






目录
摘要
本周阅读了一篇题目为Visualizing and Understanding Convolutional Networks的文献,它的主要内容是利用可视化神经网络内部的方法,利用Deconvnet把特征图转换为图像,使我们更清楚模型的内部构造。其次,用Numpy来实现了反向传播,利用手动数学推导以及代码实现的方式,自己对反向传播的步骤更加清楚。
ABSTRACT
This week I read a paper titled "Visualizing and Understanding Convolutional Networks", which focuses on visualizing the internals of neural networks by using Deconvnet to transform feature maps back to images, enabling us to better understand the model architecture. In addition, I implemented backpropagation manually using Numpy, which helped me gain a clearer understanding of the steps of backpropagation through mathematical derivation and code implementation.
一、文献阅读
1、文献基本信息
题目:Visualizing and Understanding Convolutional Networks
期刊:2013年ECCV
链接:https://arxiv.org/abs/1311.2901
2、ABSTRACT
虽然最近的CNN模型能够极大的提升在ImageNet上的识别结果,但是人们始终没有弄明白为什么CNN模型能够有如此出色的表现,或者说怎样才能改进模型呢。在文章中通过一种简单的可视化手段,可以对CNN网络中中间层进行可视化,从而可以起到一种诊断的作用,来改进当前以后的模型。
Although recent CNN models have greatly improved recognition results on ImageNet, people still do not fully understand why CNNs can achieve such excellent performance, or how to improve the models. This paper introduces a simple visualization technique that makes intermediate layers of a CNN interpretable, serving as a diagnostic tool to improve current and future models.
3、网络架构
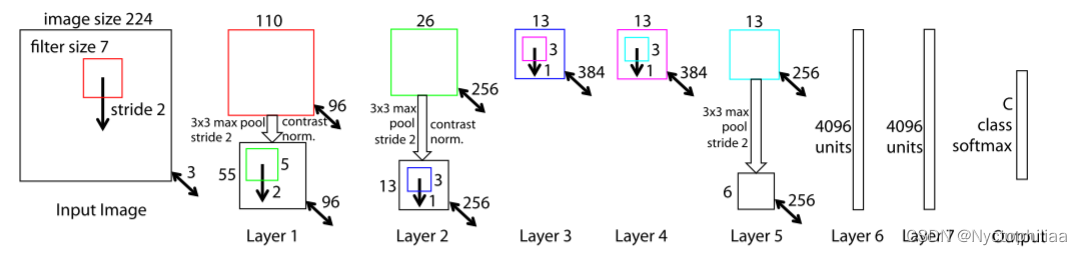
