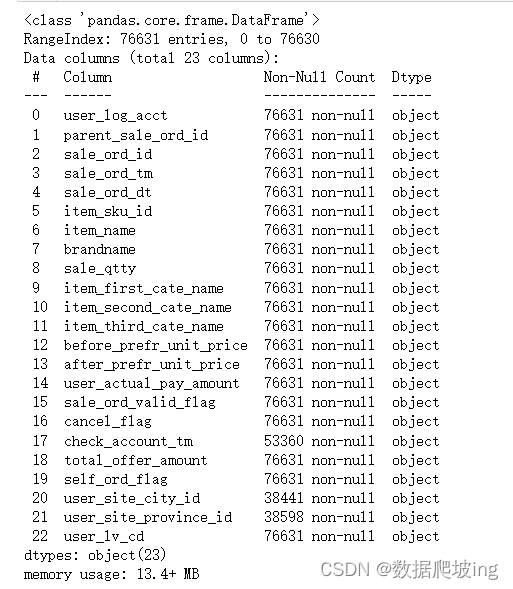
数据清洗+预处理
#说明都是2020-5-25下的订单
df['sale_ord_tm'].unique()
#都是object,所以先转化类型,再进行数据预处理
df['sale_qtty'] = df['sale_qtty'].astype('int')
df['sale_ord_valid_flag'] = df['sale_ord_valid_flag'].astype('int')
df['cancel_flag'] = df['cancel_flag'].astype('int')
df['self_ord_flag'] = df['self_ord_flag'].astype('int')
df['before_prefr_unit_price'] = df['before_prefr_unit_price'].astype('float')
df['after_prefr_unit_price'] = df['after_prefr_unit_price'].astype('float')
df['user_actual_pay_amount'] = df['user_actual_pay_amount'].astype('float')
df['total_offer_amount'] = df['total_offer_amount'].astype('float')
#pd.to_datetime()它可以用于将字符串或数字转换为日期时间对象,还可以用于自动识别和调整日期时间。如果原始数据包含非标准的日期时间表示形式,则这个函数会更加有用
df.loc[:,'check_account_tm '] = pd.to_datetime(df.loc[:,'check_account_tm'])
df.loc[:,'sale_ord_tm'] = pd.to_datetime(df.loc[:,'sale_ord_tm'])
df.loc[:,'sale_ord_dt'] = pd.to_datetime(df.loc[:,'sale_ord_dt'])
#个数/类型检查
df.info()
df.head()
#异常处理
#优惠前冰箱的最低价格是288,低于这个价格为异常值
(df.loc[:,'before_prefr_unit_price']<288).sum()
#确认优惠后价格,实际支付价格,总优惠金额 不是小于0的
(df.loc[:,'after_prefr_unit_price']<0).sum()
(df.loc[:,'user_actual_pay_amount']<0).sum()
(df.loc[:,'total_offer_amount']<0).sum()
print('删除异常值前',df.shape)
#去掉异常值
df=df[df['before_prefr_unit_price']>=288]
print('删除异常值后:',df.shape)
#确保每个订单都是唯一的
#唯一属性订单ID-去重
df.drop_duplicates(subset=['sale_ord_id'],keep='first',inplace=True)
df.info()
df.head()
df.isnull().sum().sort_values(ascending=False)
#空值处理-补值
df.user_site_city_id=df.user_site_city_id.fillna('Not Given')
df.user_site_province_id=df.user_site_province_id.fillna('Not Given')
#查看数值型字段的数据特征
df.describe()
#再次检查空值/类型
df.info()
#+字段=逻辑处理
df['total_actual_pay']=df['sale_qtty']*df['after_prefr_unit_price']
df
#检查,空值,字段,类型
df.info()宏观分析
#取消订单数量
order_cancel=df[df.cancel_flag==1]['sale_ord_id'].count()
order_cancel
#订单数量
order_num=df['sale_ord_id'].count()
order_num
order_cancel/order_num
# 解决matplotlib中文乱码
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['font.serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
labels=['取消','未取消']
X=[order_cancel,order_num-order_cancel]
fig=plt.figure()
plt.pie(X,labels=labels,autopct='%1.2f%%')
plt.title('订单总数')
#取消未取消差不多3:7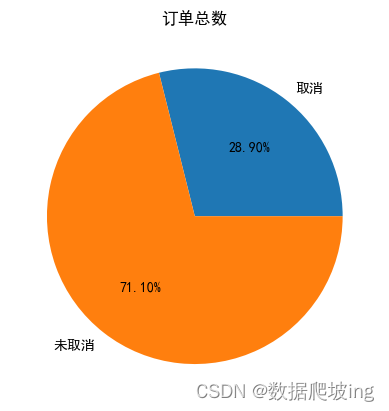
#求有效订单中,支付,未支付
df2=df.copy()
#只包含有效订单
