






自己写的mapreduce
mapreduce是hadoop核心
-
mapreduce进行存在于hdfs上的dd的运算(也就是这个文件必须存储在hdfs上,才可以进行mapreduce的运算
-
mapreduce是离线分布式计算框架
-
map:数据进行运算,map的阶段进行数据的不同机器上的运算
-
reduce:不同机器上map的数据进行合并
-
离线:mapreduce是基于磁盘上的文件的运算(不是实时进行数据统计/运算的)—-》是要找一个空闲时间(用户访问量少的时候),进行统一的统计/运算—-》这是一种推荐方式
-
还有一种推荐方式:spark—-》spark是基于内存进行的运算(是实时进行推荐的,但是对内存的要求比较大)
-
mapreduce执行流程???
-
mapreduce书写过程---->写一个简单的逻辑来体会---->我们来写一个自定义的wordcount(一行就看做为一个单词,然后来统计整个文件的单词数)
1.导包
- 中央仓库添加mapreduce依赖
- 选择和hadoop相同版本的core(3.2.1)
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.2.1</version>
</dependency>
2.map逻辑书写
-
先继承Mapper
为什么要继承Mapper?
因为我们要实现map—>就是怎么能够让这方法成为可以处理map的方法?—>继承Mapper类(extends Mapper)---->注意:还需要泛型指定
为什么要进行泛型的指定?—>因为Mapper类的结构如下:// <>中是四个泛型 public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {...}
3.reduce逻辑书写
-
先继承Reducer
-
同样要写四个泛型
public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
4.使mapreduce能够运行的main函数书写
- 就是给mapreduce提供一个job
5.整个代码示例
package neuedu.test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Demo1 {
// 先继承Mapper
/**
* 四个范型
* (1)进行每一行的位置的记录:map读取指定文件中的数据——》每一行开始的位置,数字进行的记录——》我们现在写的是大数据,所以文件会比较大——》可以定义long类型(在大数据里面自己封装的叫做longWritable类型)
* (2)进行文件中数据的读取:map进行文件中数据的读取(按行读取),一行一行的进行数据获取—-》一行中数据为String类型(在大数据中国自己封装的类型叫做Text类型)
* (3)进行每一行单词的获取:map进行每一行单词的获取—-》要进行映射(单词,数量1)——》这里还要继续写出给reduce—-》需要key的类型(就是单词类型)—-》也就是字符串类型(大数据中为Text)
* (4)同(3):map写出到reduce中value的类型(数量1)—-》数字类型(先定义为int)—-》(大数据中为IntWritable)
* 注意:数量=1–》是因为我们现在写的简单逻辑是一行就看成是一个单词,所以读取一行,就赋值为1
*/
public static class Map1 extends Mapper<LongWritable, Text,Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
/**
* value是当前一行的值,需要进行map的过程
* 给当前的值进行数据映射,并且写出到reduce中
* key==>每一行开始的位置,value当前一行的值
* context 上下文对象,通过对象进行数据的写出reduce
*/
context.write(value,new IntWritable(1));
}
}
// 先继承Reducer
/**
* 四个范型
* (1)map写入reduce中的数据,key类型—》Text
* (2)map写入reduce中的数据,value类型—》IntWritable
* (3)单词的类型:reduce进行数据合并,把数据写出到磁盘上,格式是(单词,数量)—》先写出单词的类型(key类型)—》字符串—〉Text
* (4)数量的类型:value类型—》LongWritable
*/
public static class Reduce1 extends Reducer<Text,IntWritable,Text,LongWritable>{
/**
* key===>从map中接受的key的类型
* values===>是一个集合,进行当前可以相同时,数据值的存储
* reduce中的数据写出到hdfs上===>通过context进行的写出
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
int count=0;
for (IntWritable i:values
) {
count+=i.get();
}
