






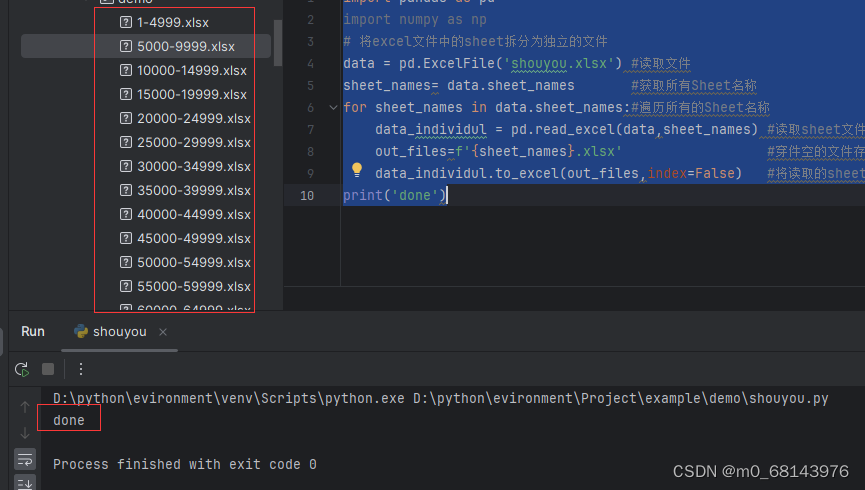
Sheet文件拆分为独立文件:
在Python中,f-string是一种字符串格式化的方法,用于在字符串中插入变量的值。在一个字符串前加上 f ,然后用大括号 {} 包裹变量名,Python会自动将变量的值插入到字符串中。这样可以使代码更加简洁和易读。
原始数据:
代码:
import pandas as pd
import numpy as np
# 将excel文件中的sheet拆分为独立的文件
data = pd.ExcelFile('shouyou.xlsx') #读取文件
sheet_names= data.sheet_names #获取所有Sheet名称
for sheet_names in data.sheet_names:#遍历所有的Sheet名称
data_individul = pd.read_excel(data,sheet_names)#读取sheet文件
out_files=f'{sheet_names}.xlsx' #穿件空的文件存储sheet
data_individul.to_excel(out_files,index=False) #将读取的sheet写入到创建的空的文件名
print('done')
index=False用途:在将数据写入Excel文件时, to_excel 方法默认会将DataFrame的索引写入Excel文件中。通过将 index=False 传递给 to_excel 方法,可以防止将索引值写入Excel文件,从而创建一个不包含索引的Excel文件。这对于一些情况下不需要索引的数据导出非常有用,可以让数据更加清晰和整洁
输出:
将EXCEL的Sheet文件合并到一个文件:
# 合并EXCEL文件中的SHEET到一个文件
data = pd.ExcelFile('shouyou.xlsx') #读取文件
sheet_names= data.sheet_names #获取所有Sheet名称
all_data = pd.DataFrame()
for sheet_names in data.sheet_names:
individul_sheet=pd.read_excel(data,sheet_names)
all_data=pd.concat([all_data,individul_sheet],axis=0,ignore_index=True)#方法一,通过concat合并数据
# all_data=all_data._append(individul_sheet,ignore_index=True)#方法二,通过_append追加数据
all_data.to_excel('all_data1.xlsx',index=False)
print('done')
ignore_index的作用:ignore_index 是Pandas中DataFrame合并函数 concat() 和 append() 的一个参数,用于控制是否忽略合并时原始数据的索引。当设置 ignore_index=True 时,合并后的DataFrame会创建一个新的连续索引,而不保留原始数据的索引。这在需要重新排序或重新编号数据时非常有用。例如,将多个数据集合并时,可以使用 ignore_index=True 来创建一个新的连续索引,而不保留原始数据集的索引。
合并后: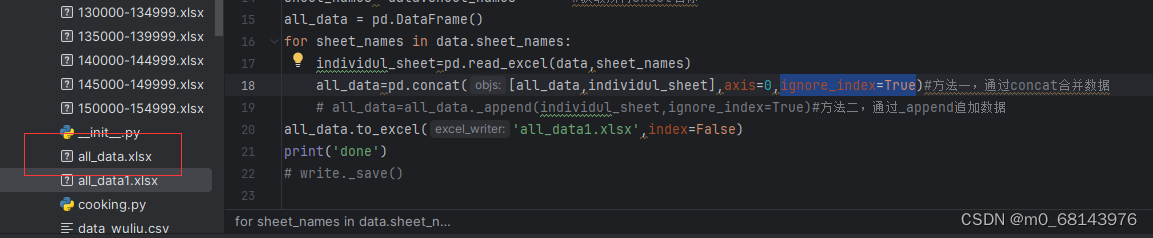
注意注意注意,重要的事说三遍,合并的列名一定要保持一致,否则合并后的数据会出错















 1265
1265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