df2=df2[(df2['sale_ord_valid_flag']==1)&(df2['cancel_flag']==0)&('before_prefr_unit_price'!=0)]
#有效订单数量
order_valid=df2['sale_ord_id'].count()
order_valid
#支付订单数量
order_payed=df2['sale_ord_id'][df2['user_actual_pay_amount']!=0].count()
order_payed
#未支付订单数量
order_unpay=df2['sale_ord_id'][df2['user_actual_pay_amount']==0].count()
order_unpay
order_unpay/order_payed
labels=['支付','未支付']
Y=[order_payed,order_unpay]
fig=plt.figure()
plt.pie(Y,labels=labels,autopct='%1.2f%%')
plt.title('有效订单总数')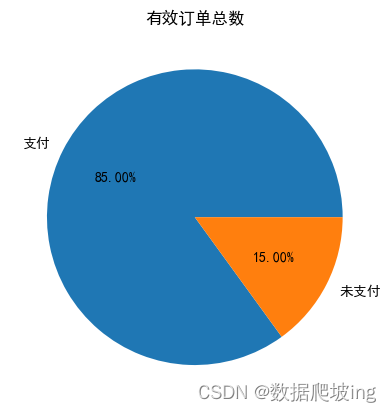
#订单的价格分布
price_series=df2['after_prefr_unit_price']
price_series
price_series_num=price_series.count()
hist,bin_edges=np.histogram(price_series,bins=80)
hist_sum=np.cumsum(hist)
hist_per=hist_sum/price_series_num
print('hist:{}'.format(hist))
print('*'*100)
print('bin_edges:{}'.format(bin_edges))
print('*'*100)
print('hist_sum:{}'.format(hist_sum))
hist_per
bin_edges_plot=np.delete(bin_edges,0)
plt.figure(figsize=(20,8),dpi=80)
plt.xlabel('订单价格')
plt.ylabel('百分比')
plt.style.use('ggplot')
def to_percent(temp,position):
return '%1.0f'%(100*temp)+'%'
plt.gca().yaxis.set_major_formatter(FuncFormatter(to_percent))
plt.plot(bin_edges_plot,hist_per,color='blue')
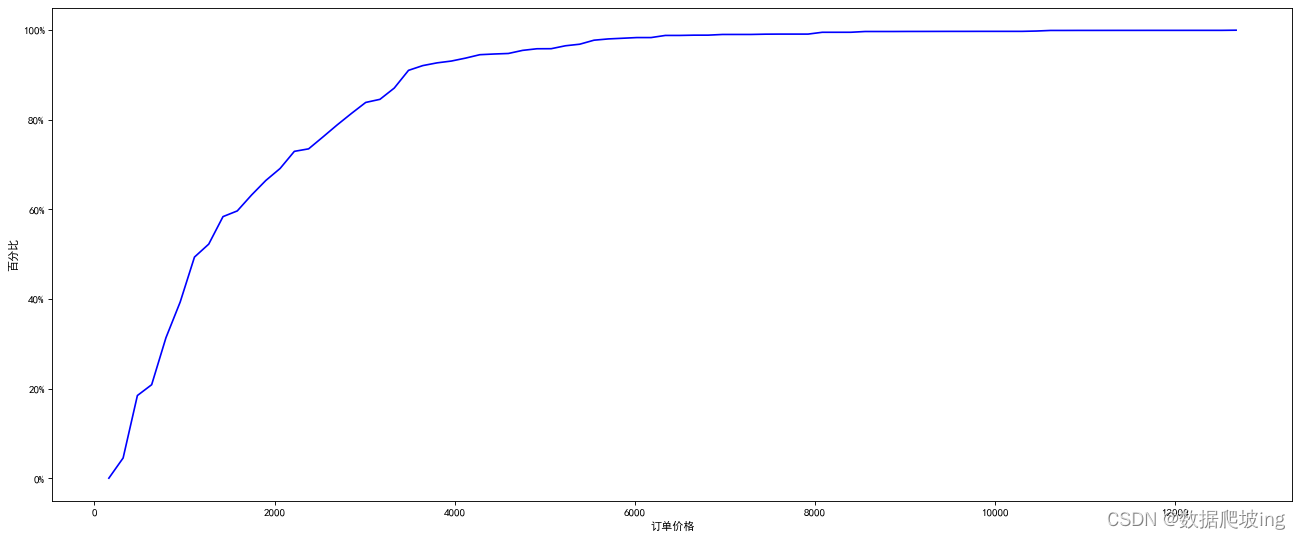
宏观分析结束,到微观分析啦
不同时间的有效订单数
df3=df2.copy()
df3['order_time_hms']=df3['sale_ord_tm'].apply(lambda x:x.strftime('%H:00:00'))
df3
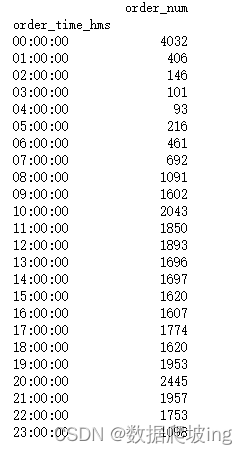
pay_time_df=df3.groupby('order_time_hms')['sale_ord_id'].count()
pay_time_df
x = pay_time_df.index
y = pay_time_df.values
plt.figure(figsize=(20,8),dpi=80)
plt.style.use('ggplot')
plt.xlabel('时间')
plt.ylabel("有效订单量")
plt.xticks(range(len(x)), x, rotation=90)
rect = plt.bar(x, y, width=0.3, color=['#6699CC'])
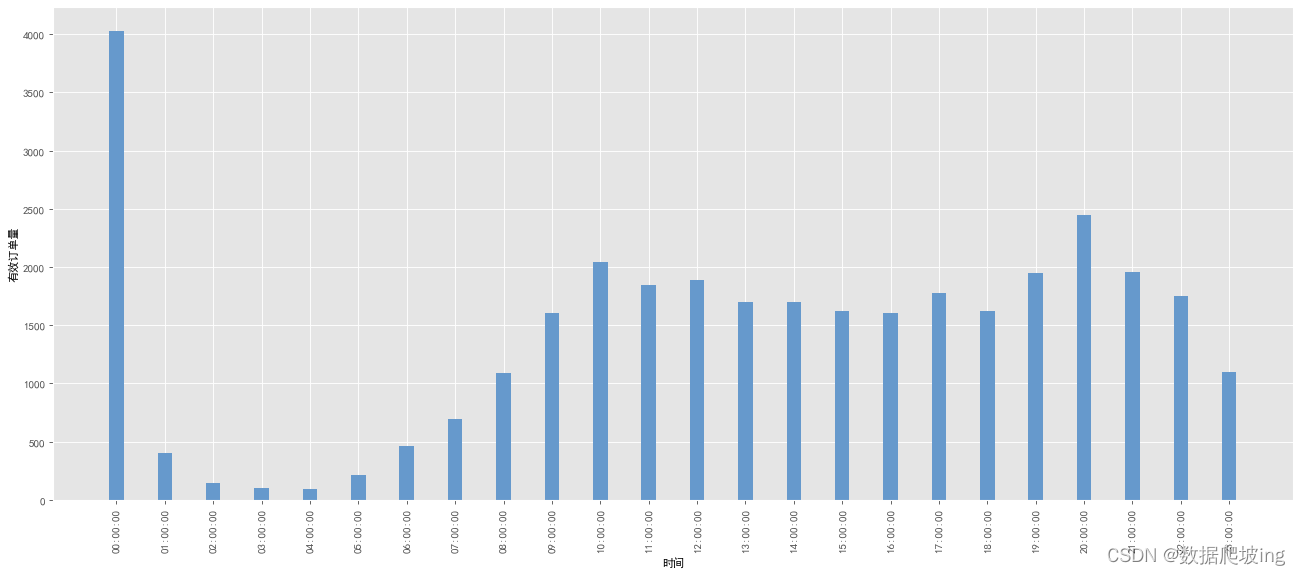
0点订单量最多,怀疑是不是单人下单多,下一步人均订单数
import pandas as pd
# 假设 df3 是你的原始 DataFrame
# 对 sale_ord_id 列按 order_time_hms 分组并计算计数
grouped = df3.groupby('order_time_hms')['sale_ord_id']
# 获取分组后的计数结果,如果是 Series,则转换为 DataFrame
result_series = grouped.agg('count')
if isinstance(result_series, pd.Series):
result_df = result_series.to_frame()
else:
result_df = result_series
# 重命名列
order_time_df = result_df.rename(columns={'sale_ord_id': 'order_num'})
# 打印结果
print(order_time_df)
import pandas as pd
# 假设 df3 是你的原始 DataFrame
# 对 user_log_acct 列按 order_time_hms 分组并计算每个组中唯一用户的数量
grouped = df3.groupby('order_time_hms')['user_log_acct']