与AlexNet的架构相似,但是不同之处在于:
1、将第一层的filter size 从 11x11 减小到 7x7
2、将步长设为 2,而不是 4
3、除了输入和输出,一共有七层,其中五个卷积层用于提取特征,两个全连接层用于特征的分类。与一般的卷积神经网络不同的是,这个网络并不是卷积-池化的循环,而是卷积-非线性-池化的循环。
4、文献阅读
1、Introduction
目前神经网络领域有很大的进步,更大的数据集、GPU的发展、正则化技术的引入都让神经网络领域向着更强的方向发展。模型识别的效果越来越好,但是对模型的内部构造仍然是一头雾水,不能够很好地理解内部的结构,整个模型仍然是一个黑箱。
这篇论文提出了一种可视化神经网络内部的方法,并利用这种方法,对现有的神经网络的结构进行可视化和检验,基于检验结果改进网络的结构,让识别的正确率进一步提高。
2、创新点
1、Visualization with a Deconvnet
Deconvet是可以看做是卷积网络(convnet)的反操作,convnet是把图像映射为特征图(feature map),因此Deconvnet是把特征图转换为图像。Deconvnet最初发表的目的是为非监督学习的,在本文中作者使用Deconvnet并不具有学习能力,只是用于可视化已经训练好的模型。
为了对convnet的各层进行可视化,需要在convnet的各层都加上Deconvnet,如下图所示:

图中上部的右侧为卷积网络,左侧为反卷积网络。可以从图中看出,最初输入图像进入卷积神经网络,经过conv-rectified linear-pooling之后得到本层的输出结果,然后把输出结果作为输入进入反卷积神经网络中,经过Unpooling-rectified linear-deconv的处理,最终重建出输入图像。
Unpooling:在卷积神经网络中,max pooling是一个不可逆的过程,但是作者提出可以通过记录每个窗口最大值像素坐标的方式对max pooling过程进行反操作,在Unpooling时,把最大值临近区域部分的像素值设为该最大值像素的像素值。如上图所示,图中的下部的右侧和左侧图像分别表示pooling和Unpooling的操作过程,中间记录的灰黑相间的网格记录最大值所在的位置,其中灰色部分表示最大值的位置。
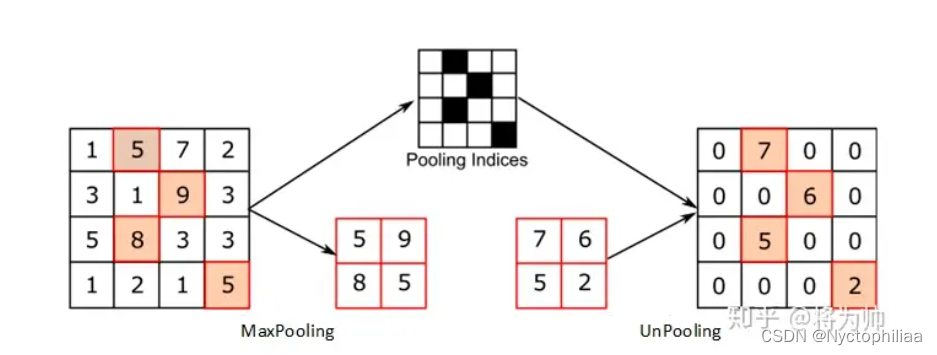
Rectification:由于作者实验的网络中激活函数都是ReLU函数,而ReLU函数的作用是保证feature map的值总是正的,因此直接对Unpooling的重建结果进行ReLU操作进行反操作,保证值为正即可。
Filter(deconv):卷积网络通过对输入的2D图像进行卷积得到输出的feature map,因此为了进行反操作,直接对ReLU反操作后的结果进行卷积操作即可,卷积核即为原卷积核的转置(即对原卷积核进行水平和竖直方向的翻转)。
2、Architecture Selection
