






 本文详细介绍了如何使用Python的Pandas库处理数据集,包括创建DataFrame、数据查看、切片、筛选、函数应用、分组统计以及数据可视化,涵盖了基础到高级的数据分析操作。
本文详细介绍了如何使用Python的Pandas库处理数据集,包括创建DataFrame、数据查看、切片、筛选、函数应用、分组统计以及数据可视化,涵盖了基础到高级的数据分析操作。
1.导入pandas包
import pandas as pd2.根据给定的原始数据集创建一个DataFrame类型对象df
data={
'id':[10001,10002,10003,10004,10005,10006,10007,10008,10009,10010],
'name':['LY','CE','ZS','LS','WU','ZL','SQ','ZB','WJ','ZS'],
'sex':['F','M','M','F','F','F','M','F','M','M'],
'age':[18,20,36,47,13,25,32,45,13,16],
'address':['California','Texas','Florida','California','Texas','Florida','California','Florida','Texas','Texas'],
'Mjob':['at_home','services','at_home','services','student','at_home','teacher','health','student','student'],
'Ojob':['health','teacher','teacher','health','other','teacher','health','health','other','at_home']
}
#columns=['id','name','sex','age','address','Mjob','Ojob'],列标签
df=pd.DataFrame(data,columns=['id','name','sex','age','address','Mjob','Ojob'])3.查看df
display(df)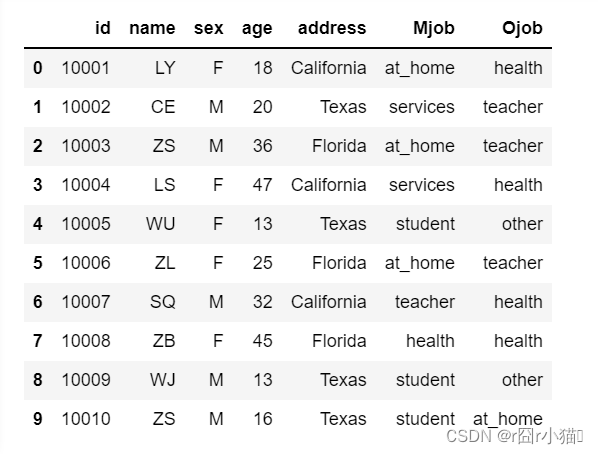
4.查看df前5行和后5行
#方法一
print("前五行数据为:\n",df[:5])#左闭右开
print("后五行数据为:\n",df[5:])
#方法二
print("前五行数据为:\n",df.head())#head(n),n不写时默认获取前5行,n为具体数据时则为获取前n行
print("后五行数据为:\n",df.tail())#tail(n),n不写时默认获取后5行,n为具体数据时则为获取后n行
