






自学中,此篇文章仅供参考,若不正确请指明,谢谢
获取
1.从git取得yolo源码
链接如下
git clone https://github.com/ultralytics/ultralytics2.下载yolov8对应的安装库
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple训练数据集
1.创建文件
创建格式(detect,seg)
test
images train
data
labels tarin
test
Classify
train ---类别名--images
data
test ----类别名--images
2.进行训练
1.这个是在原有pt的模型基础上,进行训练
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=6402.只用自己的进行训练
yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=6403.进行预测
yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model5.若用engine模型,pt转engine模型
yolo export model=path/to/best.pt format=onnx # export custom trained model参数设置
在训练和预测过程中都可应用参数,让配置更加准确
1.train(常用参数)
model: # 设置模型。格式因任务类型而异。是从头开始训练.yaml还是迁移学习.pt
data: # 设置数据,支持多数类型 一办事yaml类型的数据
epochs: # 可设置适合自己的轮数
patience: # 设置多少次没有一个好的结果就会停止训练
imgsz: # 图像数据的大小
device: # 设备的选择 cuda device=0 or device=0,1,2,3 or device=cpu
workers: 8 # 每个进程使用的cpu的工作环境数
project: project name
pretrained: False # 是否使用预训练模型,如果有之前的模型,可以使用之前的模型继续进行训练
verbose: True # whether to print verbose output
single_cls: False # 将多类数据作为单类进行训练
image_weights: False # 使用加权图像选择进行训练马赛克增强
close_mosaic: 10 # 最后几个周期禁用
resume: False # 从上一个检查点开始恢复培训
2.预测参数
source: # 进行测试饿数据源
show: False # 查看预测图片
save_txt: False # 是否在输出结果中打印txt信息
save_conf: False # 是否在输出结果中打印置信度
save_crop: False # 保存偏短图像的结果
hide_labels: False # 隐藏坐标
hide_conf: False #是否隐藏置信度
vid_stride: 1 # 输入视频帧率步长
line_thickness: 3 # bounding box thickness (pixels)
visualize: False # 可视化模型特征
augment: False # apply image augmentation to prediction sources
agnostic_nms: False #不同种类的抑制
retina_masks: False #分割:高分辨率掩模
boxes: True # Show boxes in segmentation predictions
结果查看
1.文件构成
2.各部分解释
1)weights

里面包含训练best.pt和last.pt两部分,大部分的情况可以选取最好的.pt文件进行训练
2)args.yaml
里面为此次训练的训练参数
3)confusion_matrix.png
混淆矩阵

x轴是真实类别,y轴是预测类别,根据这张图,我们可以看出分类模型发生的错误,和正在发生的错误。(例如:对于目前这张图来说,11类是效果最不好的)
那我们如何看类表格呢,我们可以现看只有简单几类的情况

整体表格分为四部分
| 混淆矩阵 | 真实为0 | 真实为1 |
| 预测为0 | TN | FP |
| 预测为1 | FN | TP |
正确结果为TN和TP的数值。错误结果为FN和TP
由此我们可以查看上图多类的结果
我们可以根据此,推算出很多公式
1.精确度:预测为正的样本有多少是正确的
precision=TP/(TP+FP)
2.召回率:真实为正的样本有多少被正确预测为正
recall=TP/(FN+TP)
3.F1值 综合考虑精确度和召回率的数值(下文有提到)
4.准确度:所有样本中模型正确预测的比例
accuracy:(TN+TP)/(TN+FP+FN+TP)
4)Confusion Matrix Normalized

