







目录
大家好,我是吒吒
在本文中你将会学习到:
-
单、多变量分析
-
相关性分析
-
缺失值和异常值处理
-
哑变量转换
一、排名榜
让我们看下排名榜,第一名真的是碾压其他选手呀~所以,今天我们一起看看这个第一名的方案到底是多棒?

二、数据介绍
这份波士顿房价的数据集有4份数据,训练集train+测试集test+数据集的描述description+提交模板sample

其中训练集有81个特征,1460条数据;测试集81个特征,1459条数据。看下部分属性介绍:


三、数据EDA
导入模块和数据,并进行数据探索:
导入库
import pandas as pd
import numpy as np
# 绘图相关
import plotly.express as px
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use("fivethirtyeight")
# 数据建模
from scipy.stats import norm
from scipy import stats
from sklearn.preprocessing import StandardScaler
# 警告
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
导入数据

数据信息
训练集整体是1460*81;而且很多的存在字段都存在缺失值

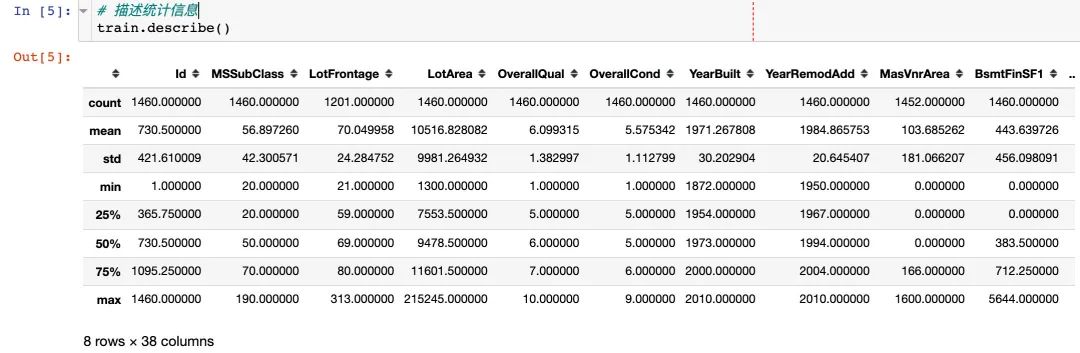
描述统计信息:
四、销售价格SalePrice分析
原notebook文档中,作者分析了很多自己关于这个题目和字段的看法,具体不阐述。下面介绍的是重点部分:
统计信息
单单看这个字段的统计信息:

分布直方图如下,我们明显感受到:
-
价格的分布偏离了正态分布
-
有明显的正偏度现象
-
有明显的峰值出现

偏度和峰度(skewness and kurtosis)
知识加油站:偏度和峰度
详细的解释参见文章:https://zhuanlan.zhihu.com/p/53184516
-
偏度:衡量随机变脸概率分布的不对称性,是相对于平均值不对称程度的度量,通过对偏度系数的测量,我们能够判定数据分布的不对称程度以及方向。
-
峰度:是研究数据分布陡峭或者平滑的统计量,通过对峰度系数的测量,我们能够判定数据相对于正态分布而言是更陡峭还是更平缓。峰度接近0,数据呈现正态分布;峰度>0,高尖分布;峰度<0,矮胖分布
偏度的两种分布情况:
-
如果是左偏,则偏度小于0
-
如果是右偏,则偏度大于0

峰度的两种分布情况:
-
如果是高瘦型,则峰度大于0
-
如果是矮胖型,则峰度小于0

# 打印销售价格的偏度和峰度
print("Skewness(偏度): %f" % train['SalePrice'].skew())
print("Kurtosis(峰度): %f" % train['SalePrice'].kurt())
Skewness(偏度): 1.882876
Kurtosis(峰度): 6.536282
偏度和峰度值都是正的,明显说明数据是右偏且高尖分布
SalePrice和数值型字段的关系
首先我们考察和居住面积的关系:

plt.figure(1,figsize=(12,6))
sns.scatterplot(x="GrLivArea",y="SalePrice",data=data)
plt.show()

# plotly版本
px.scatter(data,x="GrLivArea",y="SalePrice",trendline="ols")

TotalBsmtSF VS SalePrice
# 2、TotalBsmtSF
data = train[["SalePrice","TotalBsmtSF"]]
plt.figure(1, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 577
577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









