







(1)引言
难得的暑假肯定要做做项目写写博客啦。本次带来的是LangChain下的ChatGLM-6B-INT4量化后的大模型的本地部署,这将是我专栏:基于ChatGLM研究学习的开篇之作,以后这个系列也会继续更新。这篇文章也会带读者入门大模型,本文原创,为了记录和分享我在学习时的思想感悟。
ChatGLM-6B-INT4是对开源大模型ChatGLM的量化之后的版本,更容易在本地部署,所需的配置较低。相关概念都不说了,它类似于ChatGPT,不过很好的是ChatGLM整个模型在GitHub和Huggingface上开源。但虽然它开源,但是它的部署仍然特别困难,会遇到很多问题。接下来,让我们走进人工智能的世界!
首先先说明一下LangChain下的ChatGLM-6B本地部署的实现逻辑(转自GitHub):


我们解读一下本图的含义:LangChain我们可以理解成一种内部的逻辑,在这个框架下我们对于用户输入的问题和本地知识库中的问题都通过Embedding模型(这里我们选择的是Huggingface上面的 text2vec-large-chinese)进行一个向量化并生成存储于本地的向量库,对于向量库和提问的问题向量化之后的向量进行相似度匹配,最后通过Prompt的优化并送入LLM大语言模型(这里我们选择的是ChatGLM-6B-INT4)中生成回答。
以下是我的一个分析和理解的过程:

我们了解了基本原理之后就可以开始搭建环境并创建项目了,我们需要以下核心软件:
(1)Anaconda:用于构建虚拟环境,防止python的包的冲突,anaconda的集成环境比较好用。
(2)Pycharm:用于管理项目和修改代码,区域和模块化搭建大模型的环境。(最好专业版)。
我们做项目的时候尽量将所有需要文件打包进一个文件夹。这里为了做本地部署,我外接了一个1T移动硬盘。
(2)虚拟环境的创建
使用Anaconda Powershell Prompt首先转到我们的外接硬盘E:\。
之后输入命令: conda create -n ChatGLM-6B python=3.9。

之后我们就可以在Anaconda的envs文件夹下看到我们所创建的名称为ChatGLM-6B的虚拟环境,解释器为python3.9版本。
(3)pycharm的虚拟环境管理
这一点很多博客也说过,这里不加强调。大体上就是将pycharm中的解释器和环境换成刚刚的生成的虚拟环境(先忽略这里的软件包,之后会讲):

成功之后我们在pycharm的终端部分也改成虚拟环境的部分,之后方便我们在虚拟环境之下pip install等操作。虚拟环境就是为了防止各个其他外来因素对项目的影响,所以我们之后的操作终端尽量保持在虚拟环境之下。
(4)大模型开源的下载
首先是langchain-ChatGLM:
之后是Huggingface上的两个包:
(1)量化之后的chatglm-6b-int4:
THUDM/chatglm2-6b-int4 at main (huggingface.co)
(2)Embedding模型:
GanymedeNil/text2vec-large-chinese at main (huggingface.co)
因为我们使用的是cpu,还要下载一个优化包(GCC):
将我们的资源整合到我们的项目下:

(5)本地搭建
因为这个官方也没有教程,对于小白来说很不友好,所以我大致总结一下我的摸索过程:
首先这个模型所需要的所有的包都在requirements.txt中了,所以我们直接在终端(注意是虚拟还环境)输入:
pip install -r (文件在电脑中的绝对路径) (文件名+后缀)之后我们就可以看见终端中在飞速下载所需要的包。
下一步就是修改langchain-ChatGLM-master下model_config.py文件中的参数:
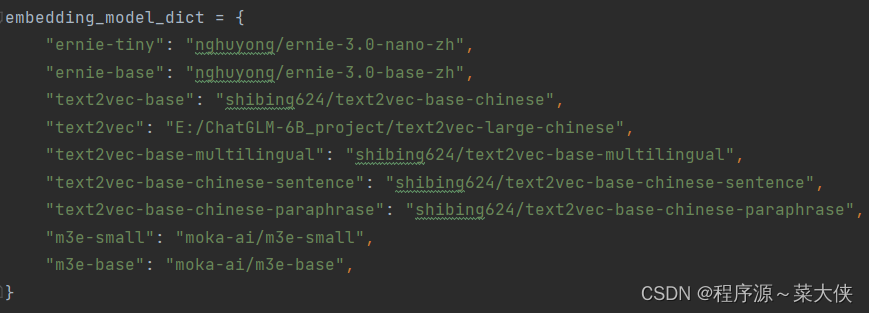
因为我们使用的是text2vec,所以我们把它的后面替换成绝对的路径:
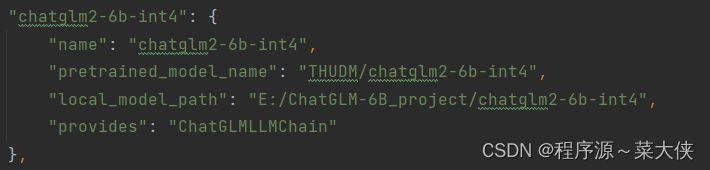
同理,我们修改LLM模型为我们使用的chatglm2-6b-int4:
第一次做项目不懂时,要学会去GitHub上找同一个项目下的issue:
因为这里部署的是量化后的模型,经过多次尝试并搜集资料后我们需要修改以下参数的精度:
先找到loader文件:

使用ctrl+F开启搜索栏并查找torch.float将后面参数全部改成32。

之后大概率还会出现一个问题我就不写了放链接:
(6)本地知识库问答
完成了以上操作,我们就可以开始跑模型了,可能会出现很多warning,但是不需要管。我们找到cli_demo开始运行。因为我们是cpu运行,所以可能比较慢:

开始运行:

之后模型加载67.93s之后就会提示我们输入语料的绝对路径:

因为这里支持pdf,所以我放进入了一份BP神经网络详解与实例的pdf数学建模课件,大概40多页,之后中文分词器就会对其进行处理并方便之后的向量化,在本地构建了vectorstore向量库:

向量化之后会提醒我们输入问题,我输入了问题:什么是BP神经网络?
它产生的回答:

可以见到它的回答效果很不好,并且有重复的语句,有些地方还是文不对题,这也给我们之后留下了更多进步的空间。
(7)未来展望
在未来,我们要对于分词器、输入长度、temperature、prompt等进行调整,让模型向我们想要的方向进行改进,进而优化模型的问答效果。















 4555
4555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