5.查看行和列的索引值
print("行的索引值为:",df.index)
print("列的索引值为:",df.columns)
6.分别查看name、sex列的值
print("name列的值:\n",df['name'])
print("sex列的值:\n",df['sex'])

7.同时查看name和sex列的值
#方法一
display(df.loc[:,['name','sex']])
#方法二
display(df.iloc[:,[1,2]])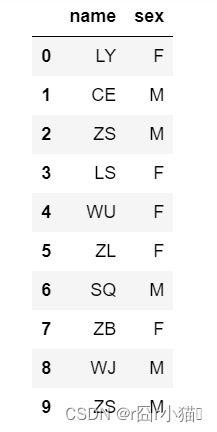
8.连续切片,取0-5行、0-5列、左闭右开的所有数据
display(df.iloc[0:5,0:5])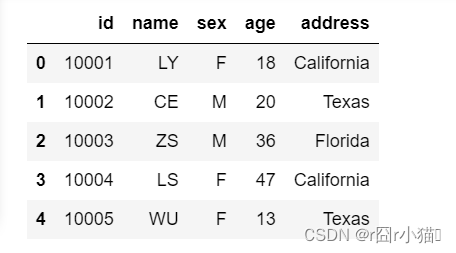
9.筛选出第2-5行的第1、3、5列的所有数据
display(df.iloc[1:5,[0,2,4]])
10.分别筛选出Mjob列值不为”student”和值为“student”的所有数据
display(df[df['Mjob']=='student'])
display(df[df['Mjob']!='student'])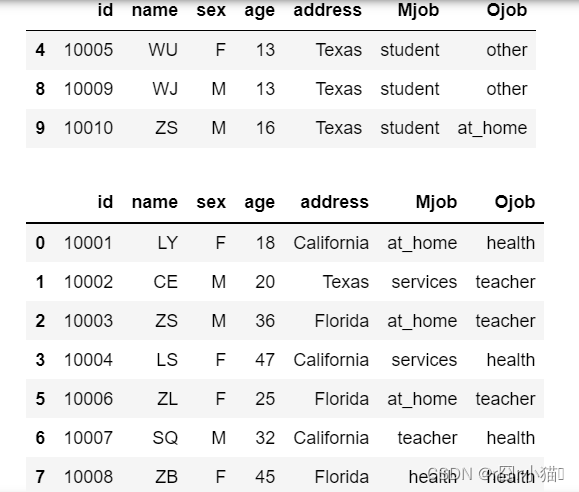
11.定义函数gender_count,对性别进行标识,M用1表示,F用0表示
def gender_count(x):
if x=='M':
return 1
else:
return 0
count=df['sex'].apply(gender_count)12.df增加一列gender_n,调用函数gender_count对性别进行标识
df.insert(loc=3,column="gender_n",value=count[:])
display(df)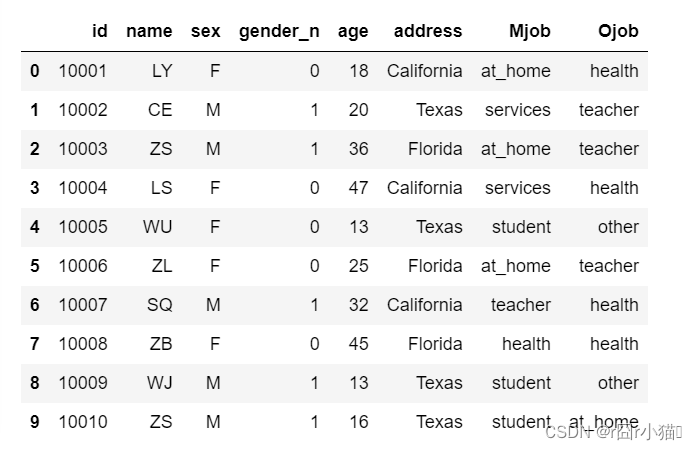
13.按Mjob分类,求每一种职业男性的占比
a = df.groupby(['Mjob']).gender_n.sum()/df['Mjob'].value_counts()*100
print(a)
14.将占比值从高到低的顺序排列
a2=a.sort_values(ascending=False)
print(a2)
15.求Mjob列不同值的个数
print(df.groupby('Mjob')['Mjob'].count())
16.获取每种职业对应的最大和最小的用户年龄
print("每种职业的最小用户年龄:\n",df.groupby(['Mjob','Ojob'])['age'].min())
