






目录
文献阅读-物理融合深度学习综述-PINN-有代码_哔哩哔哩_bilibili
鸣谢大佬
文献阅读-物理融合深度学习综述-PINN-有代码_哔哩哔哩_bilibili
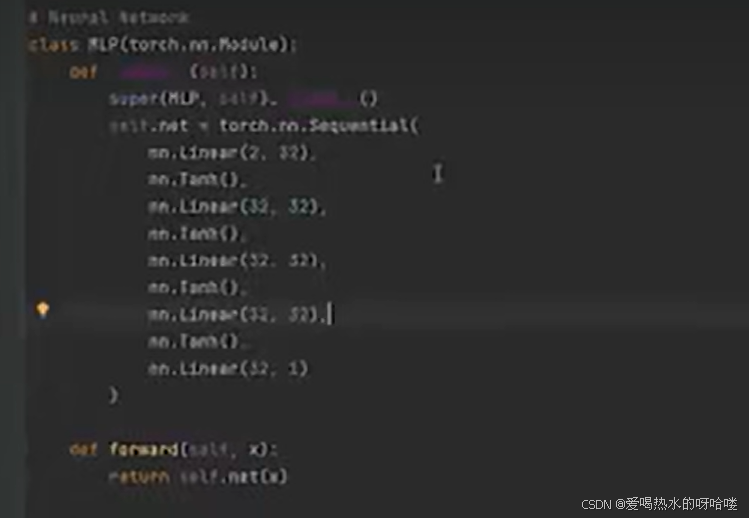
定义MLP(nn子类)
代码简介:
定义MLP(继承torch的nn)
定义 self的net属性:利用sq序列构建全连接层+激活(tanh)
定义forward(x)
return net(x)

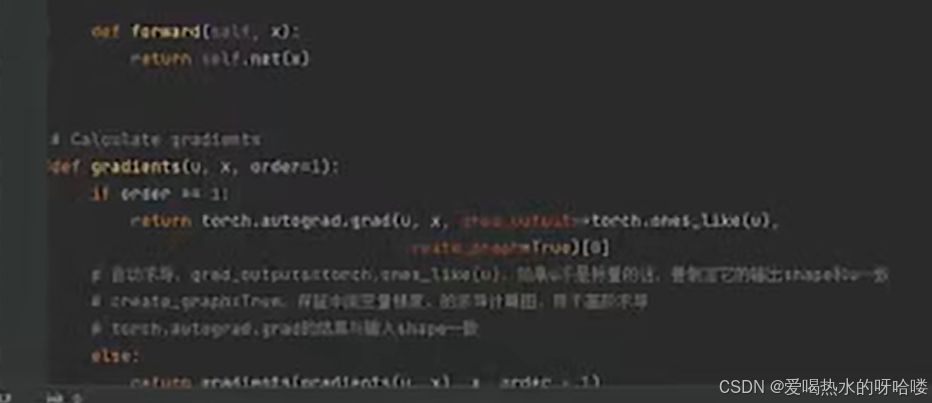
定义求导/梯度gradients(u,x,order=1)
嵌入torch的autograd的grad,把它改造成可以求多次导数的形式(利用递归写)

注意create graph要是true,才好算
关于另一种写法(批量求导在提取)