通过可视化已经学习到的网络模型各层提取的特征可以对我们改进模型有一定程度的帮助,作者通过对AlexNet网络模型的可视化结果发现AlexNet的可改进之处。如图6所示,AlexNet的第1层提取了很多高频和低频信息,但是对中频的信息提取的较少,同时由于AlexNet采用了比较大的stride(步长)在第2层中提取的特征中有混叠效应。作者根据这些问题提出了如下解决方法:
(1)把第1层的卷积核大小由11×11变为7×7;
(2)把原有为4的stride改为2;改变这些以后作者提升了AlexNet的识别效果。
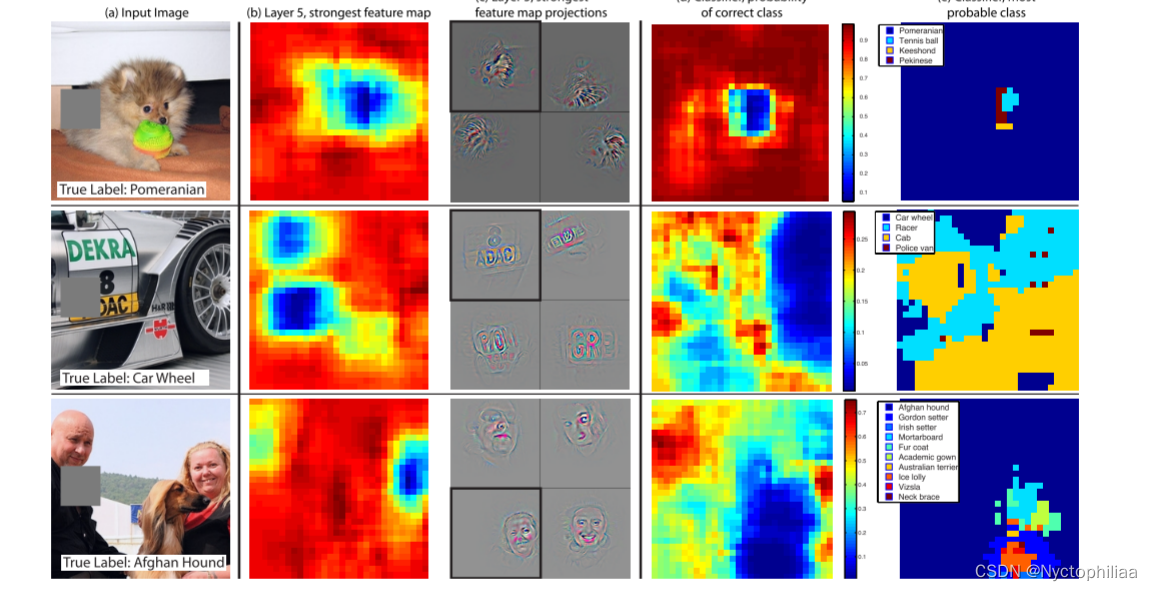
3、 Occlusion Sensitivity
作者提出这样一个问题,即CNN对物体进行识别时,是真的定位到物体上了,还是只是通过识别周围的环境呢?图7展示了作者进行的一系列实验的结果,作者使用一个灰色方块依次遮挡图像的诸个部分,发现只要遮挡了待识别物体的物体以后,将图像识别为该物体的概率迅速下降,这证明了CNN识别物体时是真的定位到该物体并对其进行识别的。
3、实验过程
1、ImageNet 2012
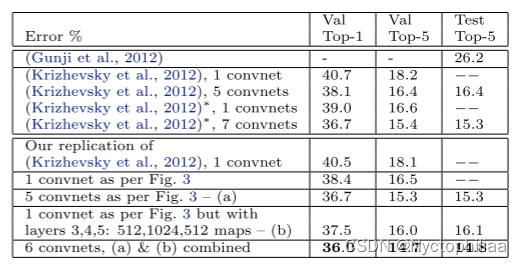
该数据集包含1.3M / 50k /100k个培训/验证/测试样本,分布在1000多个类别中。表2显示了我们上这个数据集上的结果。
使用(Krizhevsky et al。,2012)中指定的确切的体系结构,我们试图在验证集上复制它们的结果。我们达到的误差率和他们在ImageNet 2012验证集中报告的值的误差不到0.1%。
我们分析在4.1节中概述的改变架构(第1层中使用7×7滤波器,1、2层中卷积步长为2)的模型性能。图3所示模型,显著优于(Krizhevsky等人,2012)的体系结构,将其单一模型结果击败了1.7%(测试前五名)。当我们组合多个模型时,我们获得14.8%的测试误差,这是该数据集上发布的最佳性能(尽管只使用了2012年的训练集)。我们注意到,这个错误率几乎是ImageNet 2012分类挑战中最重要的non-convnet条目26.2%的错误率(Gunji et al。,2012)的一半。
2、改变ImageNet模型的大小
我们首先通过调整层的大小或完全去除它们来探索(Krizhevsky et al。,2012)的体系结构。在每一种情况下,模型都是从头开始用修改后的架构进行培训的。去除全连接层(6,7)只增加了轻微的误差。这是令人惊讶的,因为它们包含大部分模型参数。移除中间的两个卷积层队差错率影响也相对较小。但是,除去全部的中间卷积层和全连接层产生的只有4层的模型的性能显著变差。这表明模型的整体深度对于获得良好性能很重要。在表3中,我们修改了我们如图3的模型。改变全连接层的大小对性能几乎没有影响(对于(Krizhevsky et al。,2012)模型也是如此)。但是,增加中间卷积层的大小可以提高性能。但增加这些的同时,也增大了全连接层过度拟合。

3、Caltech-101
我们遵循(Fei-fei等,2006)的程序,每类随机选择15或30幅图像进行训练,每类测试50幅图像,表4中报告了每类准确度的平均值,使用5次训练/测试折叠。训练30张图像/类的数据用时17分钟。预先训练的模型在30幅图像/类上的结果比(Bo et al。,2013)的成绩提高2.2%。然而,从零开始训练的convnet模型非常糟糕,只能达到46.5%。
