







一、索引
1、索引的概念
索引(index)是一种特殊的文件,包含着对数据库表里所有记录的引用指针。可以对表中的一列或多列创建索引。
2、索引的作用
索引的最大作用:加快数据检索的速度,提高查询数据的效率。
一个表中的索引,类似于一本书中的目录,通过书籍的目录,我们可以快速找到需要查看的内容;如果书籍没有目录,我们就只能一页一页地翻阅查找(遍历),效率比较低。
3、索引的缺陷
任何事物都是有利也有弊,索引虽然提高了查询效率,但是也有两个缺陷:
(1)索引会消耗更多空间;
(2)当对表中数据进行增加、修改、删除的时候,对应的索引也要进行维护,因此降低了数据维护的速度。
虽然使用索引会付出一些代价,但是大多数情况下,还是值得使用索引的。因为在大多数情况下,查询操作的频率远高于增、删、改的频率。
4、索引的使用
在对列进行唯一约束(UNIQUE)或主键约束(PRIMARY KEY)或外键约束(FOREIGN KEY)时,会自动创建对应列的索引。
4.1 查看索引
我们先创建一张带有主键约束列的表:
create table student(id int primary key,name varchar(20));查看索引的操作:show index from 表名;
查看上表中的索引:
show index from student;
4.2 创建索引
创建索引的操作:create index 索引名 表名(列名);
创建student表中name列的索引:
create index name_index on student(name);再次查看表中索引:

注意:
创建索引是一个低效操作:如果表中数据过多,创建索引操作可能会非常耗时,并带来大量的硬盘I/O,甚至可能会卡死数据库,所以当表中数据过多时,创建索引也是一个比较危险的操作。
4.3 删除索引
删除索引的操作:drop index 索引名 on 表名;
删除student表中name列的索引:
drop index name_index on student;再次查看表中索引:

注意:
删除索引操作和创建索引操作类似,都是低效操作。对于数据量比较大的表,应该在建表之初,就创建好对应的索引,以免在表中数据量过大时,再进行创建、删除索引的操作。
5、索引背后的数据结构
索引背后有多种数据结构,但最核心的是: B+树
在认识B+树之前,需要先认识B树:
B树是一棵N叉搜索树,每个节点上,至多有N-1个值,N-1个值就可以将数据范围分成N份,这样就可以降低树的高度,从而减少查询次数,I/O次数,提高查询效率。
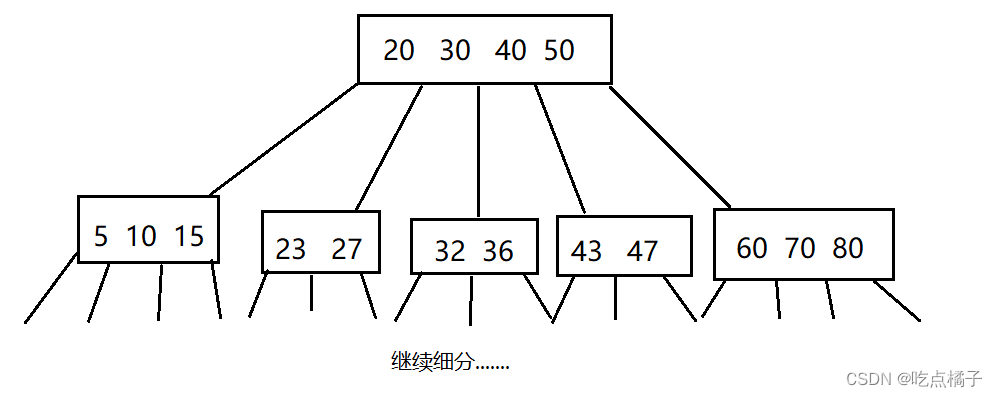
B+树是在B树的基础上改进而来的,本质上也是一棵N叉搜索树:
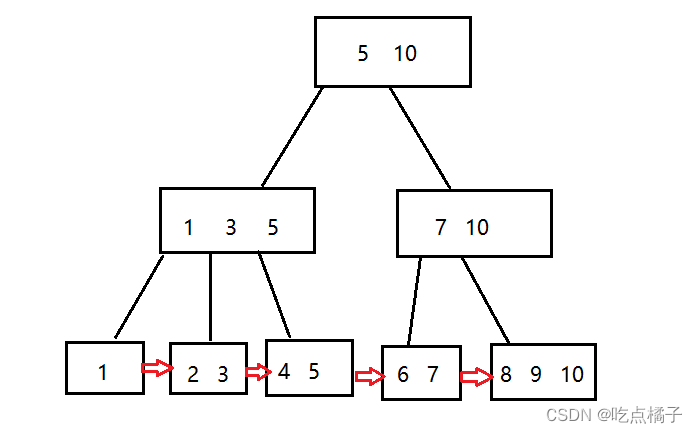
B树和B+树的区别:
(1)B树每个节点的N-1个值,把数据分成N个区间范围;
B+树每个节点的N个值,把数据分成N个区间范围。
(2)B树中的值不会重复出现;
B+树中,父节点的值,会在子节点中以最大值或最小值的形式出现。
(3)B+树中,所有的数据集合都会在叶子节点体现出来,并以链表的形式相连在一起,这样做可以有效地提高范围查询的效率。
正因为叶子节点是全集数据,所以我们可以把一行中每一列的数据都关联在叶子节点上,非叶子节点上,只需要保存索引列即可。非叶子节点相比于完整的数据集合来说,占用的空间非常小,就可以在内存中缓存,因此通过B+树进行查询操作,又进一步减少了硬盘的I/O。
二、事务
1、事务的概念
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败(原子性),事务就是用来保证原子性的。
2、事务的特性
2.1 原子性
原子性是事务存在的意义,它能够把多个SQL语句打包成一个整体,要么全部执行完,要么一个都不执行(在执行过程中出错,全部回滚到执行之前的状态)。
2.2 一致性
事务在执行前后,数据处在“一致”的状态(要么都处在执行前的状态,要么都处在执行后的状态)。
2.3 持久性
事务在执行后,改动的都是硬盘中的数据,不会随着程序重启或主机重启而丢失。
2.4 隔离性
多个事务在并发执行的时候,事务之间能够保持“隔离”,互不干扰。隔离性存在的意义就是让事务在并发执行的过程中中,尽量不出问题(问题在可控范围之内)。
并发执行可能会带来的问题:
(1 )脏读
假设事务A在修改一份数据,而事务B读取了这份数据,当事务A提交修改后的数据时,修改后的数据很可能和原来的数据不同,此时事务B读到的数据就是“无效的数据”,这种情况就是“脏读”,读的是脏数据(临时的数据,不一定是最终的结果)。
要解决脏读问题,就需要对“写”操作进行“加锁”,事务A在进行“写”操作的时候,其他事务不可以读取事务A正在“写”的数据,等到事务A“写”完之后才可以读取。
对“写”操作加锁后,提高了事务之间的隔离性,即数据的准确性提高了,同时也降低了事务的并发性,因此事务执行的效率也降低了。
(2) 不可重复读
在对“写”操作加锁后,当事务B在读取数据时,事务A又对这份数据进行了“写”操作,所以,事务B在事务A“写”之前读到的数据很可能和事务A“写”之后读到的数据不一样,这种情况就是“不可重复读”,即在一个事务中,多次读取同一份数据,发现读取到的结果不一样(数据在读的过程中被其他事务修改了)。
为了解决不可重复读的问题,需要使用“读”加锁:当事务B在读取数据时,其他数据不可以对这份数据进行“写”操作。
对“读”和“写”都进行加锁后,事务之间的隔离性进一步提高,并发性也进一步降低。
(3) 幻读
在对“读”和“写”都加锁后,假设事务B在读取文件1,而事务A对文件2进行“写”操作,虽然对文件2进行“写”操作不会影响到事务B正在“读”的文件1,但是最终的结果集发生了改变,本来事务B在读之前路径下只有一个文件,但是当事务B再次读的时候发现有两个文件了。这种情况称为“幻读”,是“不可重复读”的特殊情况。
为了解决“幻读”问题,就要实施“串行化”:事务B在读取数据时,其他事务不可以执行。
此时,并发程度降到最低,效率也降到最低,但是事务局的隔离性达到最高,数据的准确性也最高。
2.5 隔离级别:
上述脏读、不可重复读、幻读都是事务在并发执行过程中,可能出现的问题,但出现这些问题,并不一定是BUG,是否为BUG需要看实际需求中对数据的准确性的要求程度。
MySQL中提供了“隔离级别”选项,共有四个档位 :
(1) read uncommitted
允许事务读未提交的数据。
此时,事务间的并发程度最高,隔离性最低。可能存在脏读、不可重复读、幻读问题。
(2) read commited
对“写”操作加锁。
事务间的并发程度降低,隔离性提升。解决了脏读问题,可能存在不可重复读、幻读问题。
(3) repeatable read(默认隔离级别)
对“读”和“写”操作都加锁。
事务间的并发程度再次降低,隔离性再次提升。解决了脏读、不可重复度问题,可能存在幻读问题。
(4) serializable
严格执行串行化。
此时,事务间的并发程度最低,隔离性最高。解决了脏读、不可重复读、幻读问题。
隔离级别可以在MySQL的配置文件my.ini中进行设置,根据不同的需求,设置不同的级别。
















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