5)F1-Confidence Curve

横坐标是置信度,纵坐标是F1
对于不同的模型,有很多的准确性和回归,这样我们需要引入F1参数,来选择最优解
最直接的办法就是取Precision与Recall的平均值,但取平均值并不可取。因为有时二者有一个极高,一个极低时,这样平均值是高的,但实际的效果并不会好。。通过F1-score的方式来权衡Precision与Recall,可以有效的避免短板效应,这在数学上被称为调和平均数。
一般我们认为,一条曲线(A)包含另一条曲线(B),我们认为A曲线效果更好
这个主要讲的是置信度与每一种类之间的关系。对于所有的种类,最好的结果置信度在0.259.
6)Precision-Confidence Curve
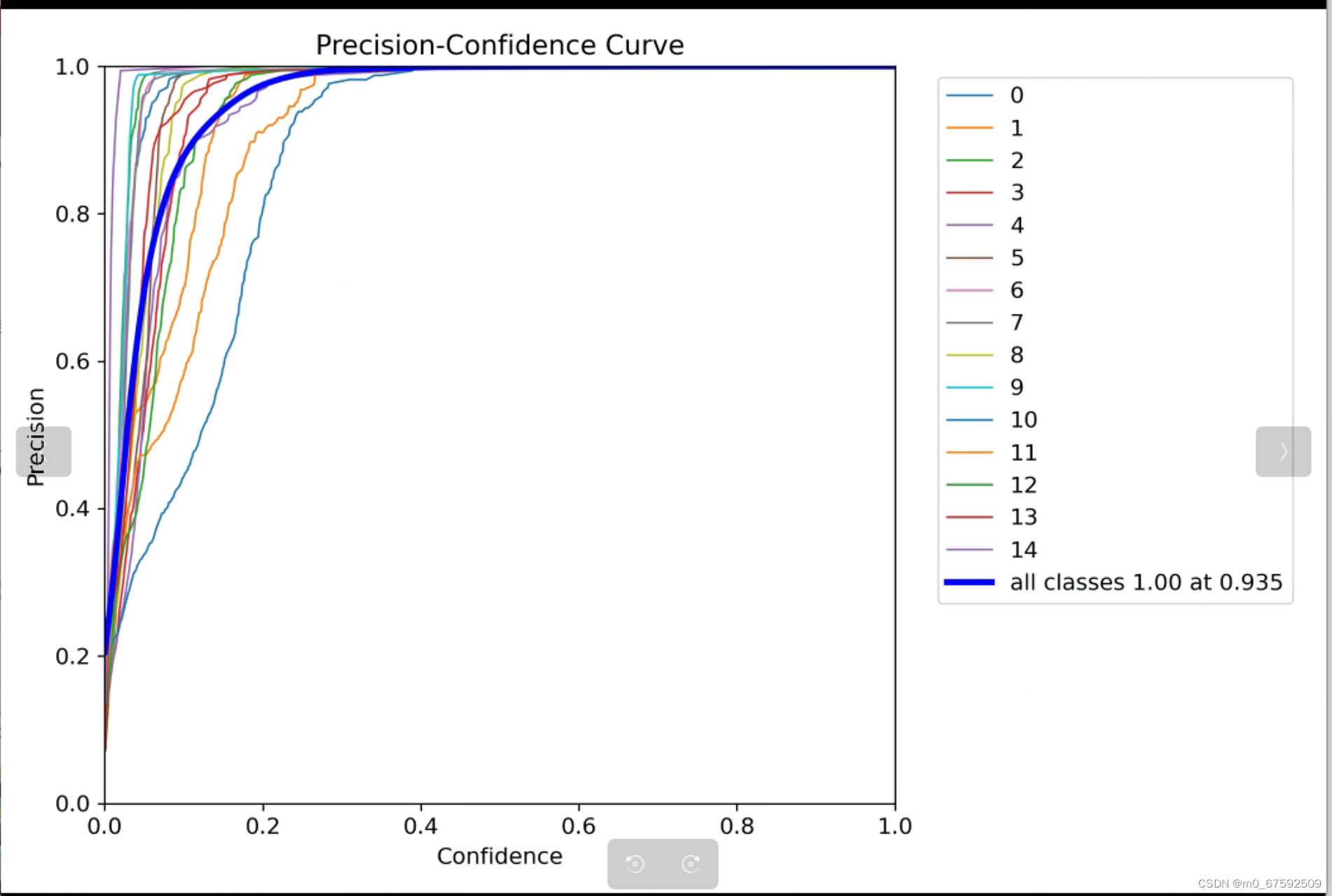
这幅图主要是置信度与准确率的关系,在置信度为0.935的情况下,准确率为1
7)Precison-Recall Curve

主要是回归和置信度之间的关系
-----持续更新














 3850
3850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









