






目录
前言
各位小伙伴们,好久不见啊,这两个月一直因为疫情和期末考试的原因就耽搁了博客的更新,新年就快到了,各位小伙伴们一定照顾好自己,下面我们废话不多说,直接进入我们今天的知识。
一. 回顾整型数据的存储
对于数据的储存我们早早在之前的学习就认识到了原码,反码和补码的概念。但是当时肯定有很大一部分的小伙伴对于这些概念是一知半解的,今天我们先回顾一下整型数据的存储。
一个变量在计算机中创建一定是需要开辟一定的内存,而这个内存的大小是根据不同的类型而改变的,那么数据在内存中到底是怎么开辟内存的呢?整型数据存储到计算机中到底是以什么形式来存储的呢?
1.1 原码.补码.反码
在计算机中是根据电子线来接受信号,而电子只有正反之分,对应也就是我们二进制中的1和0,而一台机器可能会有32根或者64根电子线,这就是我们的32位机器和64位机器之分。
整型数据之中是有正负之分的,其中最高位的数字就代表为符号位,其中当符号位为“0”的时候为正,符号位为“1”的时候则为负,当一个数据为正数的时候,我们便不会讨论其原码补码反码,因为正数的原反补是相同的,而负数就会很不一样:
原码
将数值由当前进制转换为二进制得到的数字就是原码。
反码
反码就是将其原码符号位不变,其他位按位取反,这样得到的二进制数就是补码。
补码
将反码+1得到的就是补码。
对于整型的存储来说,我们真正存入计算机中只有补码,原因是:在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统一处理;同时,加法和减法也可以统一处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。举个例子:
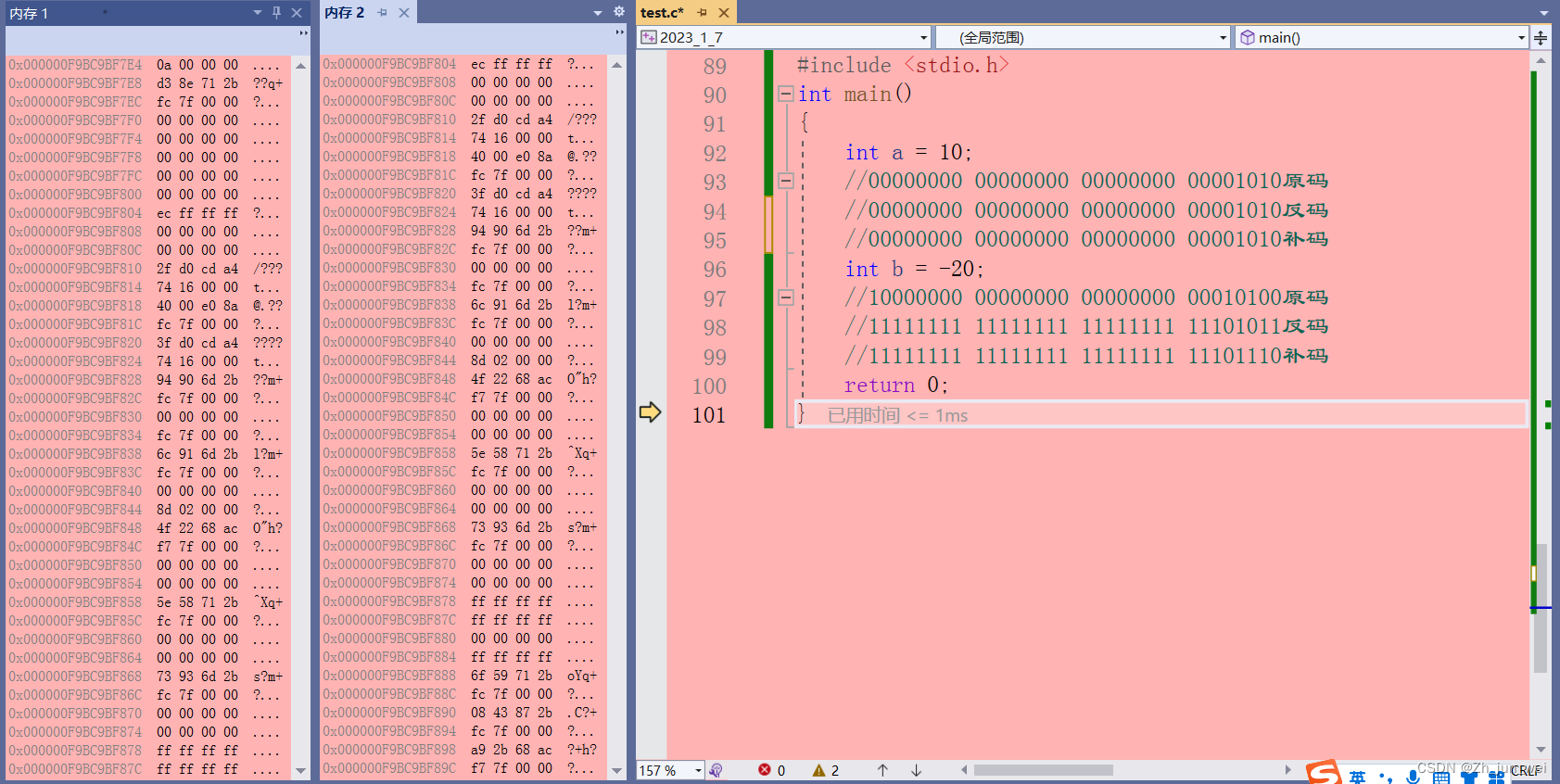
创造两个整型a和b
int a=10; //00000000 00000000 00000000 00001010原码 //00000000 00000000 00000000 00001010反码 //00000000 00000000 00000000 00001010补码 int b=-20; //10000000 00000000 00000000 00010100原码 //11111111 11111111 11111111 11101011反码 //11111111 11111111 11111111 11101110补码
我们可以很清晰的看到整型a,b在内存中存储形式就是补码的十六进制,这里肯定都明白了何为原码,何为补码,何为反码,但是肯定也会有小伙伴发问,这为什么存入计算机中的数据是倒着存进去的?好问题,这也正是我们下一个面试常问的问题。
1.2 大端与小端
何为大端小端?
大端(存储)模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中。
小端(存储)模式,是指数据的低位保存在内存的低地址中,而数据的高位,,保存在内存的高地址中。
那我们为什么会有两种存储方式呢?难道就不能出现第三种吗?
一个int型的数据其中包含32个比特位,就算转换为十六进制也还会有8位,那如何放入计算机的内存中呢?就例如0x11223344(注:其中0x是代表十六进制的写法),有人提议11 22 33 44这样存,有人提议44 33 22 11这样存,还有人说我们也可以11 33 22 44这样乱序存,最后一种很明显没有任何价值就保留了正序和逆序两种方式存储,有人会问为什么非要留下两种方式呢?只留下其中一种正序或者逆序的方法不可以吗?这就不为人知了,听说是根据格列佛游记中来的灵感,剥鸡蛋应该从大头开始剥还是应该从小头开始剥,反正最后留下了大端和小端两种存储方式,很多面试题就会提问你大端和小端的区别和如何判断一台机器是大端还是小端?