# 获取分组后的唯一用户数量结果,如果是 Series,则转换为 DataFrame
result_series = grouped.agg('nunique')
if isinstance(result_series, pd.Series):
user_time_df = result_series.to_frame()
else:
user_time_df = result_series
# 重命名列
user_time_df = user_time_df.rename(columns={'user_log_acct': 'user_num'})
# 打印结果
print(user_time_df)

order_num_per_user = order_time_df['order_num'] / user_time_df['user_num']
x = order_num_per_user.index
y = order_num_per_user.values
plt.figure(figsize=(20,8),dpi=80)
plt.style.use('ggplot')
plt.xlabel('时间')
plt.ylabel("人均有效订单量")
plt.xticks(range(len(x)),x,rotation=90)
plt.plot(x, y)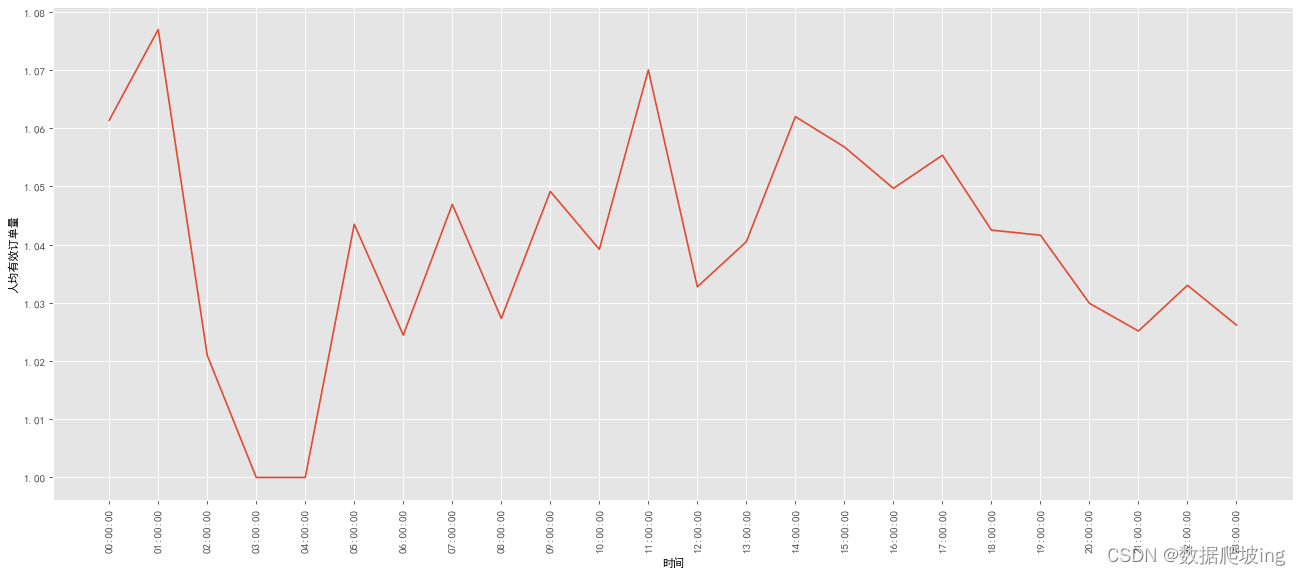
虽然0点订单量还是最多,有些波动,继续求客单价vs平均订单价格
客单价(销售额/顾客数)和平均订单价格(销售额/订单数)
import pandas as pd
# 假设 df3 是你的原始 DataFrame
# 对 total_actual_pay 列按 order_time_hms 分组并计算每个组的总和
grouped = df3.groupby('order_time_hms')['total_actual_pay']
# 获取分组后的总和结果
result_series = grouped.agg('sum')
# 将结果转换为 DataFrame
if isinstance(result_series, pd.Series):
total_pay_time_df = result_series.to_frame()
else:
total_pay_time_df = result_series
# 重命名列
total_pay_time_df = total_pay_time_df.rename(columns={'total_actual_pay': 'total_pay'})
# 打印结果
print(total_pay_time_df)
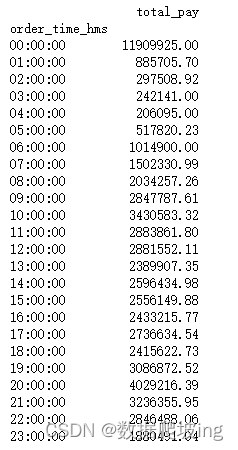
pay_per_user=total_pay_time_df['total_pay']/user_time_df['user_num']
pay_per_order=total_pay_time_df['total_pay']/order_time_df['order_num']
x=pay_per_user.index
y=pay_per_user.values
y2=pay_per_order.values
plt.figure(figsize=(20,8),dpi=80)
plt.style.use('ggplot')
plt.xlabel('时间')
plt.ylabel("价格")
plt.xticks(range(len(x)),x,rotation=90)
plt.plot(x, y, color='red',linewidth=2.0,linestyle='--')
plt.plot(x, y2, color='blue',linewidth=3.0,linestyle='-.')
plt.legend(['客单价','平均订单价'])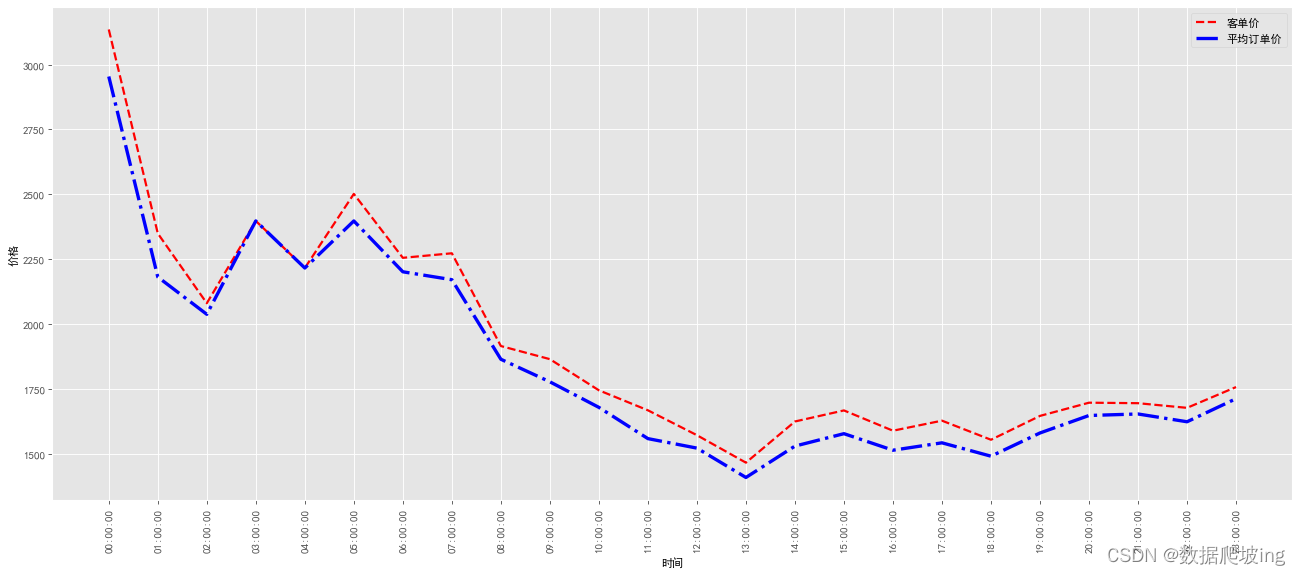
观察发现0点订单量最多,随后波动下滑,20点后开始平稳,是什么原因,继续研究是不是跟订单价格相关
df4=df3.copy()
df5=df3.copy()
df4 = df4[df4['order_time_hms'] == '00:00:00']
df5 = df5[df5['order_time_hms'] == '20:00:00']
def plot_acc_line(price_series, bin_num):
len = price_series.count()
hist, bin_edges = np.histogram(price_series, bins=bin_num) #生成直方图函数
hist_sum = np.cumsum(hist)
hist_per = hist_sum / len * 100
hist_per_plot = np.insert(hist_per, 0, 0)
plt.figure(figsize=(20,8), dpi=80)
plt.xlabel('订单价格')
plt.ylabel('百分比')
plt.plot(bin_edges, hist_per_plot, color='blue')
# 0时价格累积分布折线图
price_series_0 = df4['after_prefr_unit_price']
