






DataLoader
1.主要参数
- dataset (Dataset) – 要从中加载数据的数据集。
- batch_size (int, 可选) – 每批要加载的样品数:随即抓取 (默认值:)。
1 - shuffle (bool, 可选) – 设置是否重新洗牌数据 在每个纪元(默认值:False)。
- num_workers (int, 可选) – 用于数据的子进程数装载。 默认表示数据将在主进程中加载。 (默认值:0)
- drop_last (bool, 可选) – 设置是否删除最后一个未完成的批次, 如果数据集大小不能被批处理大小整除。如果和数据集的大小不能被批处理大小整除,然后是最后一批 会更小。(默认值:False)
2.图解

3.基本使用
import torchvision
from torch.utils.data import DataLoader
#准备数据测试集,测试集已存在,不需要下载
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
#设置数据集的dataloader,说明如何操作数据集
test_loader=DataLoader(test_data,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
#测试集中第一张图片及target
img,target=test_data[0]
print(img.shape)
print(target)
#使用dataloader,把随机每batch_size个数据打包
for data in test_loader:
imgs,targets=data #imgs,targets为tensor类型
print(imgs.shape)
print(targets)
4.在tensorboard上显示,drop_last=False
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#准备数据测试集,测试集已存在,不需要下载
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
#设置数据集的dataloader,说明如何操作数据集
test_loader=DataLoader(test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
#测试集中第一张图片及target
img,target=test_data[0]
print(img.shape)
print(target)
writer =SummaryWriter('dataloader')
step=0#设置在tensorboard中的步长