百度2015系统工程师中就有这么一道题:
请简述大端字节序和小端字节序的概念,设计一个小程序来判断当前机器的字节序。(10分)
#include <stdio.h> int check_sys() { int i = 1; return (*(char *)&i); } int main() { int ret = check_sys(); if(ret == 1) { printf("小端\n"); } else { printf("大端\n"); } return 0; }这样我们便可以判断出这台机器是大端机器还是小端机器。
二. 数据类型的介绍
终于回顾完了整型数据的存储,我们就要来介绍一下数据的类型。
我们之前学习过的数据类型有:
int 整型
short 短整型
long 长整型
long long 更长的整型
char 字符数据类型
float 单精度浮点型
double 双精度浮点型
下面我们就需要将数据类型进行一个基本的分类:
整型:
char
unsigned char
signed char
short
unsigned short [int]
signed short [int]
int
unsigned int
signed int
long
unsigned long [int]
signed long [int]
浮点型:
float
double
构造类型:
> 数组类型
> 结构体类型 struct
> 枚举类型 enum
> 联合类型 union
构造型家族后面我们还会在细讲。
指针类型:
int *pi;
char *pc;
float* pf;
void* pv;
空类型:
void 表示空类型(无类型)
通常应用于函数的返回类型、函数的参数、指针类型。
这就是所有的数据类型。
三. 浮点型在内存的存储
现在才是今天内容的重中之重,浮点型数据到底是如何存储在计算机的?与整型存储一样还是有所差距呢?3.14这种浮点数到底如何存储,咱们就一步步往下看。
首先如果我们想要知道浮点数类型的范围可以用everything中查询float.h然后用编译器打开便可以看见浮点数类型的范围,下面一个很好的例子可以引出我们到底是如何存储数据的,
int main() { int n = 9; float *pFloat = (float *)&n; printf("n的值为:%d\n",n); printf("*pFloat的值为:%f\n",*pFloat); *pFloat = 9.0; printf("num的值为:%d\n",n); printf("*pFloat的值为:%f\n",*pFloat); return 0; }我们可能猜测的结果可能是9,9.0000000,9,9.0000000,如果你猜的结果是这个那一定大错特错。
我们发现只有第一个数和最后一个数是正确的,而第二个数为什么是0,第三个数为什么又会变成这么大的一个数呢?下面就要介绍浮点数存储的规则了,按照国际标准IEEE(电气和电子工程协会)754,任意一个二进制浮点数V可以表示成下面的形式:
(-1)^S * M * 2^E
(-1)^S表示符号位,当S=0,V为正数;当S=1,V为负数。
M表示有效数字,大于等于1,小于2。
2^E表示指数位。
举例来说:
十进制的5.0,写成二进制是 101.0 ,相当于 1.01×2^2 。
那么,按照上面V的格式,可以得出S=0,M=1.01,E=2。
十进制的-5.0,写成二进制是 -101.0 ,相当于 -1.01×2^2 。那么,S=1,M=1.01,E=2。
IEEE 754规定:
对于32位的浮点数,最高的1位是符号位s,接着的8位是指数E,剩下的23位为有效数字M。对于64位的浮点数,最高的1位是符号位S,接着的11位是指数E,剩下的52位为有效数字M。