plot_acc_line(price_series_0, 100)
# 20时价格累积分布折线图,说明价格不是很大影响
price_series_20 = df5['after_prefr_unit_price']
plot_acc_line(price_series_0, 100)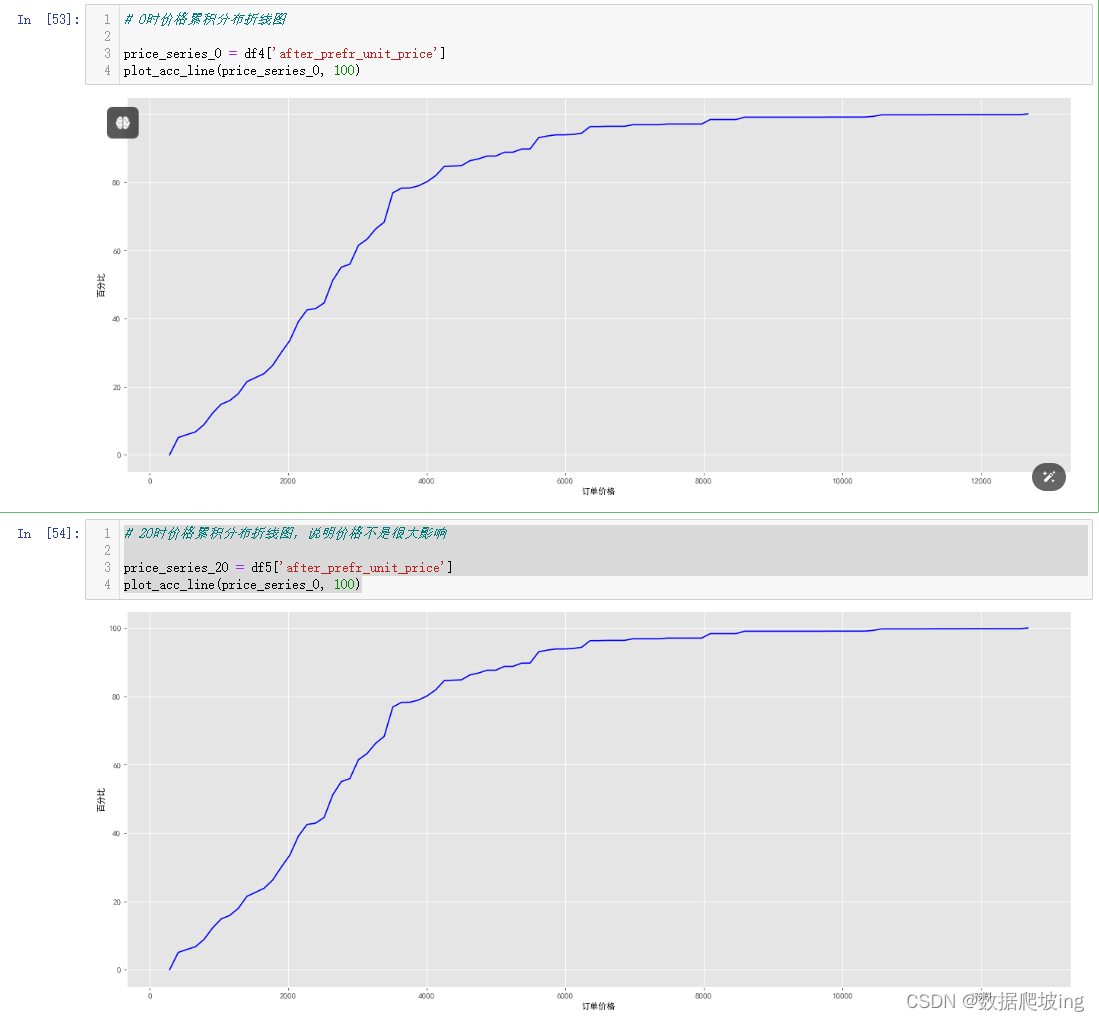
似乎和价格关联不大,那会不会和优惠相关呢,继续分析
0时和其他时间的优惠占比
#验证是不是和优惠相关
#0时的优惠订单数
offer_order_0=df4['sale_ord_id'][df4['total_offer_amount']>0].count()
#0时订单数
order_num_0=df4['sale_ord_id'].count()
#0时优惠订单比
offer_order_per_0=offer_order_0/order_num_0
print('0时的优惠订单数:{}, 0时的订单数:{}, 优惠订单比例:{}'.format(offer_order_0, order_num_0, offer_order_per_0))
#全部优惠订单数
offer_order_all=df3['sale_ord_id'][df3['total_offer_amount']>0].count()
#全部订单数
order_all=df3['sale_ord_id'].count()
#其他时间优惠订单数
offer_order_other=offer_order_all - offer_order_0
#其他时间订单数
order_num_other=order_all-order_num_0
offer_order_per_other=offer_order_other/order_num_other
print('其他时间的优惠订单数:{}, 其他时间的订单数:{}, 其他时间优惠订单比例:{}'.format(offer_order_other, order_num_other, offer_order_per_other))
#0时,和其他时间的优惠订单占比对比
plt.figure(figsize=(8,6),dpi=80)
N=2
index=('0时','除了0时之外')
data=(offer_order_per_0,offer_order_per_other)
width=0.35
plt.ylabel("优惠订单占比")
def to_percent(temp, position):
return '%1.0f'%(100*temp) + '%'
plt.gca().yaxis.set_major_formatter(FuncFormatter(to_percent))
p2 = plt.bar(index, data, width, color='#6699CC')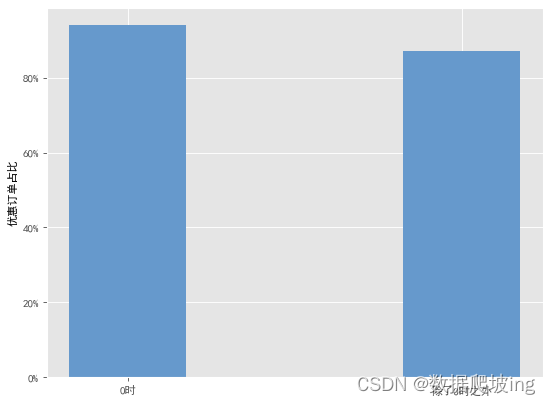
那会不会这个时间的某个优惠太多导致占比太大呢,继续求0时平均优惠占比 vs 其他时间平均优惠占比
import pandas as pd
# 假设 df3 是你的原始 DataFrame
# 对 user_log_acct 列按 order_time_hms 分组并计算每个组中唯一用户的数量
grouped = df3.groupby('order_time_hms')['total_offer_amount']
# 获取分组后的唯一用户数量结果,如果是 Series,则转换为 DataFrame
result_series = grouped.agg('sum')
if isinstance(result_series, pd.Series):
user_time_df = result_series.to_frame()
else:
user_time_df = result_series
# 重命名列
total_pay_time_df = user_time_df.rename(columns={'order_time_hms': 'total_offer_amount'})
# 打印结果
print(total_pay_time_df)
offer_amount_0=total_pay_time_df['total_offer_amount'][0]
offer_amount_other=total_pay_time_df[1:].apply(lambda x:x.sum())['total_offer_amount']
offer_amount_0_avg=offer_amount_0/offer_order_0
offer_amount_other_avg=offer_amount_other/offer_order_other
print('0时平均优惠价格:{}, 其他时间平均优惠价格:{}'.format(offer_amount_0_avg, offer_amount_other_avg))
#0时和其他时间的平均优惠价格对比:可视化
plt.figure(figsize=(8, 6), dpi=80)
N = 2
index = ('0时', '除了0时以外')
values = (offer_amount_0_avg, offer_amount_other_avg)
width = 0.35