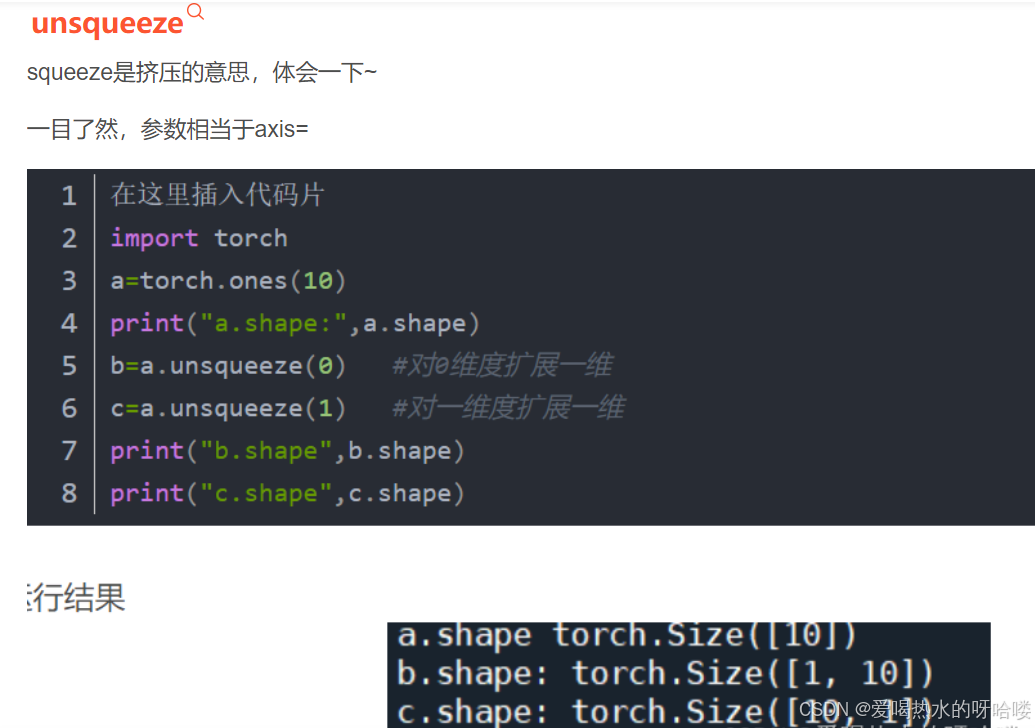
关于unsqueeze
接受的参数是第几个维度
-1当然就是倒数第一维的意思啦。
预计输出u_x的形状从(a,)变成(a,1)
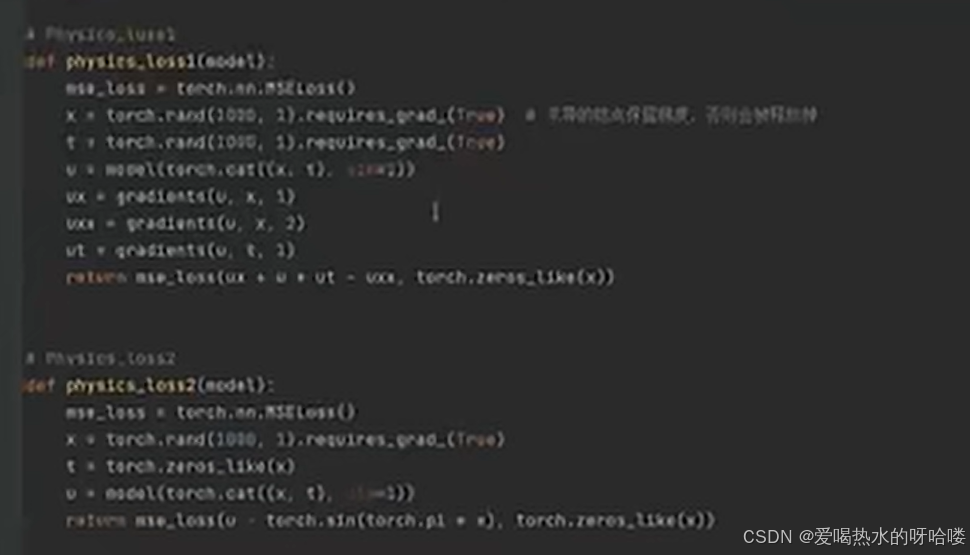
损失函数的定义

