






目录
摘要
本周我阅读了一篇名为《Attention Is All You Need》的文献。该文提出的Transformer模型彻底抛弃了以往的循环和卷积操作,全面采用了注意力机制,不仅具备更强大的并行计算能力,还显著提升了训练效率。其革新性的设计为自然语言处理任务带来了重大的突破。其次我深入学习了Self-attention和Transformer的相关内容,并对它们进行了详尽的分析。Self-attention机制通过对输入序列中不同位置的元素分配不同的注意力权重,实现了更灵活、更全面的信息捕捉。与传统的attention机制相比,Self-attention在处理序列数据时表现出更大的灵活性和表达能力。
ABSTRACT
This week, I read a paper titled "Attention Is All You Need" . The proposed Transformer model completely discards the conventional recurrent and convolutional operations, adopting an attention mechanism comprehensively. Not only does it possess more potent parallel computing capabilities, but it also significantly enhances training efficiency. The innovative design introduced by it marks a significant breakthrough in natural language processing tasks.
Furthermore, in-depth study and meticulous analysis were conducted on the content related to Self-attention and Transformer. The Self-attention mechanism achieves greater flexibility and comprehensive information capture by assigning varying attention weights to elements at different positions in the input sequence. In comparison to the traditional attention mechanism, Self-attention demonstrates greater flexibility and expressive power when dealing with sequential data.
一、文献阅读
1、题目
题目:Attention Is All You Need
链接:https://arxiv.org/abs/1706.03762
期刊/会议:Advances in neural information processing systems(neurIPS)
2、摘要
现在主流的序列转录模型主要基于是复杂的循环结构的RNN和CNN架构,通过其中的编码器Encoder和解码器Decoder来实现。而本文提出的Transformer完全摒弃了之前的循环和卷积操作,完全基于注意力机制,拥有更强的并行能力,训练效率也得到较高提升。
The mainstream sequence transduction models are mainly based on complex recurrent structures of RNN and CNN architectures, which implement sequence transduction through the encoder and decoder. However, the Transformer proposed in this paper completely abandons the previous recurrent and convolutional operations and is entirely based on the attention mechanism, possessing stronger parallelization ability and achieving significantly improved training efficiency.