context.write(key,new LongWritable(count));
}
}
public static void main(String[] args){
// 进行java程序的运行
// hdfs的配置
Configuration conf=new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.246.177:9000");
try {
Job job = Job.getInstance(conf);
// job相关信息
// 设置job的名字
job.setJobName("javawordcount");
// job运行类
job.setJarByClass(Demo1.class);
// job执行map相关信息的配置
job.setMapperClass(Demo1.Map1.class);
// 向reduce输出key的类型
job.setMapOutputKeyClass(Text.class);
// 向rudece输出value的类型
job.setMapOutputValueClass(IntWritable.class);
// job执行reduce的配置
job.setReducerClass(Demo1.Reduce1.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 注意导包import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
FileInputFormat.setInputPaths(job,new Path("/datas.txt"));
FileOutputFormat.setOutputPath(job,new Path("/java1"));
// 提交执行
job.waitForCompletion(true);
} catch (IOException e) {
throw new RuntimeException(e);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
}
}
6.报错解决
-
至此代码会报一个错误,如下:
Caused by: java.io.IOException: Cannot initialize Cluster. Please check your configuration for mapreduce.framework.name and the correspond server addresses. -
我们需要到中央仓库中找一个依赖添加到pom.xml中
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-jobclient -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>3.2.1</version>
//删掉scope(作用域)这一行
// <scope>test</scope>
</dependency>
7.报错的日志显示
log4j.properties
此文件夹加在 \src\main\resources 下
------------------------------------------
8.代码变形(逻辑优化)
(1) 优化1---->按照空格统计单词个数
- 现在我们所写的代码只能按行统计单词个数
- 但是现在 我们想按照空格来统计单词个数
- 优化部分 : Map(利用split函数,按照空格进行单词的切割–>然后再进行单词统计)
public static class Map1 extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
/**
* value是当前一行的值,需要进行map的过程
* 给当前的值进行数据映射,并且写出到reduce中
* key==>每一行开始的位置,value当前一行的值
* context 上下文对象,通过对象进行数据的写出reduce
*/
// 进行每行数据的读取,每读一行数据-->进行数据的切割(通过空格进行数据的切割-->利用split函数)
String[] s=value.toString().split(" ");
for (String a:s
) {
context.write(new Text(a),new IntWritable(1));
}
}
}
- 全部代码
package neuedu.test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Demo2 {
// 先继承Mapper
/**
* 四个范型
* (1)进行每一行的位置的记录:map读取指定文件中的数据——》每一行开始的位置,数字进行的记录——》我们现在写的是大数据,所以文件会比较大——》可以定义long类型(在大数据里面自己封装的叫做longWritable类型)
* (2)进行文件中数据的读取:map进行文件中数据的读取(按行读取),一行一行的进行数据获取—-》一行中数据为String类型(在大数据中国自己封装的类型叫做Text类型)