#使用dataloader,把随机每batch_size个数据打包
for data in test_loader:
imgs,targets=data #imgs,targets为tensor类型
writer.add_images('test_data',imgs,step) #因为imgs中有多张图片,所以用add_images
step=step+1
writer.close()
5.drop_last参数选择True和False的不同
drop_last=True代码:
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#准备数据测试集,测试集已存在,不需要下载
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
#设置数据集的dataloader,说明如何操作数据集
test_loader=DataLoader(test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=True)
#测试集中第一张图片及target
img,target=test_data[0]
print(img.shape)
print(target)
writer =SummaryWriter('dataloader')
step=0#设置在tensorboard中的步长
#使用dataloader,把随机每batch_size个数据打包
for data in test_loader:
imgs,targets=data #imgs,targets为tensor类型
writer.add_images('test_data_drop_last',imgs,step) #因为imgs中有多张图片,所以用add_images
step=step+1
writer.close()
对比:上:False,下:True
[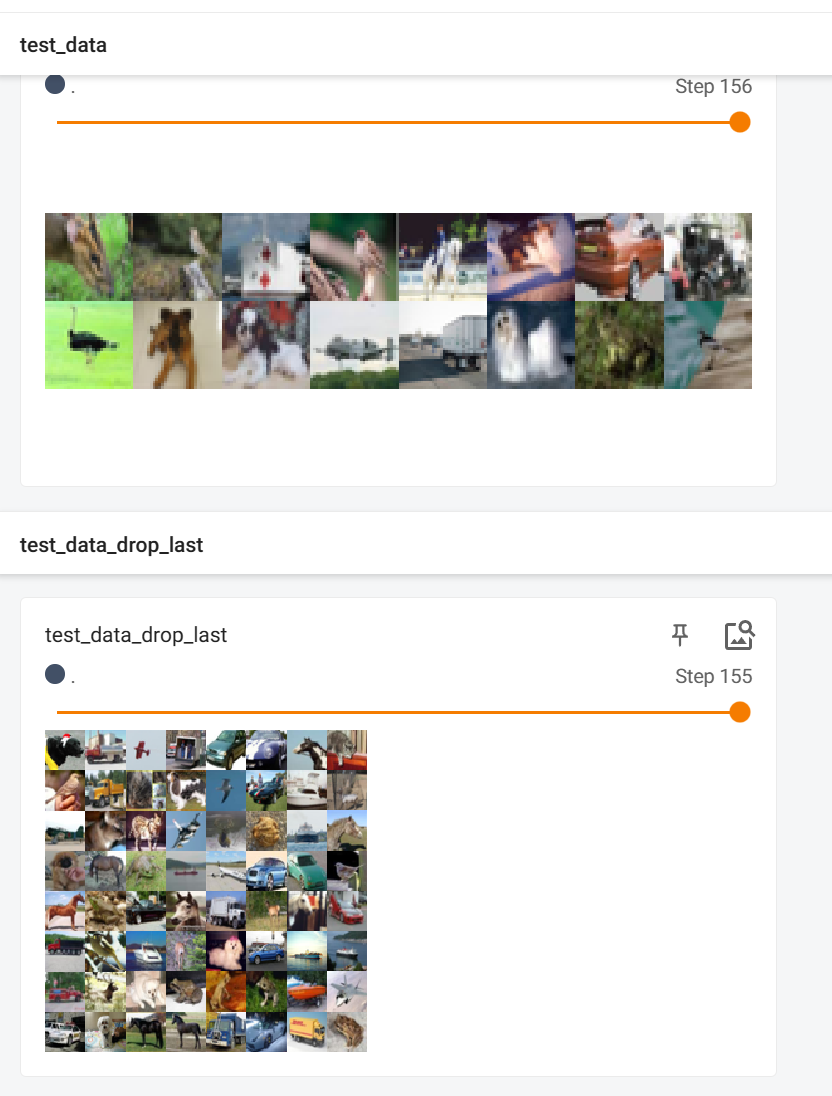
可以看出当设置为False时数据集大小不能被批处理大小整除,即整除后剩余部分,不会被删除;当设置为True时,整除后剩余部分,被删除。
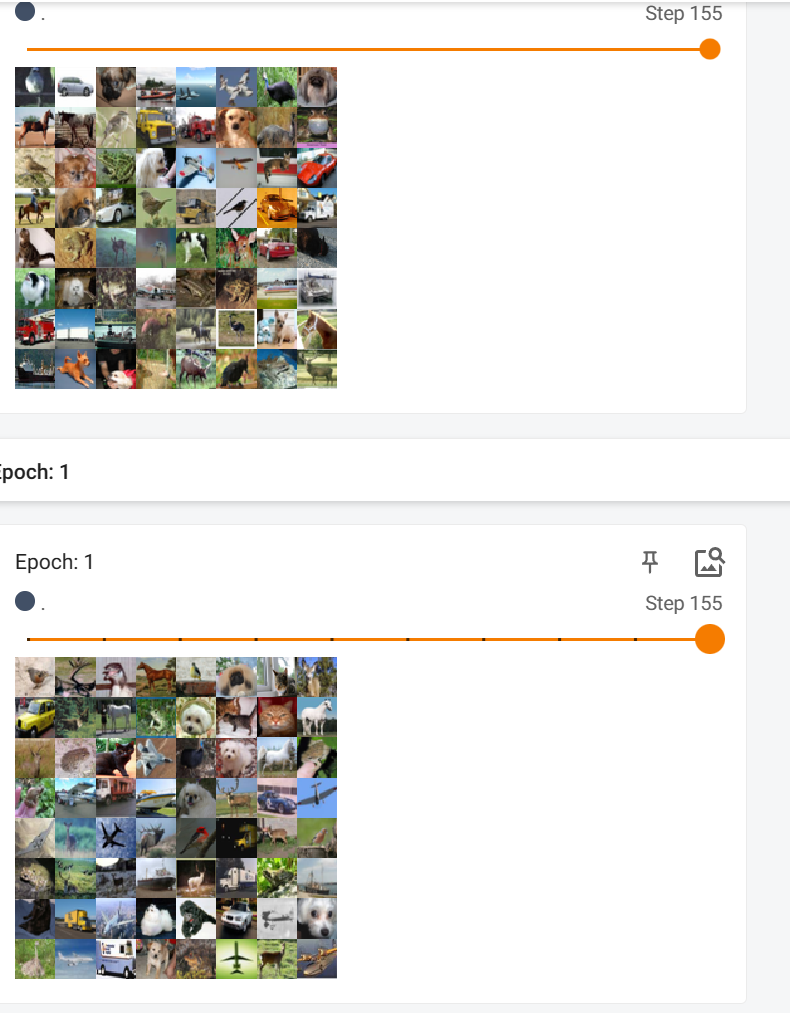
6.shuffle参数选择True和False的不同
shuffle(bool, 可选) – 设置是否重新洗牌数据
当设置为True,即设置每次重新洗牌时:
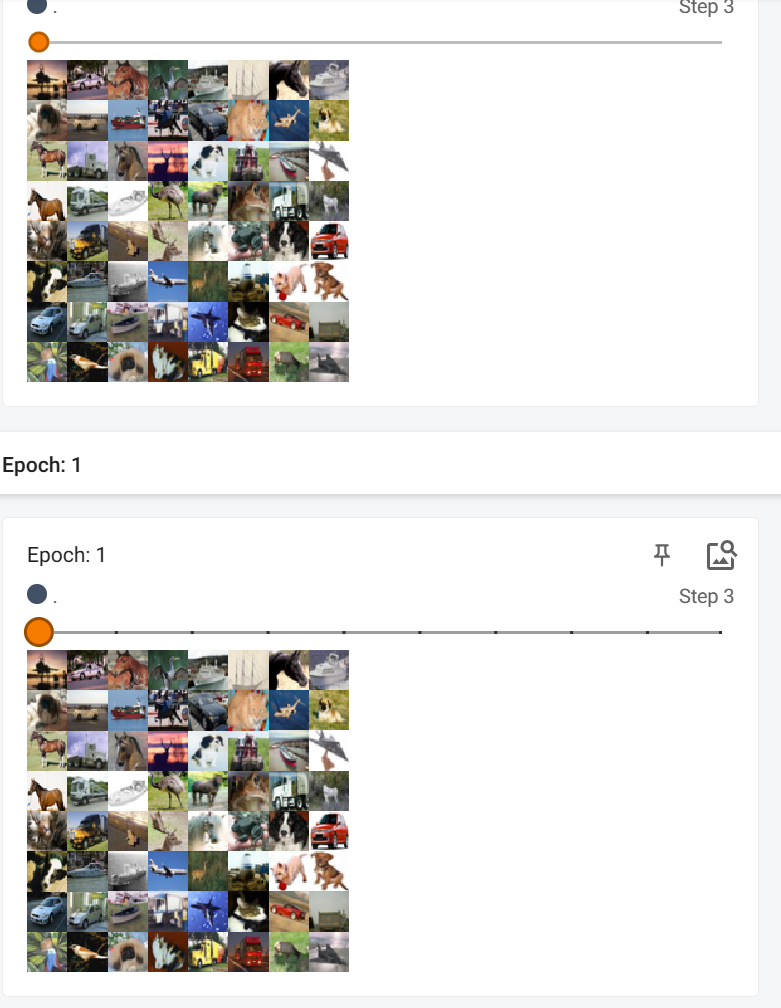
当设置为False,即设置每次不重新洗牌时:















 2061
2061











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