print("每种职业的最大用户年龄:\n",df.groupby(['Mjob','Ojob'])['age'].max())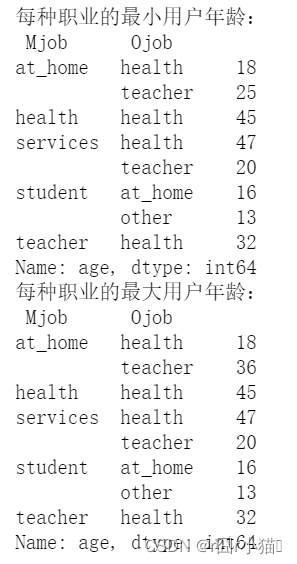
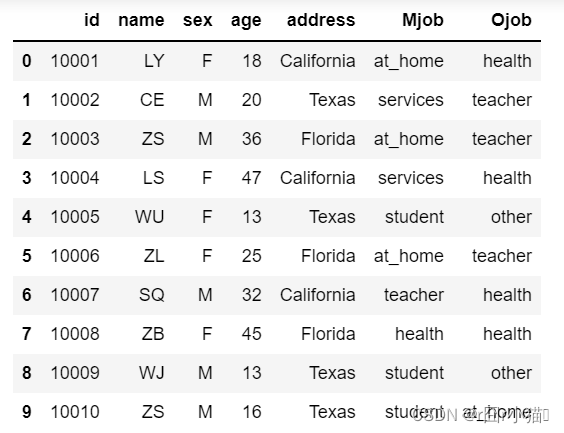
17.删除最后一列gender_n(就地修改)
df.drop(columns='gender_n',inplace=True)
display(df)
18.将数据列Mjob和Ojob中的所有数据实现首字母大写
for col in ['Mjob','Ojob']:
df[col]=df[col].str.title()
display(df.loc[:,['Mjob','Ojob']])
19.设定id列为行索引
display(df.set_index('id'))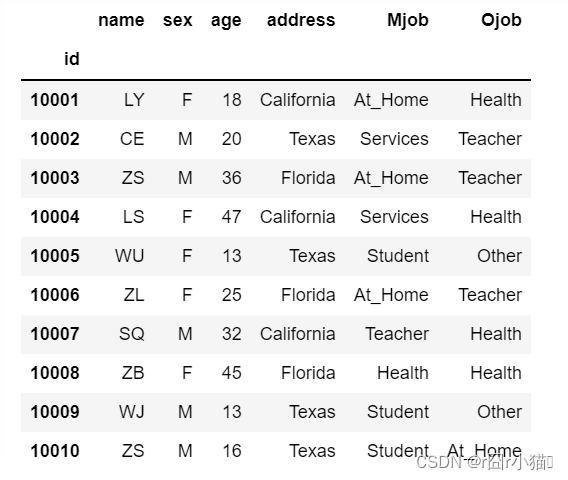
20.使用直方图可视化不同年龄段区间[10,20,30,40,50]的人数
import matplotlib.pyplot as plt
x = df['age'].values
plt.hist(x,bins=[10,20,30,40,50])
plt.ylim(0,5)
plt.show()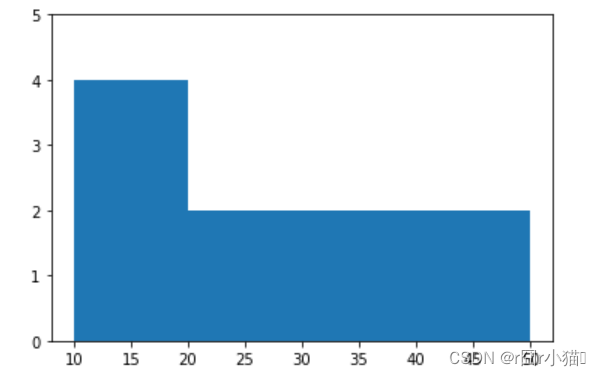
21.使用饼形图可视化不同类Mjob人员的占比
import matplotlib.pyplot as plt
import numpy as np
mjob=np.array(df.groupby('Mjob')['Mjob'].count().index)
num=np.array(df.groupby('Mjob')['Mjob'].count()[:])
plt.pie(num,labels=mjob,autopct='%1.0f%%')
plt.show()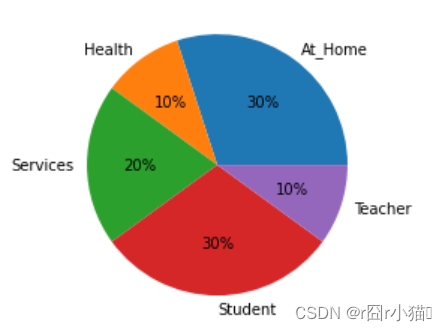
22.使用柱状图可视化不同类Ojob人员的数量
import matplotlib.pyplot as plt
import numpy as np
ojob=np.array(df.groupby('Ojob')['Ojob'].count().index)
num=np.array(df.groupby('Ojob')['Ojob'].count()[:])
plt.bar(ojob,num)
plt.show() 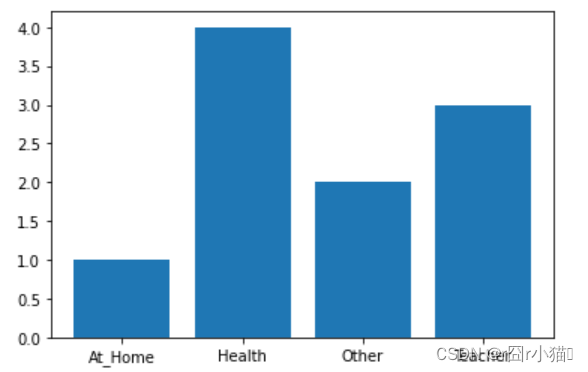















 1803
1803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









