









一、实验目的:
设计、编制并调试一个词法分析程序,加深对词法分析原理的理解
二、实验要求:
1.待分析的简单语言的词法
(1)关键字:begin if then while do end
所有的关键字都是小写。
(2)运算符和界符:= + - * / < <= <> > >= = ; ( ) #
(3)其他单词是标识符(ID)和整型常数(NUM),通过以下正规式定义:
ID= letter (letter l digit)*
NUM = digit digit*
(4)空格由空白、制表符和换行符组成。空格一般用来分隔ID、NUM、运算符、界符 和关键字,词法分析阶段通常被忽略。
2.各种单词符号对应的种别码
表C.1各种单词符号对应的种别码种别码
| 单词符号 | 种别码 | 单词符号 | 种别码 |
| begin | 1 | : | 17 |
| if | 2 | : = | 18 |
| then | 3 | < | 20 |
| while | 4 | <> | 21 |
| do | 5 | <= | 22 |
| end | 6 | > | 23 |
| letter(letter | digit)* | 10 | >= | 24 |
| digit digit* | 11 | = | 25 |
| + | 13 | ; | 26 |
| - | 14 | ( | 27 |
| * | 15 | ) | 28 |
| / | 16 | # | 0 |
3.词法分析程序的功能
输入:所给文法的源程序字符串
输出:二元组(syn,token或sum)构成的序列
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
例如:对源程序
begin x := 9; if ×>0 then x := 2 * x + 1 / 3 ; end #
的源文件,经词法分析后输出如下序列:
(1 , begin)(10 , ’x’)(18 , : =)(11 , 9)(26 , ; )(2 , if)…
三、实验算法思想:
算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字种类,拼出相应的单词符号。
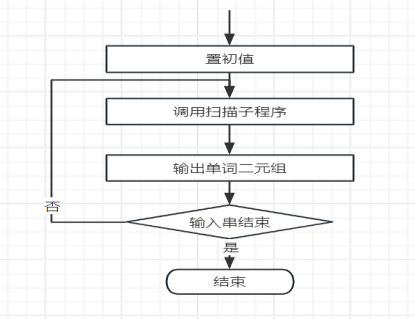
图C.1 词法分析主程序示意图
1.主程序示意图
主程序示意图如图C.1所示。其中初值包括如下两个方面。
(1)关键字表的初值。
关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。如能查到匹配的单词,则该单词为关键字,否则为一般标识符。关键字表为一个字符串数组,其描述如下:
char * rwtab [6] = {"begin","if"."then", "while","do","end"};
(2)程序中需要用到的主要变量为syn, token和sum。
2. 扫描子程序的算法思想
首先设置3个变量:①token用来存放构成单词符号的字符串; sum用来存放整型单河;3 syn用来存放单词符号的种别码。扫描子程序主要部分流程如图C.2所示。
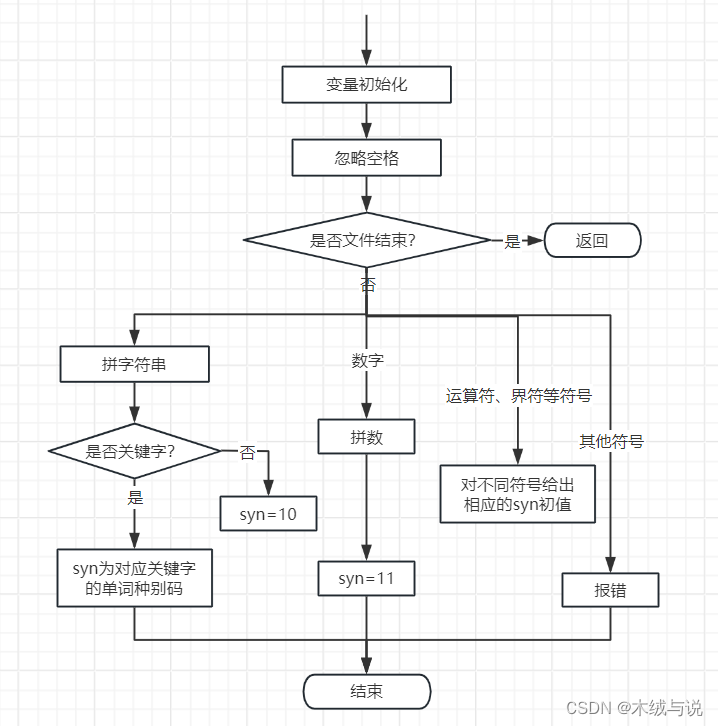
图C.2 词法分析程序流程
四、实验源代码:
#include<stdio.h>
#include<iostream>
#include<stdlib.h>
#include<string.h>
#define _KEY_WORD_END "waiting fou your expanding"/*定义关键字的结束标志*/
using namespace std;
typedef struct
{
int typenum; /*种别码*/
char* word;
}WORD;
char input[255]; /*源程序缓字符冲区*/
char token[255] = ""; /*单词缓冲区*/
int p_input; /*源程序字符指针*/
int p_token; /*单词缓冲区指针*/
char ch;
char* rwtab[] = { "begin","if","then","while","do","end",_KEY_WORD_END };
WORD* scaner(); /*词法扫描函数,获得一个单词*/
void main()
{
int over = 1;
int count = 0;
WORD* oneword = new WORD;
printf("Enter Your words(end with #):");
scanf("%[^#]s", input); /*输入源程序字符串到缓冲区,以#结束*/
p_input = 0;
printf("词法分析结果是:\n\n");
while (over < 1000 && over != -1)
{
oneword = scaner();
if (oneword->word == "OVER")
break;
else if (oneword->typenum < 1000)
printf("(%d,%s) ", oneword->typenum, oneword->word);
over = oneword->typenum;
count++;
if (count % 6 == 0) printf("\n");//每六行输出
}
system("pause");
}
char m_getch() /*从输入源读一个字符到CH中*/
{
ch = input[p_input];
p_input = p_input + 1;
return ch;
}
void getbc() /*去掉空白字符*/
{
while (ch == ' ' || ch == 10)
{
ch = input[p_input];
p_input = p_input + 1;
}
}
void concat() /*拼接单词*/
{
token[p_token] = ch;
p_token = p_token + 1;
token[p_token] = '\0';
}
int letter()/*判断是否是字母*/
{
if (ch >= 'a' && ch <= 'z' || ch >= 'A' && ch <= 'Z')
return 1;
else return 0;
