







停车场车位识别
停车场车位实时检测任务,是拿到停车场的一段视频video,主要完成两件事情:
- 检测整个停车场当中,当前一共有多少辆车,一共有多少个空余的车位
- 把空余的停车位标识出来,这样用户停车的时候,就可以直接去空余的停车位处, 为停车节省了很多时间
遇到的问题
I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
遇到了这个问题,意思是你的 CPU 支持AVX2 FMA(加速CPU计算),但安装的 TensorFlow 版本不支持
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
2.遇到的问题
forrtl: error (200): program aborting due to control-C event
Image PC Routine Line Source
libifcoremd.dll 00007FFD5FCA3B58 Unknown Unknown Unknown
KERNELBASE.dll 00007FFDC015B933 Unknown Unknown Unknown
KERNEL32.DLL 00007FFDC15D7034 Unknown Unknown Unknown
ntdll.dll 00007FFDC2762651 Unknown Unknown Unknown
解决方法:pip install --upgrade scipy
3.对图片进行测试,识别出空停车位位置及数量
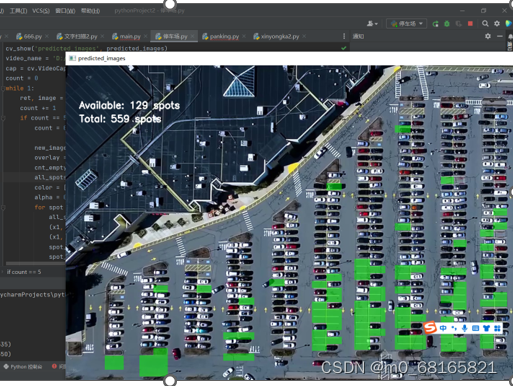
4.具体代码:
import cv2 as cv
import numpy as np
import operator
import pickle
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
from keras.models import Sequential
from keras.models import load_model
def cv_show(name, img):
cv.imshow(name, img)
cv.waitKey(0)
cv.destroyAllWindows()
image = cv.imread('D:/D/download/scene1410.jpg')
cv_show('src', image)
lower = np.uint8([120, 120, 120])
upper = np.uint8([255, 255, 255])
# lower_red和高于upper_red的部分分别变成0,lower_red~upper_red之间的值变成255,相当于过滤背景
white_mask = cv.inRange(image, lower, upper)
cv_show('white_mask',white_mask)
white_yellow_image = cv.bitwise_and(image, image, mask = white_mask)
cv_show('white_yellow_image', white_yellow_image)
# 转灰度图
gray_image = cv.cvtColor(white_yellow_image, cv.COLOR_BGR2GRAY)
cv_show('gray_image', gray_image)
edge_image = cv.Canny(gray_image, 50, 200)
cv_show('edge_image', edge_image)
# 手动选择区域
row, col = image.shape[:2]
pt_1 = [col*0.05, row*0.90]
pt_2 = [col*0.05, row*0.70]
pt_3 = [col*0.30, row*0.55]
pt_4 = [col*0.6, row*0.15]
pt_5 = [col*0.90, row*0.15]
pt_6 = [col*0.90, row*0.90]
vertices = np.array([[pt_1, pt_2, pt_3, pt_4, pt_5, pt_6]], dtype=np.int32)
point_img = edge_image.copy()
point_img = cv.cvtColor(point_img, cv.COLOR_GRAY2RGB)
for point in vertices[0]:
cv.circle(point_img, (point[0], point[1]), 10, (0, 0, 255), 4)
cv_show('point_img', point_img)
mask = np.zeros_like(edge_image)
cv.fillPoly(mask, vertices, 255)
cv_show('mask', mask)
roi_image = cv.bitwise_and(edge_image, mask)
cv_show('roi_image', roi_image)
lines = cv.HoughLinesP(roi_image, rho=0.1, theta=np.pi/10, threshold=15, minLineLength=9, maxLineGap=4)
print(lines.shape)
# 挑出符合要求的直线并画出
line_image = np.copy(image)
cleaned = []
for line in lines:
x1, y1, x2, y2 = line[0]
if abs(y2-y1) <= 1 and abs(x2-x1) >=25 and abs(x2-x1) <= 55:
cleaned.append((x1, y1, x2, y2))
cv.line(line_image, (x1, y1), (x2, y2), [255, 0, 0], 2)
print("No lines detected: ", len(cleaned))
cv_show('line_image', line_image)
rect_image = np.copy(image)
list1 = sorted(cleaned, key=operator.itemgetter(0, 1))
