






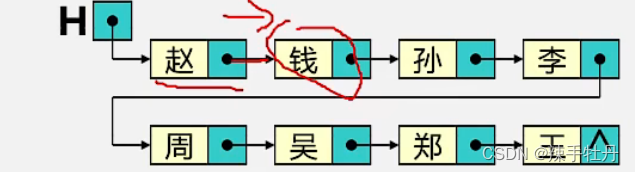
头指针H存储的是 第一个结点的地址,单链表也可以用头指针来命名
结点:数据域,指针域。指针域中存储的是下一个结点的地址
链表分为单链表,双链表(两个指针域),循环链表(最后一个结点的指针域存储头结点的地址)
头指针-头结点-首元结点,头结点可有可无
判断是否为空表:
有头结点时,头结点的指针域为空
无头结点时,头指针为空
设立头结点的好处:便于处理首元结点;便于空表和非空表统一处理
PS:头结点可以为空,统计表长时不统计头结点的长度
!顺序表:随机存取;链表:顺序存取
每个节点分为数据域和指针域,数据域的数据类型取决于元素是什么类型
非常重要!!!
int a = 5;
int* p;//因为a的类型为int,所以*p也为int
p=&a;//将a的地址用&取出来赋值给p模板:
typedef struct Lnode {
ElemType data;
struct Lnode* next;
}Lnode,*LinkList;
LinkList L//定义链表L
Lnode*p,LinkList p//定义结点指针p
//但一般用Lnode*L,Lnode*peg:学生表
数据域:学号姓名分数
typedef Struct student{
char num[8];
char name[8];
int score;
struct student* next;
}Lnode, * LinkList;//这是它的名字但一般这样定义:
typedef Struct{
char num[8];
char name[8];
int score;
}ElemType;
typedef struct Lnode {
ElemType data;
struct Lnode* next;
}Lnode,*LinkList;















 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