* (3)进行每一行单词的获取:map进行每一行单词的获取—-》要进行映射(单词,数量1)——》这里还要继续写出给reduce—-》需要key的类型(就是单词类型)—-》也就是字符串类型(大数据中为Text)
* (4)同(3):map写出到reduce中value的类型(数量1)—-》数字类型(先定义为int)—-》(大数据中为IntWritable)
* 注意:数量=1–》是因为我们现在写的简单逻辑是一行就看成是一个单词,所以读取一行,就赋值为1
*/
public static class Map1 extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
/**
* value是当前一行的值,需要进行map的过程
* 给当前的值进行数据映射,并且写出到reduce中
* key==>每一行开始的位置,value当前一行的值
* context 上下文对象,通过对象进行数据的写出reduce
*/
// 进行每行数据的读取,每读一行数据-->进行数据的切割(通过空格进行数据的切割-->利用split函数)
String[] s=value.toString().split(" ");
for (String a:s
) {
context.write(new Text(a),new IntWritable(1));
}
}
}
// 先继承Reducer
/**
* 四个范型
* (1)map写入reduce中的数据,key类型—》Text
* (2)map写入reduce中的数据,value类型—》IntWritable
* (3)单词的类型:reduce进行数据合并,把数据写出到磁盘上,格式是(单词,数量)—》先写出单词的类型(key类型)—》字符串—〉Text
* (4)数量的类型:value类型—》LongWritable
*/
public static class Reduce1 extends Reducer<Text,IntWritable,Text,LongWritable> {
/**
* key===>从map中接受的key的类型
* values===>是一个集合,进行当前可以相同时,数据值的存储
* reduce中的数据写出到hdfs上===>通过context进行的写出
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
int count=0;
for (IntWritable i:values
) {
count+=i.get();
}
context.write(key,new LongWritable(count));
}
}
public static void main(String[] args){
// 进行java程序的运行
// hdfs的配置
Configuration conf=new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.246.177:9000");
try {
Job job = Job.getInstance(conf);
// job相关信息
// 设置job的名字
job.setJobName("javawordcount");
// job运行类
job.setJarByClass(Demo2.class);
// job执行map相关信息的配置
job.setMapperClass(Demo2.Map1.class);
// 向reduce输出key的类型
job.setMapOutputKeyClass(Text.class);
// 向rudece输出value的类型
job.setMapOutputValueClass(IntWritable.class);
// job执行reduce的配置
job.setReducerClass(Demo2.Reduce1.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 注意导包import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
FileInputFormat.setInputPaths(job,new Path("/dat.txt"));
FileOutputFormat.setOutputPath(job,new Path("/java2"));
// 提交执行
job.waitForCompletion(true);
} catch (IOException e) {
throw new RuntimeException(e);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
}
}
- 执行结果
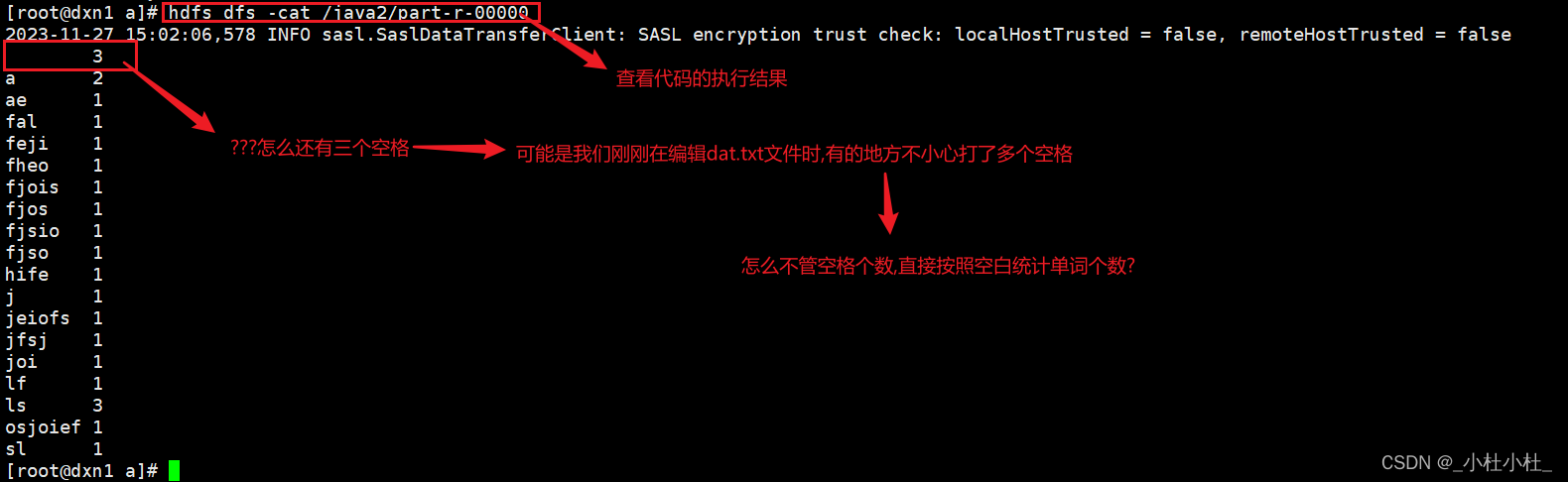
(2) 再次优化(正则表达式)---->按照空白统计单词个数
- 修改部分----Map逻辑部分
//运用了正则表达式 \\s+
String[] s=value.toString().split("\\s+");
(3) 只统计第一个单词的个数
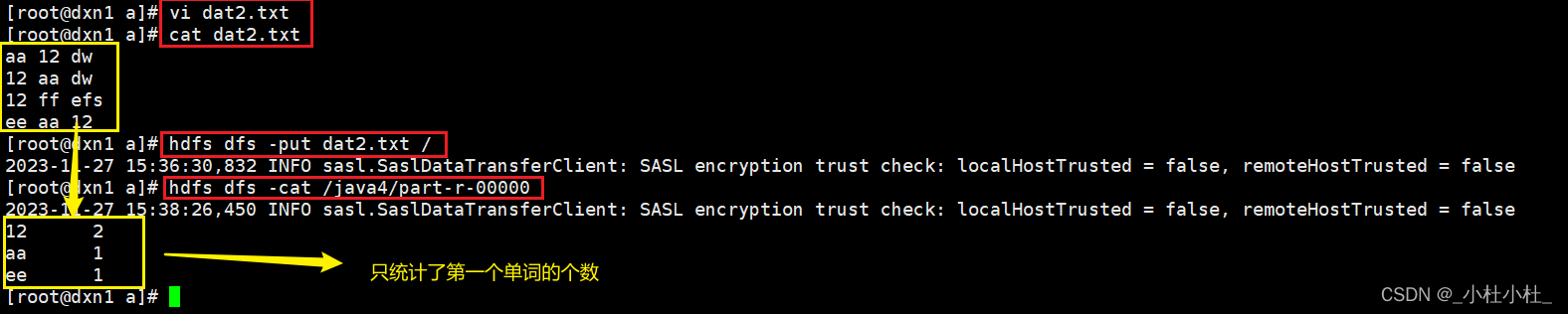