plt.ylabel("平均优惠价格/元")
p2 = plt.bar(index, values, width, color='#6699CC')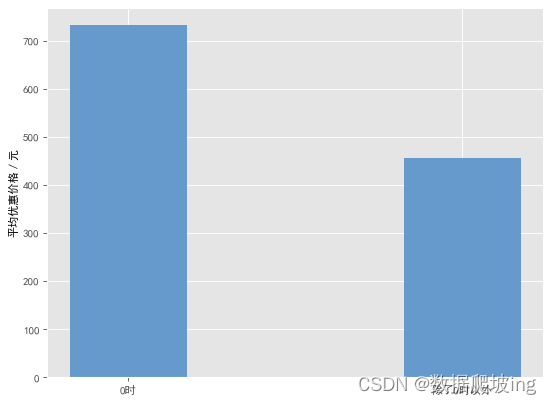
确认0时订单量大与优惠金额相关,接下来从地区维度拆分
df6=df2.copy()
order_area_df=df6.groupby('user_site_province_id',as_index=False)['sale_ord_id'].agg('count')
order_area_df
import pandas as pd
# 假设 df3 是你的原始 DataFrame
# 对 user_log_acct 列按 order_time_hms 分组并计算每个组中唯一用户的数量
grouped = df6.groupby('user_site_province_id',as_index=False)['sale_ord_id']
# 获取分组后的唯一用户数量结果,如果是 Series,则转换为 DataFrame
result_series = grouped.agg('count')
if isinstance(result_series, pd.Series):
user_time_df = result_series.to_frame()
else:
user_time_df = result_series
# 重命名列
order_area_df = user_time_df.rename(columns={'sale_ord_id': 'order_num'})
# 打印结果
print(order_area_df)
order_area_df.drop([34],inplace=True)
order_area_df['province_id']=order_area_df['user_site_province_id'].astype('int')
order_area_df
city = 'city_level.csv'
df_city = pd.read_csv(city,sep = ',', encoding="gbk", dtype=str)
df_city['province_id'] = df_city['province_id'].astype('int')
df_city
#省份去重
df_city=df_city.drop_duplicates(subset=['province_id'],keep='first')
df_city
df_city=df_city[['province_id','dim_province_name']].sort_values(by='province_id',ascending=True).reset_index()
df_city.drop(['index'],axis=1,inplace=True)
df_city
order_province_df=pd.merge(order_area_df,df_city,on='province_id').sort_values(by='order_num',ascending=False)
order_province_df
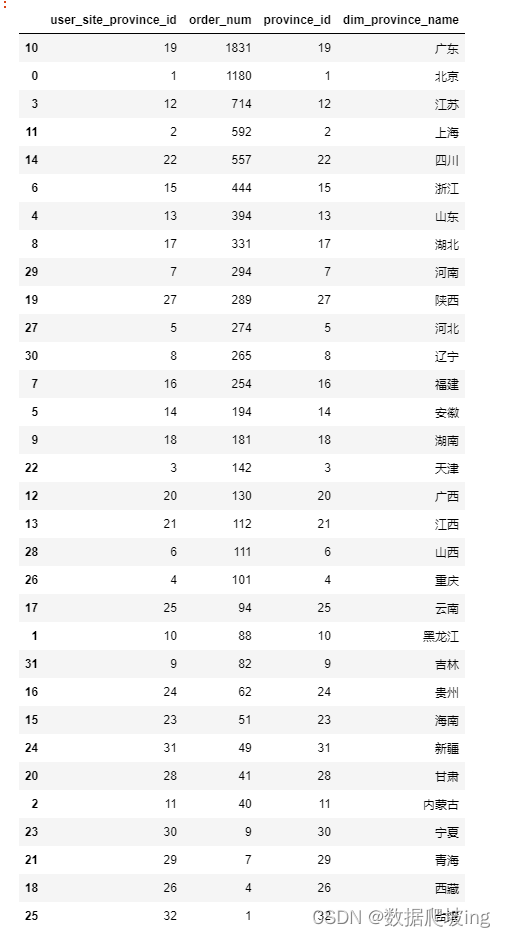
各个省份订单量
#有效订单量
plt.style.use('ggplot')
x = order_province_df['dim_province_name']
y = order_province_df['order_num']
plt.figure(figsize=(20,8),dpi=80)
plt.style.use('ggplot')
plt.xlabel('时间')
plt.ylabel("有效订单量")
plt.xticks(range(len(x)), x, rotation=90)
rect = plt.bar(x, y, width=0.3, color=['#6699CC'])
#有效订单量-饼图
plt.figure(figsize=(6,9))
labels = order_province_df['dim_province_name']
plt.pie(order_province_df['order_num'], labels=labels,autopct='%1.2f%%') # autopct :控制饼图内百分比设置, '%1.1f'指小数点前后位数(没有用空格补齐);
plt.axis('equal')
plt.show()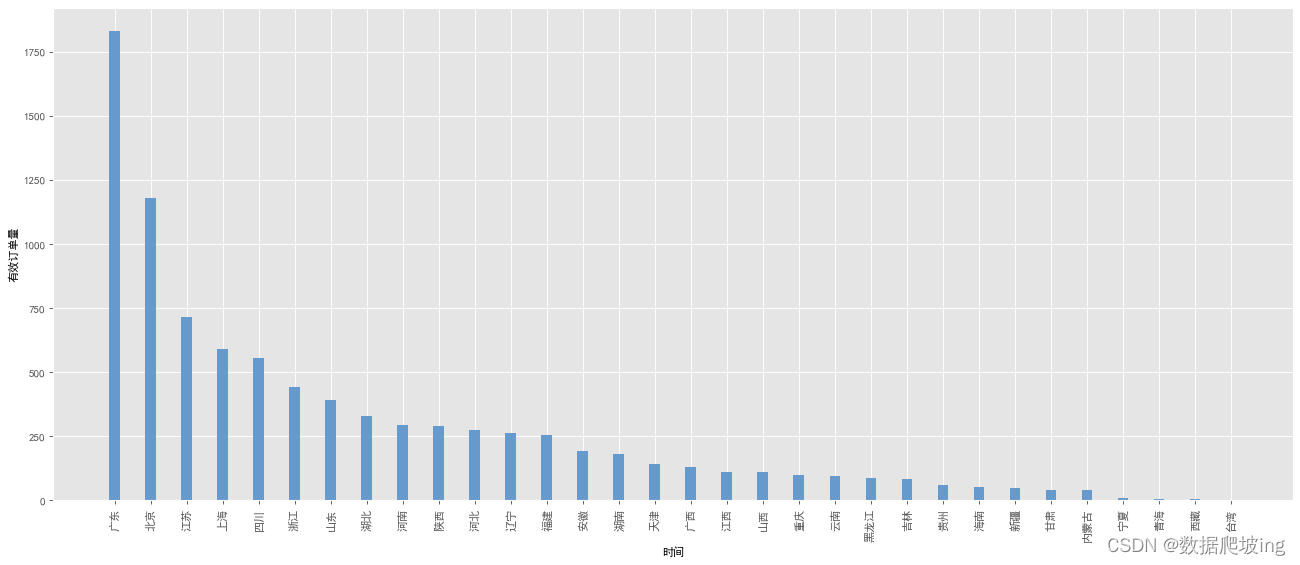
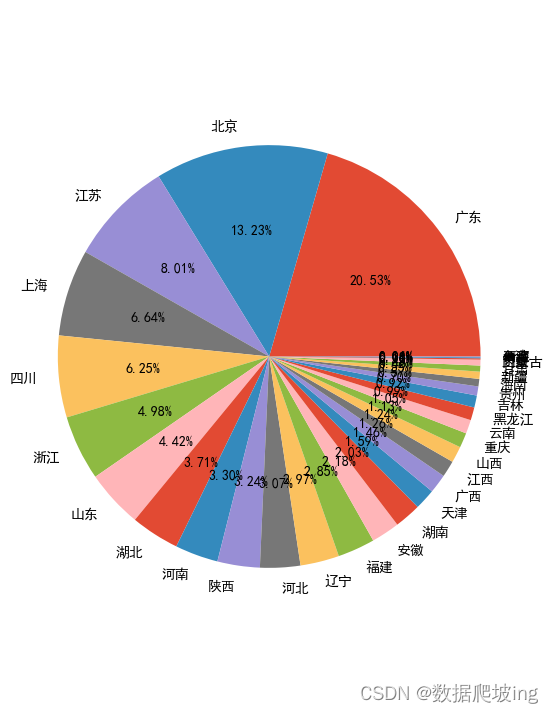
怕一个客订单多,求各省份客单价对比
#各省份客单价对比
cust_price_df = df6.groupby('user_site_province_id', as_index=False)['total_actual_pay'].agg({'total_pay':'sum'})
cust_price_df.columns = ['province_id','total_pay']
cust_price_df.drop([34], inplace=True)