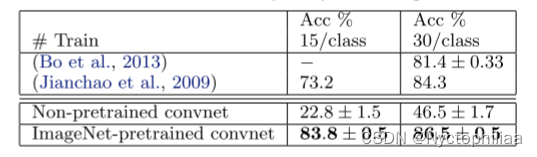
4、Caltech-256
我们按照(Gri ffi等,2006)的程序,为每个类选择15,30,45或60个训练图像,表5中报告了每类精度的平均值。我们的ImageNet预训练模型在每类60训练图像上以74.2%比55.2%的显著差别击败了Bo等人获得的当前最先进的结果。(Bo et al。,2013)。但是,与Caltech-101一样,从零开始训练的模型效果并不理想。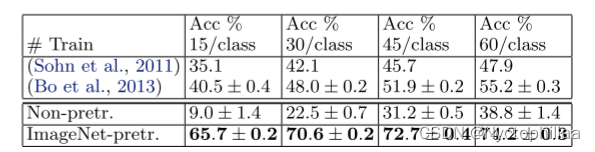
4、结论
我们探索了大型卷积神经网络在图像分类任务上的表现。首先,我们提出了一种新颖的方法来可视化模型中的特征。这表明特征是有意义的模式,而不是随机的。它们展现了合成性、不变性等直观性质。通过可视化我们还能诊断并改进模型。然后,我们通过遮挡实验证明模型对局部结构也很敏感,不仅使用场景上下文。模型深度比宽度更关键。最后,我们测试模型在其他数据集上的泛化能力。对于类似的Caltech数据集,我们取得明显优势。但是在Pascal数据集上存在域适应问题。
二、用Numpy实现反向传播
一、数学推导
和
是输入层和隐藏层的偏置值(也可以先不看偏置值),下面推导默认使用偏置值,只不过b用
表示的,这里的
就是b,
默认为1。




二、代码实现
图中就是完整的一个反向传播过程,利用这个过程,我们用Numpy来实现反向传播。具体代码如下:
import numpy as np
#np.exp()函数是求e的x的平方
def sigmoid(x):
return 1 / (1 + np.exp(-1 * x))
#导数等于s*(1-s)
def d_sigmoid(x):
s = sigmoid(x)
return s * (np.ones(s.shape) - s)
#损失函数MSE
def mean_square_loss(s, y):
return np.sum(np.square(s - y) / 2)
#损失函数MSE的导数
def d_mean_square_loss(s, y):
return s - y
# y1 = np.matmul(X, W1) + b1: 输入层到隐藏层的映射
# - z1 = sigmoid(y1): 隐藏层的激活函数
# - y2 = np.matmul(z1, W2) + b2: 隐藏层到输出层的映射
# - z2 = sigmoid(y2): 输出层的激活函数
def forward(W1, W2, b1, b2, X, y):
# 输入层到隐藏层
y1 = np.matmul(X, W1) + b1 # [2, 3]
z1 = sigmoid(y1) # [2, 3]
# 隐藏层到输出层
y2 = np.matmul(z1, W2) + b2 # [2, 2]
z2 = sigmoid(y2) # [2, 2]
# 求均方差损失
loss = mean_square_loss(z2, y)
return y1, z1, y2, z2, loss