-
方法一 : 利用数组,只取第一个单词
-
修改部分(Map)
String[] s=value.toString().split("\\s+"); //取每一行的第一个单词,进行这个单词的数量统计 context.write(new Text(s[0]),new IntWritable(1)); -
完整代码
package neuedu.test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Demo3 {
// 先继承Mapper
/**
* 四个范型
* (1)进行每一行的位置的记录:map读取指定文件中的数据——》每一行开始的位置,数字进行的记录——》我们现在写的是大数据,所以文件会比较大——》可以定义long类型(在大数据里面自己封装的叫做longWritable类型)
* (2)进行文件中数据的读取:map进行文件中数据的读取(按行读取),一行一行的进行数据获取—-》一行中数据为String类型(在大数据中国自己封装的类型叫做Text类型)
* (3)进行每一行单词的获取:map进行每一行单词的获取—-》要进行映射(单词,数量1)——》这里还要继续写出给reduce—-》需要key的类型(就是单词类型)—-》也就是字符串类型(大数据中为Text)
* (4)同(3):map写出到reduce中value的类型(数量1)—-》数字类型(先定义为int)—-》(大数据中为IntWritable)
* 注意:数量=1–》是因为我们现在写的简单逻辑是一行就看成是一个单词,所以读取一行,就赋值为1
*/
public static class Map1 extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
/**
* value是当前一行的值,需要进行map的过程
* 给当前的值进行数据映射,并且写出到reduce中
* key==>每一行开始的位置,value当前一行的值
* context 上下文对象,通过对象进行数据的写出reduce
*/
// 进行每行数据的读取,每读一行数据-->进行数据的切割(通过空格进行数据的切割-->利用split函数)
String[] s=value.toString().split("\\s+");
// 取每一行的第一个单词,进行这个单词的数量统计
context.write(new Text(s[0]),new IntWritable(1));
}
}
// 先继承Reducer
/**
* 四个范型
* (1)map写入reduce中的数据,key类型—》Text
* (2)map写入reduce中的数据,value类型—》IntWritable
* (3)单词的类型:reduce进行数据合并,把数据写出到磁盘上,格式是(单词,数量)—》先写出单词的类型(key类型)—》字符串—〉Text
* (4)数量的类型:value类型—》LongWritable
*/
public static class Reduce1 extends Reducer<Text,IntWritable,Text,LongWritable> {
/**
* key===>从map中接受的key的类型
* values===>是一个集合,进行当前可以相同时,数据值的存储
* reduce中的数据写出到hdfs上===>通过context进行的写出
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
int count=0;
for (IntWritable i:values
) {
count+=i.get();
}
context.write(key,new LongWritable(count));
}
}
public static void main(String[] args){
// 进行java程序的运行
// hdfs的配置
Configuration conf=new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.246.177:9000");
try {
Job job = Job.getInstance(conf);
// job相关信息
// 设置job的名字
job.setJobName("javawordcount");
// job运行类
job.setJarByClass(Demo3.class);
// job执行map相关信息的配置
job.setMapperClass(Demo3.Map1.class);
// 向reduce输出key的类型
job.setMapOutputKeyClass(Text.class);
// 向rudece输出value的类型
job.setMapOutputValueClass(IntWritable.class);
// job执行reduce的配置
job.setReducerClass(Demo3.Reduce1.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 注意导包import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