cust_price_df['province_id'] = cust_price_df['province_id'].astype('int')
cust_price_df = pd.merge(cust_price_df, df_city, on='province_id').sort_values(by='total_pay', ascending=False)
cust_price_df['order_num'] = order_province_df['order_num']
cust_df = df6.groupby('user_site_province_id', as_index=False)['user_log_acct'].agg({'user_num':'nunique'})
cust_df.columns = ['province_id','user_num']
cust_df.drop([34], inplace=True)
cust_df['province_id'] = cust_df['province_id'].astype('int')
cust_price_df = pd.merge(cust_price_df, cust_df, on='province_id')
cust_price_df['cust_price'] = cust_price_df['total_pay'] / cust_price_df['user_num'] #计算客单价
cust_price_df = cust_price_df.sort_values(by='order_num', ascending=False)
cust_price_df = cust_price_df[:10]
cust_price_df = cust_price_df.sort_values(by='cust_price', ascending=False)
cust_price_df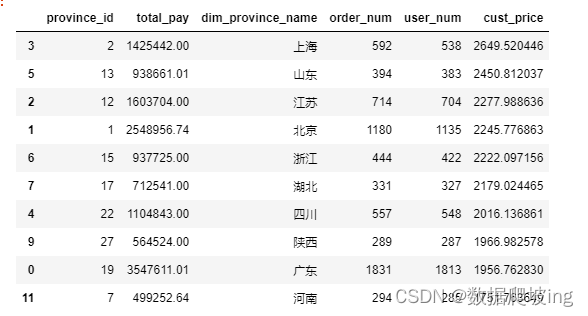
plt.style.use('ggplot')
x = cust_price_df['dim_province_name']
y = cust_price_df['cust_price']
plt.figure(figsize=(20,8),dpi=80)
plt.style.use('ggplot')
plt.xlabel('时间')
plt.ylabel("客单价")
rect = plt.bar(x, y, width=0.3, color=['#6699CC'])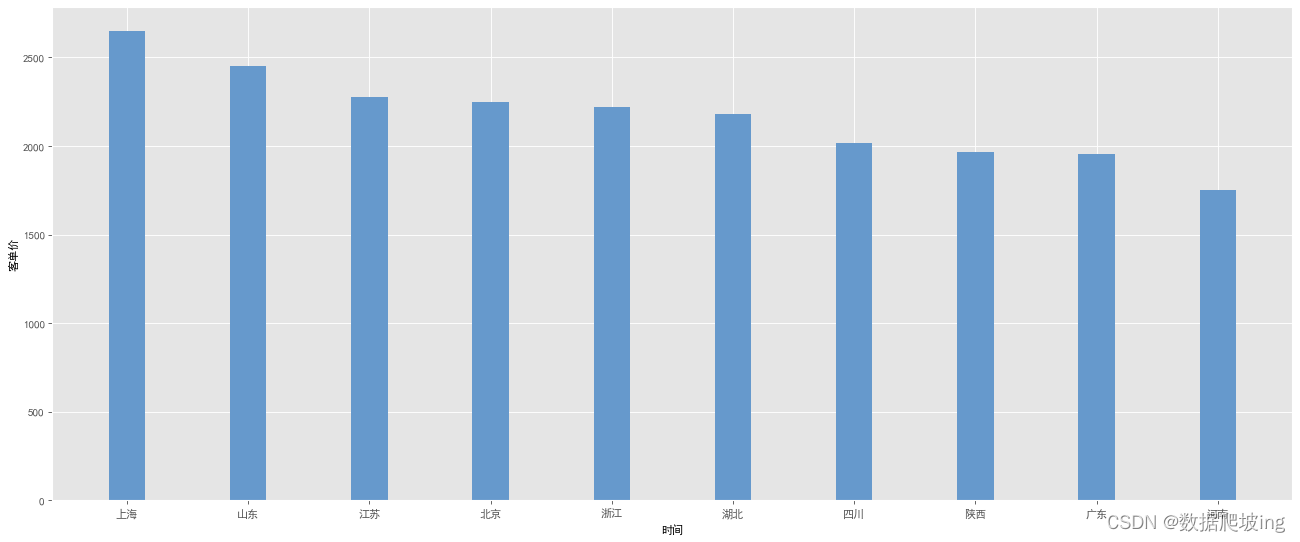
可能客单价大的订单数小,可能客单价小的订单数多,气泡图显示
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(15, 10))
x = cust_price_df['cust_price']
y = cust_price_df['order_num']
# Calculate the minimum and maximum sizes based on your data
min_size = min(cust_price_df['cust_price']) * 3
max_size = max(cust_price_df['cust_price']) * 3
# Use the calculated sizes for the scatterplot
ax = sns.scatterplot(x=x, y=y, hue=cust_price_df['dim_province_name'], palette=['#6699CC'], sizes=(min_size, max_size), size=x*3, legend=False)
ax.set_xlabel("客单价", fontsize=12)
ax.set_ylabel("订单数量", fontsize=12)
province_list = [3, 5, 2, 1, 6, 7, 4, 9, 0, 11]
# Adding text on top of the bubbles
for line in province_list:
ax.text(x[line], y[line], cust_price_df['dim_province_name'][line], horizontalalignment='center', size='large', color='black', weight='semibold')
plt.show()
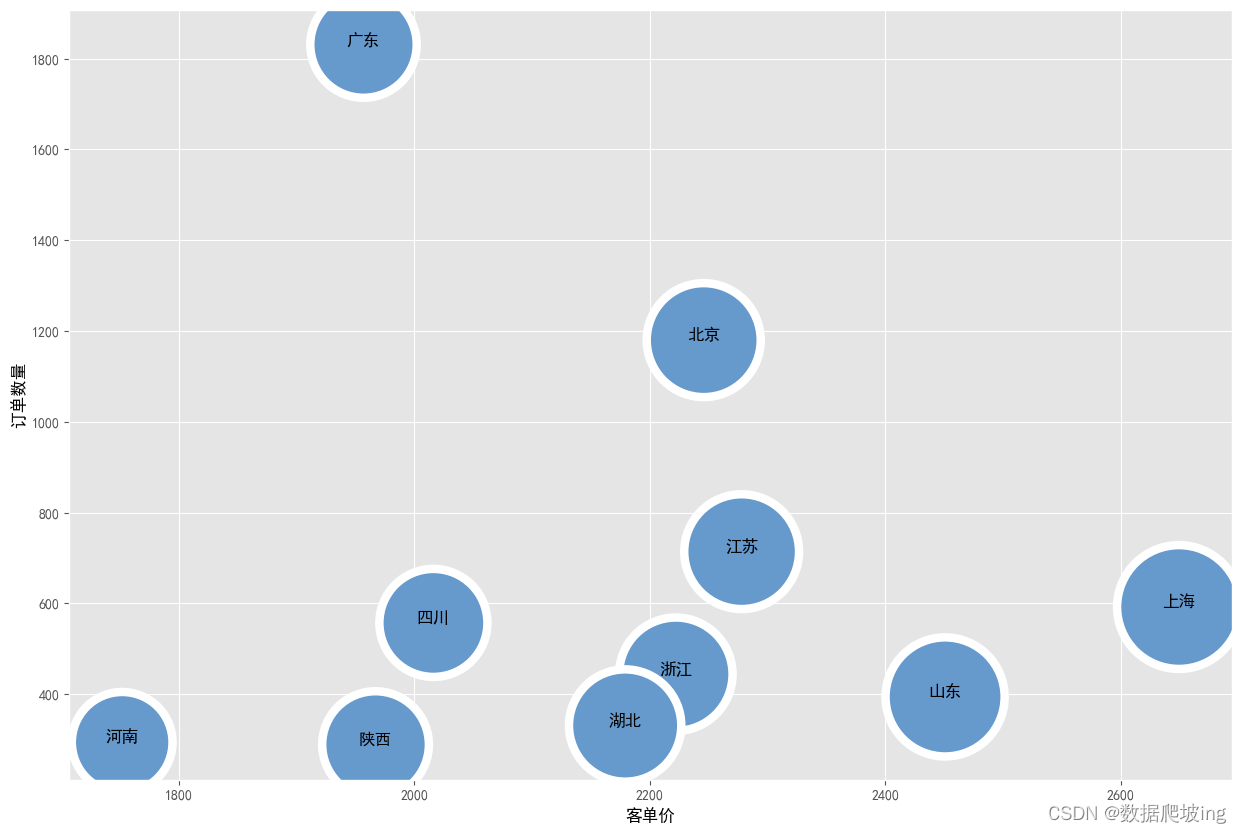
知道上海虽然客单价高2600左右,但是订单数量少600左右
广东订单数量多1800左右,客单价在2000左右
下一步,看头部省份的四个品牌的渗透率
#不同品牌的产品单价
df7 = df2.copy()
brand_sale_df=df7.groupby('brandname',as_index=False).agg({'total_actual_pay':'sum','sale_qtty':'sum'}).sort_values(by='total_actual_pay',ascending=False)
brand_sale_df
df8 = df7.copy()