def backward_update(epochs, lr=0.01):
# 随便创的数据和权重,偏置值,小伙伴们也可以使用numpy的ranodm()进行随机初始化
X = np.array([[0.6, 0.1], [0.3, 0.6]])
y = np.array([0, 1])
W1 = np.array([[0.4, 0.3, 0.6], [0.3, 0.4, 0.2]])
b1 = np.array([0.4, 0.1, 0.2])
W2 = np.array([[0.2, 0.3], [0.3, 0.4], [0.5, 0.3]])
b2 = np.array([0.1, 0.2])
# 先进行一次前向传播
y1, z1, y2, z2, loss = forward(W1, W2, b1, b2, X, y)
for i in range(epochs):
# 求得隐藏层的学习信号(损失函数导数乘激活函数导数)
ds2 = d_mean_square_loss(z2, y) * d_sigmoid(y2)
# 根据上面推导结果式子(2.4不看学习率)--->(学习信号乘隐藏层z1的输出结果),注意形状需要转置
dW2 = np.matmul(z1.T, ds2)
# 对隐藏层的偏置梯度求和(式子2.6),注意是对列求和
db2 = np.sum(ds2, axis=0)
# 式子(2.5)前两个元素相乘
dx = np.matmul(ds2, W2.T)
# 对照式子(2.3)
ds1 = d_sigmoid(y1) * dx
# 式子(2.5)
dW1 = np.matmul(X.T, ds1)
# 对隐藏层的偏置梯度求和(式子2.7),注意是对列求和
db1 = np.sum(ds1, axis=0)
# 参数更新
W1 = W1 - lr * dW1
b1 = b1 - lr * db1
W2 = W2 - lr * dW2
b2 = b2 - lr * db2
y1, z1, y2, z2, loss = forward(W1, W2, b1, b2, X, y)
# 每隔100次打印一次损失
if i % 100 == 0:
print('第%d批次' % (i / 100))
print('当前损失为:{:.4f}'.format(loss))
print(z2)
# sigmoid激活函数将结果大于0.5的值分为正类,小于0.5的值分为负类
z2[z2 > 0.5] = 1
z2[z2 < 0.5] = 0
print(z2)
if __name__ == '__main__':
backward_update(epochs=50001, lr=0.01)
运行结果如下:
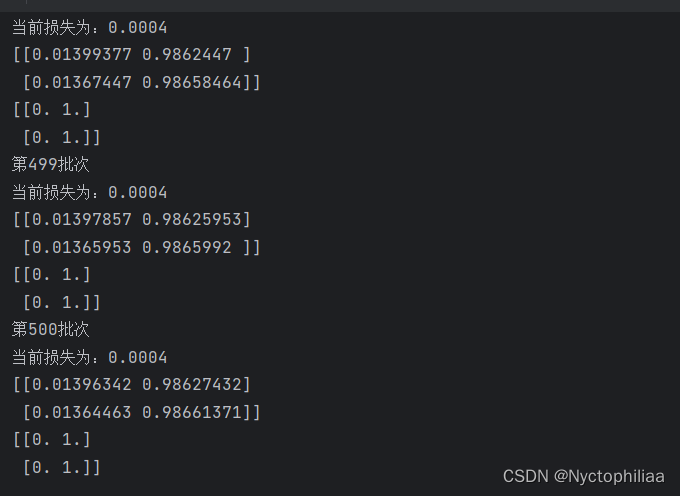
训练50000次后,损失差不多收敛也快接近0了,这就是反向传播的代码。
总结
通过反向传播,不断迭代更新参数,损失值也越来越接近于0,从而我们得到了我们需要的参数。下周我将对RNN的内容进行学习。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