FileInputFormat.setInputPaths(job,new Path("/dat2.txt"));
FileOutputFormat.setOutputPath(job,new Path("/java4"));
// 提交执行
job.waitForCompletion(true);
} catch (IOException e) {
throw new RuntimeException(e);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
}
}
- 方法2 : 就是把第一个单词单独提出来–>也就是所谓的key值
- 修改部分:
// main
//用空格进行key 和 value的区分(注意KeyValueLineRecordReader的导包--->lib下的)
conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPARATOR," ");
// 以文本文件的方式进行读取,map的第一个泛型是位置,第二个泛型是当前一行的数据
// job.setInputFormatClass(TextInputFormat.class);//这个是默认的
// 以keyvalue的方式进行数据的读取-->解读 : 以文件每一行开始的单词作为key,后面的单词作为value
job.setInputFormatClass(KeyValueTextInputFormat.class);
//Map
public static class Map1 extends Mapper<Text, Text,Text, IntWritable> {
@Override
protected void map(Text key, Text value,Context context) throws IOException, InterruptedException {
/**
* value是当前一行的值,需要进行map的过程
* 给当前的值进行数据映射,并且写出到reduce中
* key==>每一行开始的位置,value当前一行的值
* context 上下文对象,通过对象进行数据的写出reduce
*/
System.out.println(key);//key是第一个单词-->所以key的类型要改为Text
System.out.println(value);//value是除了第一个单词的后面所有单词
context.write(key,new IntWritable(1));//只输出第一个单词,也就是key
进行每行数据的读取,每读一行数据-->进行数据的切割(通过空格进行数据的切割-->利用split函数)
// String[] s=value.toString().split("\\s+");
取每一行的第一个单词,进行这个单词的数量统计
// context.write(new Text(s[0]),new IntWritable(1));
}
}
- 完整代码
package neuedu.test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueLineRecordReader;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Demo4 {
// 先继承Mapper
/**
* 四个范型
* (1)进行每一行的位置的记录:map读取指定文件中的数据——》每一行开始的位置,数字进行的记录——》我们现在写的是大数据,所以文件会比较大——》可以定义long类型(在大数据里面自己封装的叫做longWritable类型)
* (2)进行文件中数据的读取:map进行文件中数据的读取(按行读取),一行一行的进行数据获取—-》一行中数据为String类型(在大数据中国自己封装的类型叫做Text类型)
* (3)进行每一行单词的获取:map进行每一行单词的获取—-》要进行映射(单词,数量1)——》这里还要继续写出给reduce—-》需要key的类型(就是单词类型)—-》也就是字符串类型(大数据中为Text)
* (4)同(3):map写出到reduce中value的类型(数量1)—-》数字类型(先定义为int)—-》(大数据中为IntWritable)
* 注意:数量=1–》是因为我们现在写的简单逻辑是一行就看成是一个单词,所以读取一行,就赋值为1
*/
public static class Map1 extends Mapper<Text, Text,Text, IntWritable> {
@Override
protected void map(Text key, Text value,Context context) throws IOException, InterruptedException {
/**
* value是当前一行的值,需要进行map的过程
* 给当前的值进行数据映射,并且写出到reduce中
* key==>每一行开始的位置,value当前一行的值
* context 上下文对象,通过对象进行数据的写出reduce
*/