clusters = {}
dIndex = 0
clus_dist = 20
for i in range(len(list1) - 1):
distance = abs(list1[i+1][0] - list1[i][0])
if distance <= clus_dist:
if not dIndex in clusters.keys():
clusters[dIndex] = []
clusters[dIndex].append(list1[i])
clusters[dIndex].append(list1[i + 1])
else:
dIndex += 1
rect_coord = {}
i = 0
for key in clusters:
all_list = clusters[key]
list2 = list(set(all_list))
if len(list2) > 5:
list2 = sorted(list2, key=lambda tup: tup[1])
avg_y1 = list2[0][1]
avg_y2 = list2[-1][1]
avg_x1 = 0
avg_x2 = 0
for tup in list2:
avg_x1 += tup[0]
avg_x2 += tup[2]
avg_x1 = avg_x1/len(list2)
avg_x2 = avg_x2/len(list2)
rect_coord[i] = (avg_x1, avg_y1, avg_x2, avg_y2)
i += 1
print("Num Parking Lanes: ", len(rect_coord))
buff = 7 # 微调
for key in rect_coord:
tup_topLeft = (int(rect_coord[key][0] - buff), int(rect_coord[key][1]))
tup_botRight = (int(rect_coord[key][2] + buff), int(rect_coord[key][3]))
cv.rectangle(rect_image, tup_topLeft,tup_botRight,(0,255,0),3)
cv_show('rect_image', rect_image)
# 每个区域画出横线
delineated = np.copy(image)
gap = 15.5 # 同一列中相邻停车位之间的纵向距离
spot_pos = {}
tot_spots = 0
#微调
adj_y1 = {0: 20, 1:-10, 2:0, 3:-11, 4:28, 5:5, 6:-15, 7:-15, 8:-10, 9:-30, 10:9, 11:-32}
adj_y2 = {0: 30, 1: 50, 2:15, 3:10, 4:-15, 5:15, 6:15, 7:-20, 8:15, 9:15, 10:0, 11:30}
adj_x1 = {0: -8, 1:-15, 2:-15, 3:-15, 4:-15, 5:-15, 6:-15, 7:-15, 8:-10, 9:-10, 10:-10, 11:0}
adj_x2 = {0: 0, 1: 15, 2:15, 3:15, 4:15, 5:15, 6:15, 7:15, 8:10, 9:10, 10:10, 11:0}
for key in rect_coord:
tup = rect_coord[key]
x1 = int(tup[0] + adj_x1[key])
x2 = int(tup[2] + adj_x2[key])
y1 = int(tup[1] + adj_y1[key])
y2 = int(tup[3] + adj_y2[key])
cv.rectangle(delineated, (x1, y1), (x2, y2), (0, 255, 0), 2)
num_splits = int(abs(y2-y1) // gap)
for i in range(num_splits + 1):
y = int(y1 + i * gap)
cv.line(delineated, (x1, y), (x2, y), [255, 0, 0], 2)
if key > 0 and key < len(rect_coord) - 1:
x = int((x1 + x2) / 2)
cv.line(delineated, (x, y1), (x, y2), [255, 0, 0], 2)
if key == 0 or key == (len(rect_coord) - 1):
tot_spots += num_splits + 1
else:
tot_spots += 2 * (num_splits + 1)
if key == 0 or key == (len(rect_coord) - 1):
for i in range(num_splits + 1):
cur_len = len(spot_pos)
y = int(y1 + i * gap)
spot_pos[(x1, y, x2, y+gap)] = cur_len + 1
else:
for i in range(num_splits + 1):
cur_len = len(spot_pos)
y = int(y1 + i * gap)
x = int((x1 + x2) / 2)
spot_pos[(x1, y, x, y+gap)] = cur_len +1
spot_pos[(x, y, x2, y+gap)] = cur_len +2
print("total parking spaces: ", tot_spots, cur_len)
cv_show('delineated', delineated)
with open('spot_dict.pickle', 'wb') as handle:
pickle.dump(spot_pos, handle, protocol=pickle.HIGHEST_PROTOCOL)
for spot in spot_pos:
(x1, y1, x2, y2) = spot
(x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2))
#裁剪
