







Transformer架构
纯基于self-attention和普通attention的架构,类比加了attention的seq2seq来看,没有RNN。Multi-head attention是自注意力。PositionwiseFFN全连接。embedding后得到n*d的矩阵(n个token,每个token向量长度d)

多头注意力 Multi-head attention

有点像卷积里的对输出通道,但这里已经有多通道,输出的n*d(n序列长度,d每个token的长度),d相当于通道。那就只能“多头”。key,value,query是长为d的向量。
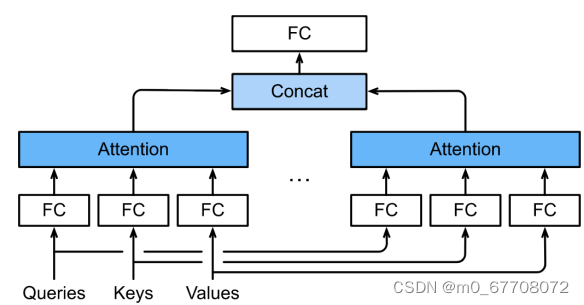
多头注意力使用h个独立的注意力池化。上图有2个head,通常query/key/value经过全连接层维度变小,concat是在特征维度上concat。
数学上看多头注意力

带有掩码的多头注意力 Masked multi-head attention
attention没有时间信息,第i个输出可以看到后面的信息,这不合理,这在编码没关系,但解码不应该事先看到本身以及之后的元素,所以用掩码(valid length来做)。具体:
![]()
基于位置的前馈网络 PositionwiseFFN

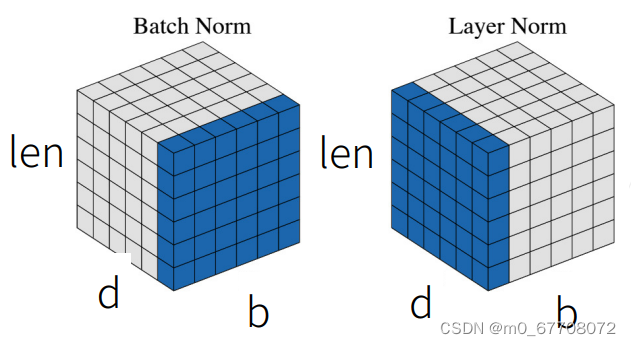
b:batch size n:序列长度 d:每个token的维度
基于位置的前馈网络对每一个位置(也就是每一个token)使用同样的全连接,这就是称前馈网络是基于位置的原因。
为什么要将输入形状由(b,n,d)变成(bn,d)?因为一个模型应该要可以处理任意长度的序列,所以n不可以作为一个单独维度,它想对每个序列中的每个token(长度d)作用一个全连接。这里两个全连接层相当于两个1x1卷积层。
层归一化 Add & norm
residual connection:便于训练更深的网络
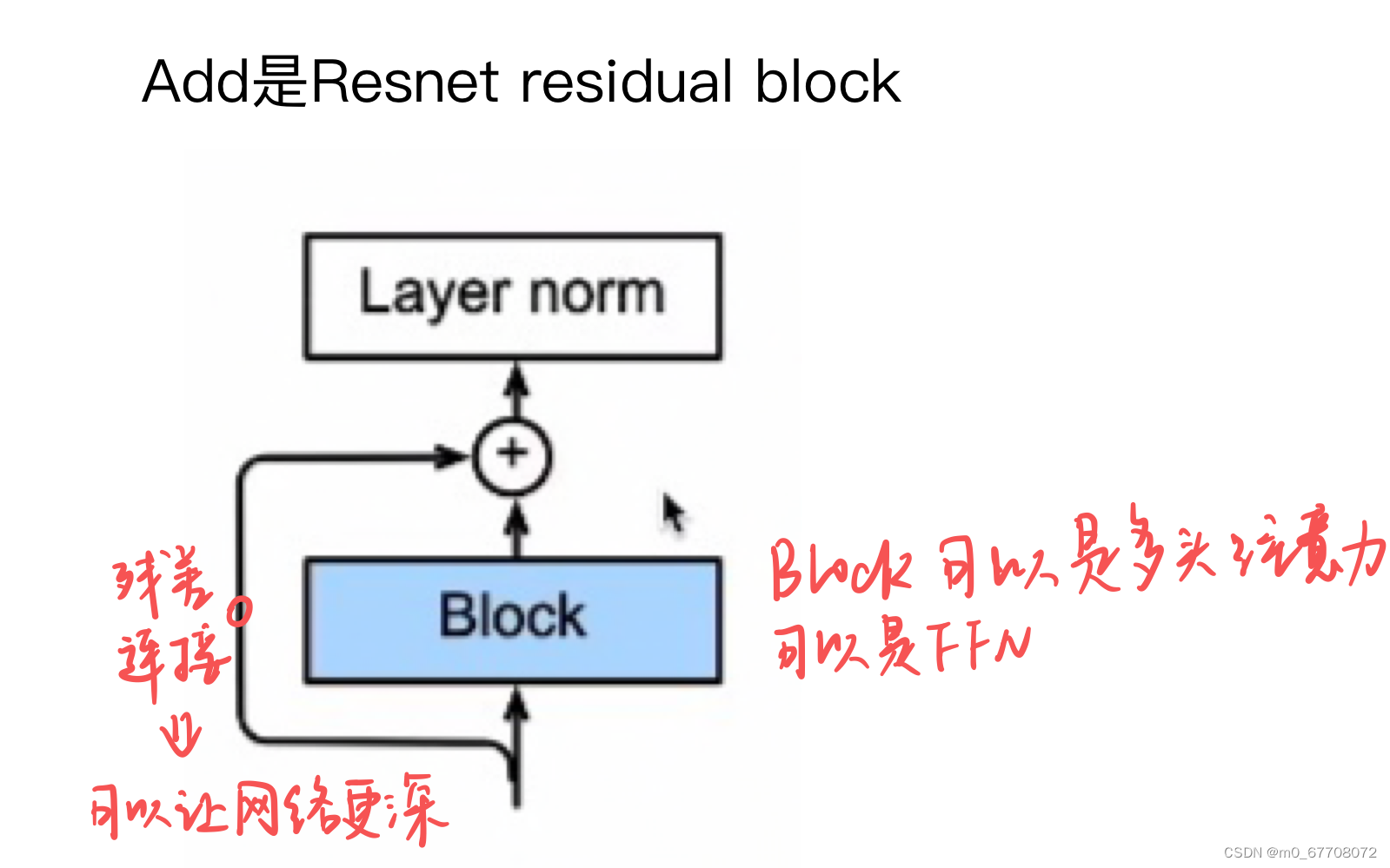
layer normalization:为了更加训练更容易更稳定,层归一化对每个样本的n*k个元素归一化(方差变1,均值变0)。

编码器到解码器的信息传递

图中出现三个attention,红圈圈起来的是一般的attention,key,value来自编码器的输出;另外两个都是self-attention,

预测

t时刻预测的就是第t+1个输出。
总结
Transformer是一个纯使用注意力机制的编码器-解码器。
编码器和解码器都有n个transformer块。
每个块内:有基于位置的前馈网络FFN全连接层(1x1卷积),多头注意力,有自注意力也有一般的attention,残差连接让网络更深,层归一化,位置编码。















 191
191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