System.out.println(key);//key是第一个单词-->所以key的类型要改为Text
System.out.println(value);//value是除了第一个单词的后面所有单词
context.write(key,new IntWritable(1));//只输出第一个单词,也就是key
进行每行数据的读取,每读一行数据-->进行数据的切割(通过空格进行数据的切割-->利用split函数)
// String[] s=value.toString().split("\\s+");
取每一行的第一个单词,进行这个单词的数量统计
// context.write(new Text(s[0]),new IntWritable(1));
}
}
// 先继承Reducer
/**
* 四个范型
* (1)map写入reduce中的数据,key类型—》Text
* (2)map写入reduce中的数据,value类型—》IntWritable
* (3)单词的类型:reduce进行数据合并,把数据写出到磁盘上,格式是(单词,数量)—》先写出单词的类型(key类型)—》字符串—〉Text
* (4)数量的类型:value类型—》LongWritable
*/
public static class Reduce1 extends Reducer<Text,IntWritable,Text,LongWritable> {
/**
* key===>从map中接受的key的类型
* values===>是一个集合,进行当前可以相同时,数据值的存储
* reduce中的数据写出到hdfs上===>通过context进行的写出
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
int count=0;
for (IntWritable i:values
) {
count+=i.get();
}
context.write(key,new LongWritable(count));
}
}
public static void main(String[] args){
// 进行java程序的运行
// hdfs的配置
Configuration conf=new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.246.177:9000");
//用空格进行key 和 value的区分(注意KeyValueLineRecordReader的导包--->lib下的)
conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPARATOR," ");
try {
Job job = Job.getInstance(conf);
// job相关信息
// 设置job的名字
job.setJobName("javawordcount");
// job运行类
job.setJarByClass(Demo4.class);
// job执行map相关信息的配置
job.setMapperClass(Demo4.Map1.class);
// 向reduce输出key的类型
job.setMapOutputKeyClass(Text.class);
// 向rudece输出value的类型
job.setMapOutputValueClass(IntWritable.class);
// job执行reduce的配置
job.setReducerClass(Demo4.Reduce1.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 以文本文件的方式进行读取,map的第一个泛型是位置,第二个泛型是当前一行的数据
// job.setInputFormatClass(TextInputFormat.class);//这个是默认的
// 以keyvalue的方式进行数据的读取-->解读 : 以文件每一行开始的单词作为key,后面的单词作为value
//注意KeyValueTextInputFormat的导包-->lib里的
job.setInputFormatClass(KeyValueTextInputFormat.class);
// 注意导包import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
FileInputFormat.setInputPaths(job,new Path("/dat2.txt"));
FileOutputFormat.setOutputPath(job,new Path("/java5"));
// 提交执行
job.waitForCompletion(true);
} catch (IOException e) {
throw new RuntimeException(e);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
}
}














 299
299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