第一个物理损失loss1:
说是物理知识,其实就是自己造的待求解的PDE(ux+uut-uxx)与0的mse误差
第二个物理损失loss2:
说是物理知识,其实就是自己的初值和自己设置的pde初值(sinπx)的mse误差
loss是他俩和,可加权
注意点:
1.x&t保留梯度require grad=true
2.输出与u保持一致
训练train
代码简介:
类.train()(继承torchNN的train方法)
优化器:torch自带adam
优化对象应该是loss![]()
1000轮循环:
opt零梯度
计算loss
取出loss。depatch
反向传播(loss。backward())
优化器。step()

overlook(糊但可以看个大概)
跟刚才对应
定义类
上接forward
loss1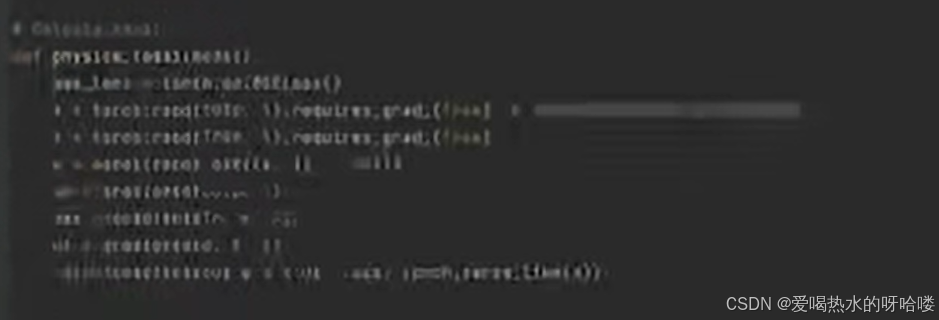
loss1和loss 2
train()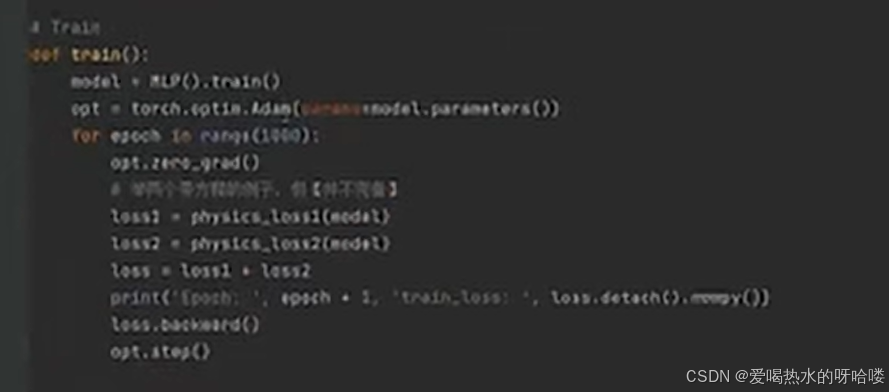 上接train及收尾if__name
上接train及收尾if__name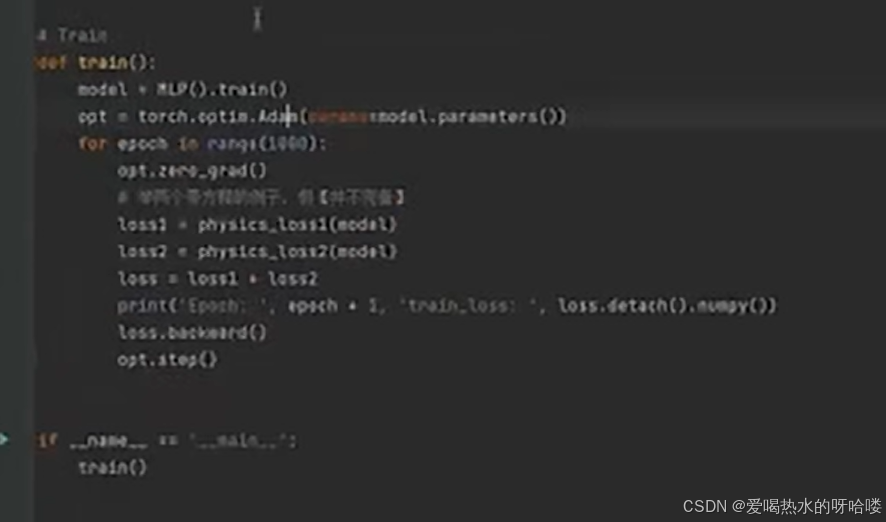
Q
いつ把loss放进opt了?还是说把loss。backward自动默认梯度取他的梯度【按优化器指示】下降?


















 6580
6580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