df8 = df8[df8['user_site_province_id'] == '1'] # 省份取北京,数字是省份id
brand_sale_df_bj = df8.groupby('brandname', as_index=False).agg({'total_actual_pay':'sum', 'sale_qtty':'sum'}).sort_values(by='total_actual_pay', ascending=False)
brand_sale_df_bj = brand_sale_df_bj[(brand_sale_df_bj['brandname'] == '海尔(Haier)')|(brand_sale_df_bj['brandname'] == '容声(Ronshen)')|(brand_sale_df_bj['brandname'] == '西门子(SIEMENS)')|(brand_sale_df_bj['brandname'] == '美的(Midea)')]
brand_sale_df_bj
df8=df7.copy()
df8=df8[df8['brandname']=='海尔(Haier)']
brand_sale_df_haier=df8.groupby('user_site_province_id',as_index=False).agg({'total_actual_pay':'sum','sale_qtty':'sum'}).sort_values(by='total_actual_pay',ascending=False)
brand_sale_df_haier = brand_sale_df_haier[(brand_sale_df_haier['user_site_province_id'] == '1')|(brand_sale_df_haier['user_site_province_id'] == '2')|(brand_sale_df_haier['user_site_province_id'] == '12')|(brand_sale_df_haier['user_site_province_id'] == '22')|(brand_sale_df_haier['user_site_province_id'] == '19')]
brand_sale_df_haier['user_site_province_id'] = brand_sale_df_haier['user_site_province_id'].astype('int')
brand_sale_df_haier.columns = ['province_id','total_actual_pay', 'sale_qtty']
brand_sale_df_haier.sort_values(by='province_id')
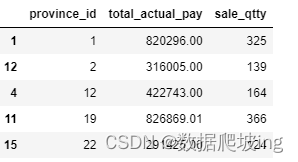
cust_price_df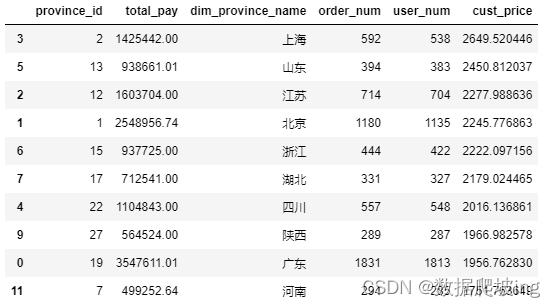
order_num_df = cust_price_df[['province_id', 'order_num']][(cust_price_df['province_id'] == 1)|(cust_price_df['province_id'] == 12)|(cust_price_df['province_id'] == 19)|(cust_price_df['province_id'] == 2)|(cust_price_df['province_id'] == 22)]
order_num_df = order_num_df.sort_values(by='province_id')
order_num_df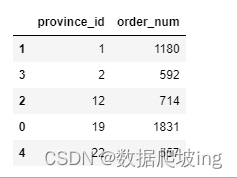
渗透率
def province_shentou(df, brandname, cust_price_df):
df = df[df['brandname'] == brandname]
brand_sale_df = df.groupby('user_site_province_id', as_index=False).agg({'total_actual_pay':'sum', 'sale_qtty':'sum'}).sort_values(by='total_actual_pay', ascending=False)
brand_sale_df = brand_sale_df[(brand_sale_df['user_site_province_id'] == '1')|(brand_sale_df['user_site_province_id'] == '2')|(brand_sale_df['user_site_province_id'] == '12')|(brand_sale_df['user_site_province_id'] == '22')|(brand_sale_df['user_site_province_id'] == '19')]
brand_sale_df['user_site_province_id'] = brand_sale_df['user_site_province_id'].astype('int')
