






一、数据预处理
1、总结:做分类模型需要将数据提取保存成 【x,y】形式,
将所有数据保存成一个list格式【【x1,y1】,【x2,y2】】
2、截图:去除停用词用空格分开
二、构建词库及切分数据集
1、构建三个字典
x = {token1:id1} --------- 用于将文本token进行数值转换,传给模型
y_id = {y1:id1} --------- 用于将标签转换数值 传给模型
id_y = {id1:y1} --------- 用于将模型传出的结果转换中午标签
2、切分数据集
将总数据切分成训练集和测试集 (8:2或其它)
3、构建DataLoader
三、参数初始化
1、总结:
自定义的:
(1):批次大小
作用:决定了每次训练时模型处理的数据量,
较小:(对数据特征抓取不准)
优点:内存消耗少,减少过度拟合
缺点:训练速度较慢,可能梯度估计不准,不稳定、收敛速度慢
较大:(抓取特征准,容易过拟合)
优点:训练速度较快,充分利用硬件加速器的并行计算能力。
确保收敛性,更好地平均梯度,减少梯度更新的噪声
有助于收敛到较好的局部最小值
缺点:内存需求高
泛化性能下降
建议:尝试不同的批次大小,观察验证集上的性能
(2):Embedding维度
作用:将token转换固定大小向量空间维度
较小:捕捉语义信息相对少,
较大:增加模型复杂性,并容易过拟合
建议:可以通过交叉验证来选择最优的维度
(3):rnn隐藏大小
作用:LSTM单元中隐藏状态维度
较小:导致模型容量不足,文本信息少
较大:容易过拟合
建议:可以通过交叉验证来选择最优的维度
(4):训练轮数
作用:定义训练次数
(5):学习率
作用:决定了模型在每次参数更新时的步长大小
较大:加速训练过程,可能导致训练不稳定
较小:可能导致训练过程过慢
建议:可以使用学习率调度器,来自动调整学习率
固定的:
(1):词库数量
(2):类别数量
四、模型构建
第一部分:__init__
1、词向量
self.embedding = nn.Embedding(词库大小, 词向量维度, padding_idx=0)
padding_idx填充
2、模型
self.rnn = nn.GRU(input_size = embedding维度,hidden_size=RNN维度
batch_first = True(指定输入和输出张量的形状),)
3、输出层
self.out = nn.Linear(rnn隐层维度大小, 类别数量
第二部分:forward(self, x)
1、将文本转换为向量 x = self.embedding(x)
2、经过模型得到输出 r_out, h_n = self.rnn(x)
3、经过输出层得到结果 out = self.out(h_n[0])
return out
整体代码:

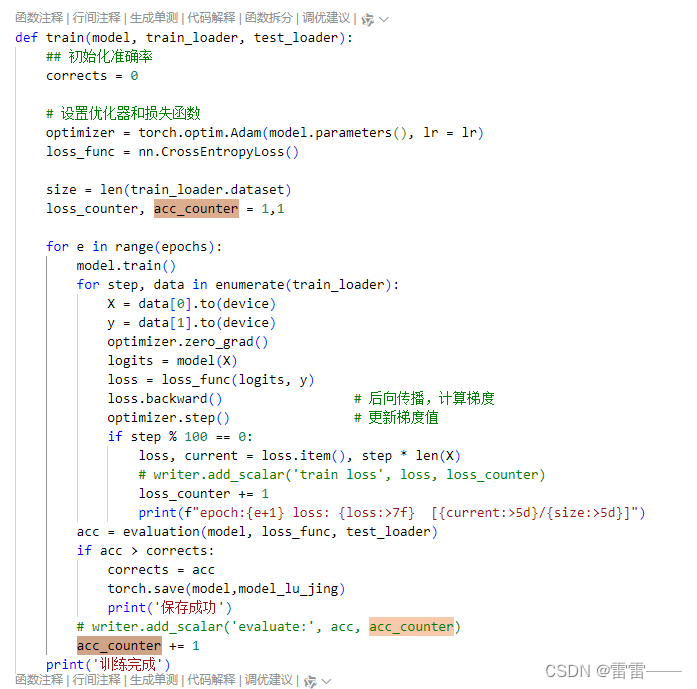
五、训练模型
1、设置优化器和损失函数
2、循环训练轮次
3、设置模型为训练模式
4、遍历训练数据
5、优化器梯度清零
6、前向传播
7、计算损失
8、后向传播
9、更新梯度值
10、每一轮训练训练完一次数据 进行测试集测试
11、判断准确率是否比上次好 进行保存模型
12、整体代码
六、调用训练好的模型
1、将输入的文本和训练数据一样的处理 (分词、去停用、转数值)
2、加载保存好的模型
3、将处理好的文本 输入模型
4、将输出的数据进行归一化映射(0,1)
5、和4同步找到最大值的索引映射为标签
6、得到了 概率值和输出标签















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









