






1.介绍
基于给定的植物百科数据,实现植物数据的管理与分析。 植物相关数据存储在8个文本文件中,相应的文件信息说明如表1所示。其中,各个文件中不同的数据项之间均使用“#”分隔,如文件plant.txt中每一植物的植物名称、学名、分布地、详情描述之间使用“#”分隔,而分布地可能包括多个省份,各省份之间使用“@”分隔。图1给出了文件plant.txt中植物“独叶草”对应的数据示例。

“植物百科数据的管理与分析”实践项目由植物基本信息管理模块、植物分布地分析模块和植物从属关系检索模块三个子模块组成。各功能模块具体功能如下所示:
(1)增加、删除和修改植物信息:从plant.txt中读取植物的基本信息,创建一个植物信息的链表,基于该链表,实现植物基本信息的增加、删除和修改功能。
(2)基于顺序表的顺序查找:从plant.txt中读取植物的基本信息,实现基于顺序表的顺序查找。
(3)基于链表的顺序查找:从plant.txt中读取植物的基本信息,实现基于链表的顺序查找。
(4)基于顺序表的折半查找:从plant.txt中读取植物的基本信息,实现基于顺序表的折半查找。
(5)基于二叉排序树的查找:从plant.txt中读取植物的基本信息,实现基于二叉排序树的查找。
(6)基于开放地址法的散列查找:从plant.txt中读取植物的基本信息,实现基于开放地址法的散列查找。
(7)基于链地址法的散列查找:从plant.txt中读取植物的基本信息,实现基于链地址法的散列查找。
(8)基于BF算法的植物关键信息查询:编写一个基于字符串模式匹配算法的植物关键信息查询程序。
(9)基于KMP算法的植物关键信息查询:编写一个基于字符串模式匹配算法的植物关键信息查询程序。
(10)直接插入排序:从plant.txt中读取植物的基本信息,使用直接插入排序策略,将植物信息按植物学名的字典序进行排列。
(11)折半插入排序:从plant.txt中读取植物的基本信息,使用折半插入排序策略,将植物信息按植物学名的字典序进行排列。
(12)简单选择排序:从plant.txt中读取植物的基本信息,使用简单选择排序策略,将植物信息按植物学名的字典序进行排列。
(13)冒泡排序:从plant.txt中读取植物的基本信息,使用冒泡排序策略,将植物信息按植物学名的字典序进行排列。
(14)快速排序:从plant.txt中读取植物的基本信息,使用快速排序策略,将植物信息按植物学名的字典序进行排列。
(15)植物移植最短路径分析:当需要对植物进行跨省移植时,花费的成本与运载植物的路程长度息息相关(这里暂不考虑气候等环境因素对植物生长的影响)。用户可以通过输入植物名称和待移植的目的地,得到运输该植物需要花费的最短路径。其中,若移植的目的省份中已有该植物的分布,则输出“该省份已存在,无需移植”;否则,输出移植的出发地和抵达目的省份最短路径长度。
(16)可移植路径分析:当在某地发现一株新植物时,需要及时对其进行易地保护。易地移植的过程中,若路程过长,植物容易在运载途中死亡。用户输入新植物发现地、移植目的地及该植物能接受的最大路程,通过对省份图进行遍历,输出所有可行的运输路径。
(17)植物分类树构建:根据构建出的植物分类树和植物名称,得到该植物的属、科、目、纲、门、界信息
(18)同属植物信息检索:根据构建出的植物分类树和植物名称,得到与该植物同属的其它植物。
(19)下属植物信息检索:根据输入的植物类别(门、纲、目、科、属任何一个),输出隶属于该类别的所有植物。
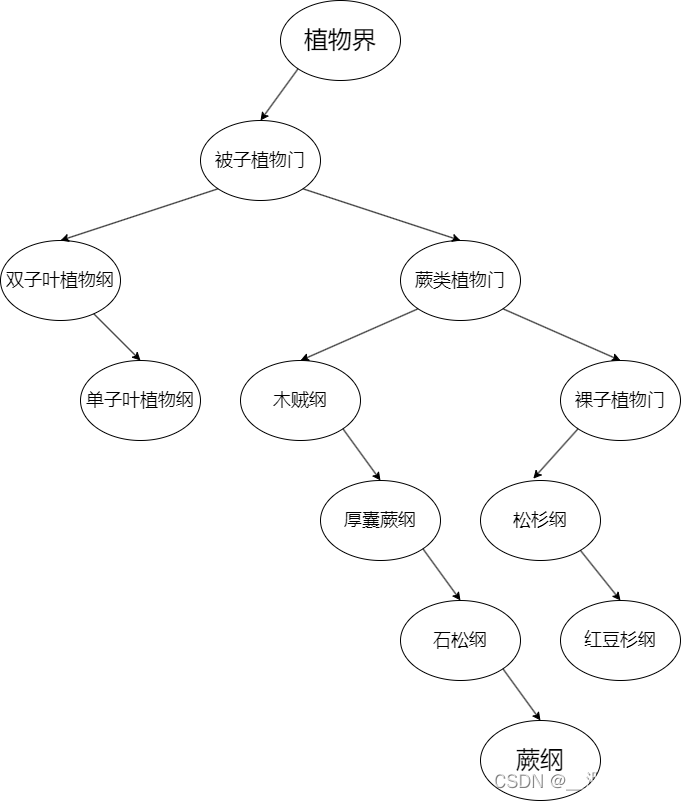
2.BiTree结构(植物分类树)
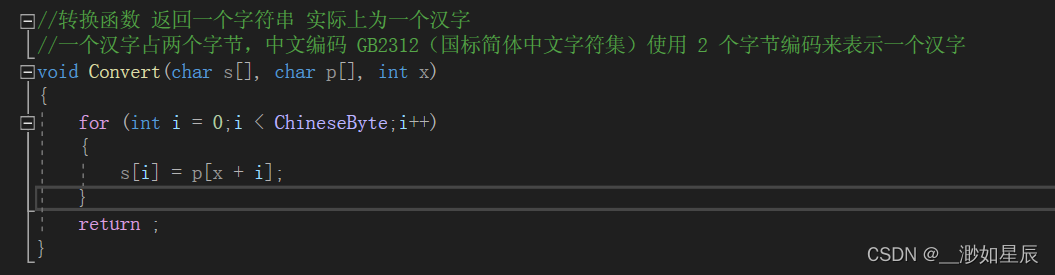
3.数组的汉字存储问题
汉字存储占用 空间大小 与使用的 编码方式 有关。
常见的中文编码 GB2312(国标简体中文字符集)和 GBK(国标扩展)使用 2 个字节编码来表示一个汉字,不常用的 GB18030 使用 4 个字节编码来表示一个汉字,更通用的 UTF-8 编码使用 3 个字节编码来表示一个汉字。

















 2893
2893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