brand_sale_df.columns = ['province_id','total_actual_pay', 'sale_qtty']
brand_sale_df.sort_values(by='province_id')
order_num = cust_price_df[['province_id', 'order_num']][(cust_price_df['province_id'] == 1)|(cust_price_df['province_id'] == 12)|(cust_price_df['province_id'] == 19)|(cust_price_df['province_id'] == 2)|(cust_price_df['province_id'] == 22)]
order_num = order_num.sort_values(by='province_id')
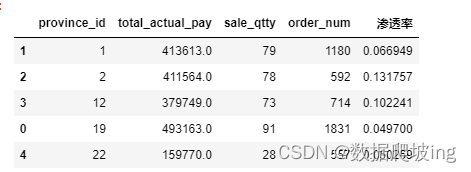
brand_sale_df = pd.merge(brand_sale_df, order_num_df, on='province_id')
brand_sale_df['渗透率'] = brand_sale_df['sale_qtty'] / brand_sale_df['order_num']#销售数量/订单数量
brand_sale_df = brand_sale_df.sort_values(by='province_id')
return brand_sale_df
df9 = df7.copy()
brand_sale_df_rs = province_shentou(df9, '容声(Ronshen)', cust_price_df)
brand_sale_df_siem = province_shentou(df9, '西门子(SIEMENS)', cust_price_df)
brand_sale_df_mi = province_shentou(df9, '美的(Midea)', cust_price_df)
brand_sale_df_haier = province_shentou(df9, '海尔(Haier)', cust_price_df)
brand_sale_df_siem
plt.style.use('ggplot')
x = np.arange(5)
y1 = brand_sale_df_siem['渗透率']
y2 = brand_sale_df_rs['渗透率']
y3 = brand_sale_df_haier['渗透率']
y4 = brand_sale_df_mi['渗透率']
tick_label=['北京', '上海', '江苏', '广东', '四川']
total_width, n = 0.8, 4
width = total_width / n
x = x - (total_width - width) / 2
plt.figure(figsize=(20,8),dpi=80)
plt.style.use('ggplot')
plt.ylabel("渗透率")
bar_width = 0.2
plt.bar(x, y1, width=bar_width, color=['red'])
plt.bar(x+width, y2, width=bar_width, color=['yellow'])
plt.bar(x+2*width, y3, width=bar_width, color=['green'])
plt.bar(x+3*width, y4, width=bar_width, color=['blue'])
plt.xticks(x+bar_width/2, tick_label) # 显示x坐标轴的标签,即tick_label,调整位置,使其落在两个直方图中间位置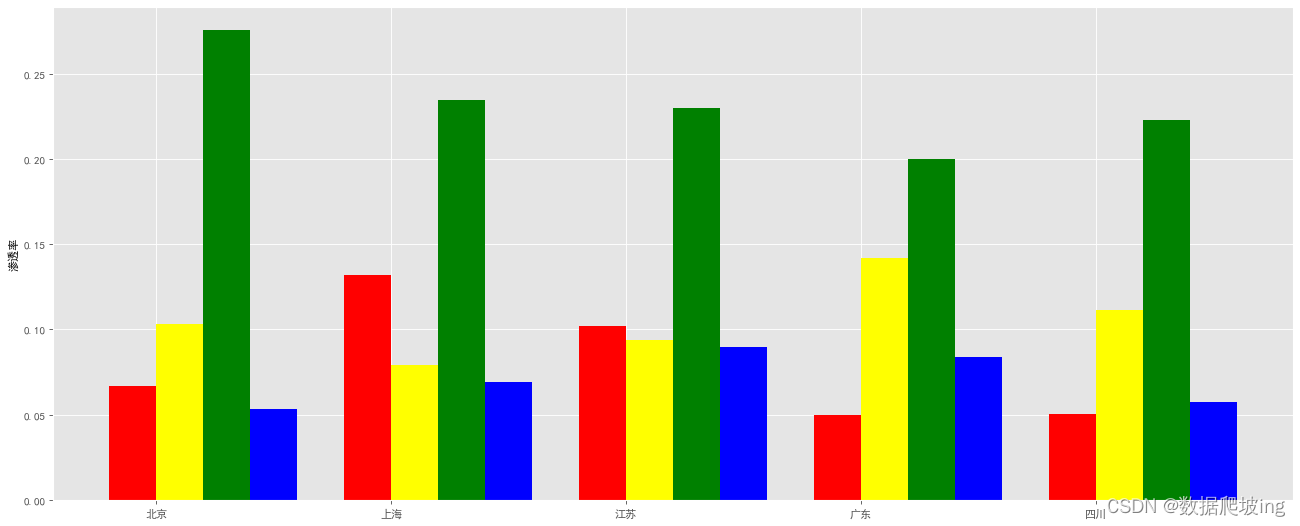
求各个品牌的客单价
plt.style.use('ggplot')
brand_sale_df['单价'] = brand_sale_df['total_actual_pay'] / brand_sale_df['sale_qtty']
brand_sale_df = brand_sale_df.sort_values(by='单价', ascending=False)
x = brand_sale_df['brandname']
y = brand_sale_df['单价']
plt.figure(figsize=(20,8),dpi=80)
plt.style.use('ggplot')
plt.xlabel('品牌')
plt.ylabel("客单价")
plt.xticks(range(len(x)), x, rotation=90)
rect = plt.bar(x, y, width=0.6, color=['#6699CC'])
plt.show()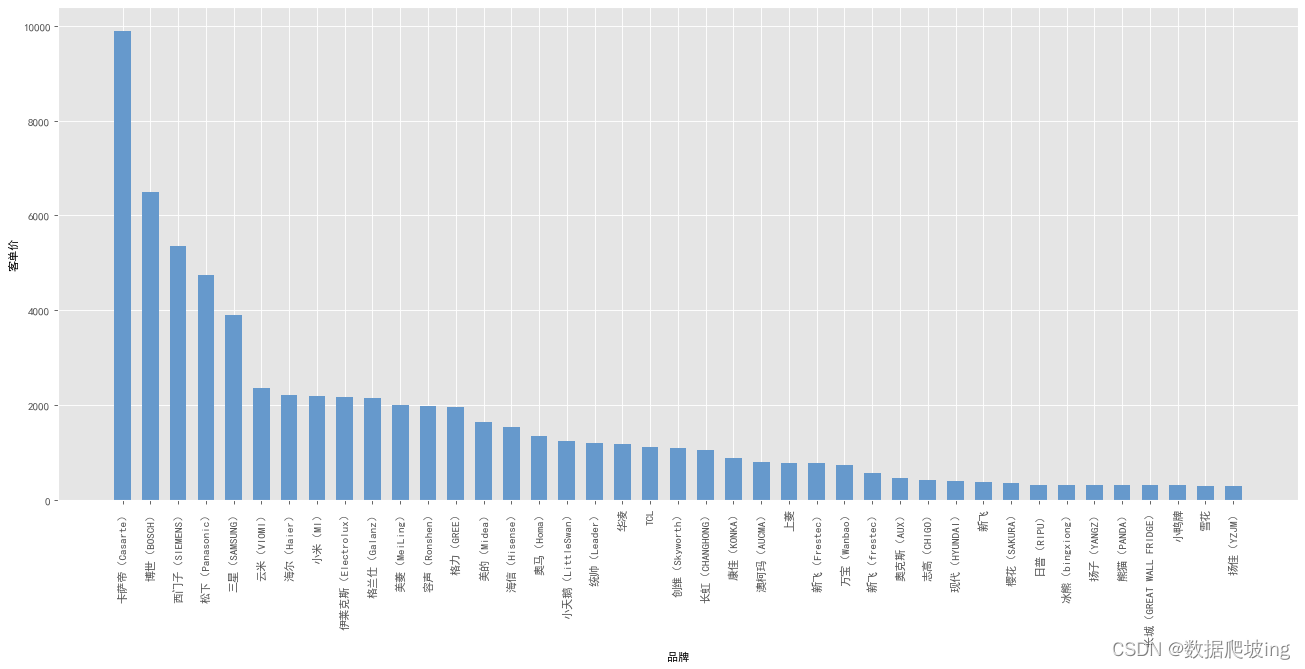
4,总结

(交个朋友/技术接单/ai办公/性价比资源)

















 6016
6016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