spot_img = image[y1:y2, x1:x2]
spot_img = cv.resize(spot_img, (0,0), fx=2.0, fy=2.0)
spot_id = spot_pos[spot]
filename = 'spot' + str(spot_id) +'.jpg'
print(spot_img.shape, filename, (x1,x2,y1,y2))
cv.imwrite(os.path.join('cnn_data', filename), spot_img)
weights_path = 'D:/D/download/car1.h5'
model = load_model(weights_path)
class_dictionary = {}
class_dictionary[0] = 'empty'
class_dictionary[1] = 'occupied'
predicted_images = np.copy(image)
overlay = np.copy(image)
# cv_show('predicted_images', predicted_images)
cnt_empty = 0
all_spots = 0
for spot in spot_pos.keys():
all_spots += 1
(x1, y1, x2, y2) = spot
(x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2))
spot_img = image[y1:y2, x1:x2]
spot_img = cv.resize(spot_img, (48, 48))
# 预处理
img = spot_img / 255.
# 转换成4D tensor
spot_img = np.expand_dims(img, axis=0)
# 用训练好的模型进行训练
class_predicted = model.predict(spot_img)
inID = np.argmax(class_predicted[0])
label = class_dictionary[inID]
if label == 'empty':
cv.rectangle(overlay, (int(x1), int(y1)), (int(x2), int(y2)), [0, 255, 0], -1)
cnt_empty += 1
alpha = 0.5
cv.addWeighted(overlay, alpha, predicted_images, 1 - alpha, 0, predicted_images)
cv.putText(predicted_images, "Available: %d spots" % cnt_empty, (30, 95),
cv.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
cv.putText(predicted_images, "Total: %d spots" % all_spots, (30, 125),
cv.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
cv_show('predicted_images', predicted_images)
video_name = 'D:/D/download/parking_video.mp4'
cap = cv.VideoCapture(video_name)
count = 0
while 1:
ret, image = cap.read()
count += 1
if count == 5:
count = 0
new_image = np.copy(image)
overlay = np.copy(image)
cnt_empty = 0
all_spots = 0
color = [0, 255, 0]
alpha = 0.5
for spot in spot_pos.keys():
all_spots += 1
(x1, y1, x2, y2) = spot
(x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2))
spot_img = image[y1:y2, x1:x2]
spot_img = cv.resize(spot_img, (48, 48))
# 预处理
img = spot_img / 255.
# 转换成4D tensor
spot_img = np.expand_dims(img, axis=0)
# 用训练好的模型进行训练
class_predicted = model.predict(spot_img)
inID = np.argmax(class_predicted[0])
label = class_dictionary[inID]
if label == 'empty':
cv.rectangle(overlay, (int(x1), int(y1)), (int(x2), int(y2)), color, -1)
cnt_empty += 1
cv.addWeighted(overlay, alpha, new_image, 1 - alpha, 0, new_image)
cv.putText(new_image, "Available: %d spots" % cnt_empty, (30, 95),
cv.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
cv.putText(new_image, "Total: %d spots" % all_spots, (30, 125),
cv.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
cv.imshow('frame', new_image)
if cv.waitKey(10) & 0xFF == ord('q'):
break
cv.destroyAllWindows()
cap.release()
















 4369
4369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