IEEE 754对有效数字M和指数E,还有一些特别规定。
前面说过, 1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中xxxxxx表示小数部分。
IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的xxxxxx部分。比如保存1.01的时候,只保存01,等到读取的时候,再把第一位的1加上去。这样做的目的,是节省1位有效数字。以32位浮点数为例,留给M只有23位,将第一位的1舍去以后,等于可以保存24位有效数字。至于指数E,情况就比较复杂。首先,E为一个无符号整数(unsigned int)这意味着,如果E为8位,它的取值范围为0~255;如果E为11位,它的取值范围为0~2047。但是,我们知道,科学计数法中的E是可以出现负数的,所以IEEE 754规定,存入内存时E的真实值必须再加上一个中间数,对于8位的E,这个中间数-是127;对于11位的E,这个中间数是1023。比如,2^10的E是10,所以保存成32位浮点时,必须保存成10+127=137,即10001001。然后,指数E从内存中取出还可以再分成三种情况:
E不全为0或不全为1
这时,浮点数就采用下面的规则表示,即指数E的计算值减去127(或1023),得到真实值,再将有效数字M前加上第一位的1。
比如:
0.5(1/2)的二进制形式为0.1,由于规定正数部分必须为1,即将小数点右移1位,则为
1.0*2^(-1),其阶码为-1+127=126,表示为
01111110,而尾数1.0去掉整数部分为0,补齐0到23位00000000000000000000000,则其二进制表示形式为:0 01111110 00000000000000000000000E全为0
这时,浮点数的指数E等于1-127(或者1-1023)即为真实值,
有效数字M不再加上第一位的1,而是还原为0.xxxxxx的小数。这样做是为了表示±0,以及接近于0的很小的数字。E全为1
这时,如果有效数字M全为0,表示±无穷大(正负取决于符号位s)。这就是浮点数存入计算机的规则。
那对于上面那个例子就很好解释了,为什么 0x00000009 还原成浮点数,就成了 0.000000 ?首先,将 0x00000009 拆分,得到第一位符号位s=0,后面8位的指数 E=00000000 ,最后23位的有效数字M=000 0000 0000 0000 0000 1001。由于指数E全为0,所以符合上一节的第二种情况。因此,浮点数V就写成:
V=(-1)^0 × 0.00000000000000000001001×2^(-126)=1.001×2^(-146)
显然,V是一个很小的接近于0的正数,所以用十进制小数表示就是0.000000。
再看例子的第二部分。
请问浮点数9.0,如何用二进制表示?还原成十进制又是多少?
首先,浮点数9.0等于二进制的1001.0,即1.001×2^3。
那么,第一位的符号位s=0,有效数字M等于001后面再加20个0,凑满23位,指数E等于3+127=130,即10000010。所以,写成二进制形式,应该是s+E+M,即
这个32位的二进制数,还原成十进制,正是 1091567616 。


如此看来浮点数的存储与整型大有不同。
这就是今天对于数据存储的所有讲解,很久没写博客,手有点生了,在这里祝大家新年快乐!新的一年大家一起努力,为了美好offer一起奋斗吧!

















 791
791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