}
int digit()/*判断是否是数字*/
{
if (ch >= '0' && ch <= '9')
return 1;
else return 0;
}
int reserve()/*检索关键字表格*/
{
int i = 0;
while (strcmp(rwtab[i], _KEY_WORD_END))
{
if (!strcmp(rwtab[i], token))
{
return i + 1;
}
i = i + 1;
}
return 10;
}
void retract()/*回退一个字符*/
{
p_input = p_input - 1;
}
char* dtb()
{
return NULL;
}
WORD* scaner()/*词法扫描程序*/
{
WORD* myword = new WORD;
myword->typenum = 10;
myword->word = " ";
p_token = 0;
m_getch();
getbc();
if (letter())
{
while (letter() || digit())
{
concat();
m_getch();
}
retract();
myword->typenum = reserve();
myword->word = token;
return myword;
}
else if (digit())
{
while (digit())
{
concat();
m_getch();
}
retract();
myword->typenum = 11;
myword->word = token;
return myword;
}
else switch (ch)
{
case'=': m_getch();
if (ch == '=')
{
myword->typenum = 29;
myword->word = "==";
return myword;
}
retract();
myword->typenum = 25;
myword->word = "=";
return myword;
break;
case'+':myword->typenum = 13;
myword->word = "+";
return myword;
break;
case'-':myword->typenum = 14;
myword->word = "-";
return myword;
break;
case'*':myword->typenum = 15;
myword->word = "*";
return myword;
break;
case'/':myword->typenum = 16;
myword->word = "/";
return myword;
break;
case'(':myword->typenum = 27;
myword->word = "(";
return myword;
break;
case')':myword->typenum = 28;
myword->word = ")";
return myword;
break;
case'[':myword->typenum = 30;
myword->word = "[";
return myword;
break;
case']':myword->typenum = 31;
myword->word = "]";
return myword;
break;
case'{':myword->typenum = 32;
myword->word = "{";
return myword;
break;
case'}':myword->typenum = 33;
myword->word = "}";
return myword;
break;
case',':myword->typenum = 34;
myword->word = ",";
return myword;
break;
case':':
if (input[p_input] == '=')
{
myword->typenum = 18;
myword->word = ":=";
return myword;
}
else
myword->typenum = 17;
myword->word = ":";
return myword;
break;
case';':myword->typenum = 26;
myword->word = ";";
return myword;
break;
case'>':
m_getch();
if (ch == '=')
{
myword->typenum = 24;
myword->word = ">=";
return myword;
}
retract();
myword->typenum = 23;
myword->word = ">";
return myword;
break;
case'<':
m_getch();
if (ch == '=')
{
myword->typenum = 22;
myword->word = "<=";
return myword;
}
retract();
myword->typenum = 20;
myword->word = "<";
return myword;
break;
case'!':
m_getch();
if (ch == '=')
{
myword->typenum = 40;
myword->word = "!=";
return myword;
}
retract();
myword->typenum = -1;
myword->word = "ERROR";
return myword;
break;
case'\0':
myword->typenum = 100;
myword->word = "OVER";
return myword;
break;
default:
myword->typenum = -1;
myword->word = "ERROR";
return myword;
}
}
五、实验结果:
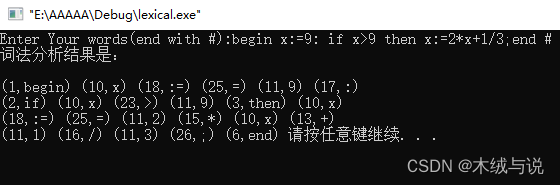















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