3、网络架构
Transformer的模型分为encoder和decoder两部分,即编码器和解码器两部分。对于原始输入(x1,x2,...,xn),编码器将其转化为机器可理解的向量(z1,z2,...,zn),解码器将编码器的输出作为输入,进而生成最终的解码结果(y1,y2,...,yn)
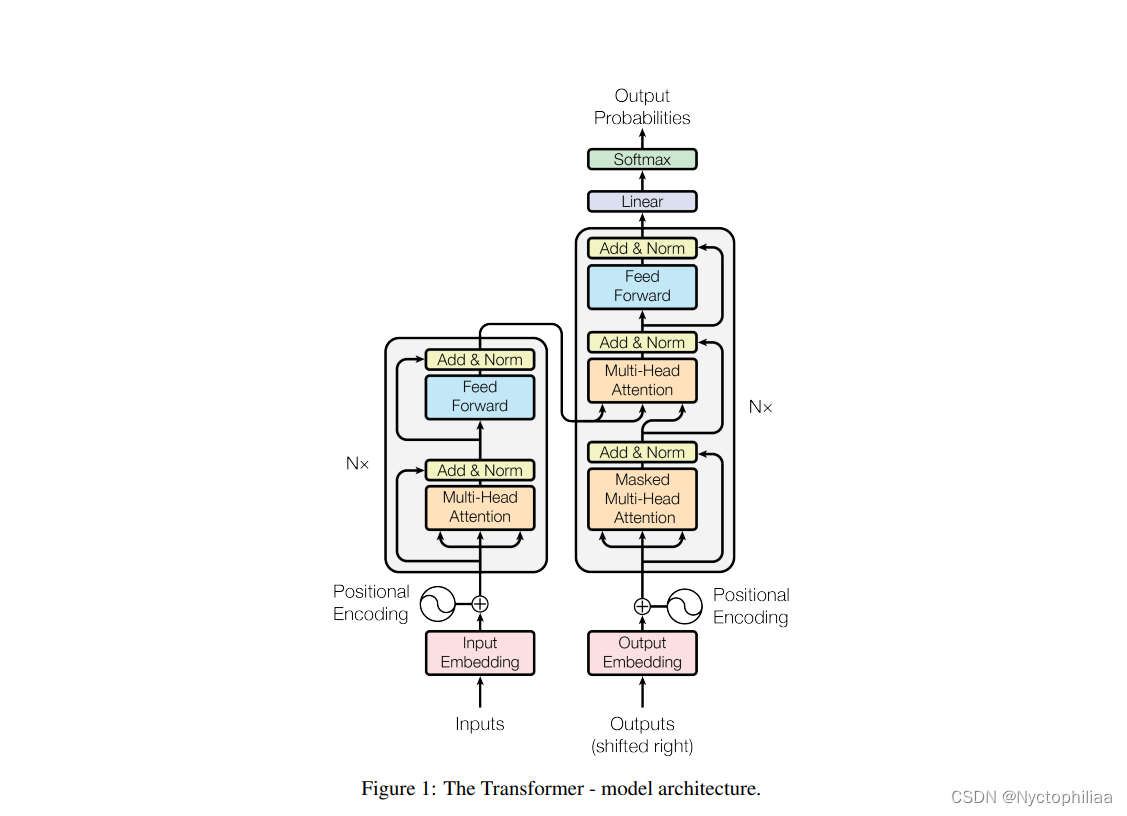
Transformer 中单词的输入表示 x由单词 Embedding 和位置 Embedding (Positional Encoding) 相加得到。其中,单词的 Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到;位置 Embedding 表示单词出现在句子中的位置,因为 Transformer 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于 NLP 来说非常重要。所以 Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置。位置 Embedding 用 PE表示,PE 的维度与单词 Embedding 是一样的。PE 可以通过训练得到,也可以使用某种公式计算得到。在 Transformer 中采用了后者,计算公式如下:

其中,pos 表示单词在句子中的位置,d 表示 PE的维度 (与词 Embedding 一样),2i 表示偶数的维度,2i+1 表示奇数维度 (即 2i≤d, 2i+1≤d)。使用这种公式计算 PE 有以下的好处:
1、使 PE 能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子是有 20 个单词,突然来了一个长度为 21 的句子,则使用公式计算的方法可以计算出第 21 位的 Embedding。
2、可以让模型容易地计算出相对位置,对于固定长度的间距 k,PE(pos+k) 可以用 PE(pos) 计算得到。因为 Sin(A+B) = Sin(A)Cos(B) + Cos(A)Sin(B), Cos(A+B) = Cos(A)Cos(B) - Sin(A)Sin(B)。
4、文献解读
一、Introduction
在RNN、LSTM、GRU这些模型中,有许多不足,必须说:从左到右一步步计算,因此很难并行计算;过早的历史信息可能被丢弃,时序信息一步一步向后传递;内存开销大,训练时间慢。所以在本文中,作者引入了注意力机制:注意力机制可以在RNN上使用,通过注意力机制把encoder的信息传给decoder,可以允许不考虑输入输出序列的距离建模。并且提出了Transformer:本文的 Transformer 完全不用RNN,这是一种避免使用循环的模型架构,完全依赖于注意机制来绘制输入和输出之间的全局依赖关系,并行度高,计算时间短。
二、创新点
1、Scaled DotProduct Attention—缩放的点积注意力机制
Scaled Dot-Product Attention是特殊attention,输入包括查询Q和键K的维度dk 以及值V的维度dv 。计算查询和键的点积,将每个结果除 ,然后用 softmax() 函数来获得值的权重。
在实际使用中,我们同时计算一组查询的注意力函数,并一起打包成矩阵 Q。键和值也一起打包成矩阵 K 和 V。
虽然对于较小的 dk ,additive attention和dot-product(multi-plicative) attention两者的表现相似,但在较大的 dk 时,加法注意力要优于没有缩放机制的点乘注意力。我们认为在较大的 dk 时,点乘以数量级增长,将 softmax 函数推入梯度极小的区域,值就会更加向两端靠拢,算梯度的时候,梯度比较小。为了抵抗这种影响,我们使用
缩放点乘结果。
2、MultiHead Attention—多头注意力机制
不再使用一个attention函数,而是使用不同的学习到的线性映射将queries,keys和values分别线性投影到 dq、dk 和 dv 维度 h 次。然后在queries,keys和values的这些投影版本中的每一个上并行执行注意力功能,产生h个注意力函数。最后将这些注意力函数拼接并再次投影,产生最终输出值。
三、实验过程
1、数据集
标准的WMT 2014英语-德语数据集: 约450万个句子对;
WMT 2014英法数据集: 3600万个句子对, 每个训练批次的句子对包含大约25000个源词符和25000个目标词符
2、评价指标
模型在两个数据集上的BLEU评分
3、超参数
采用 Adam优化器,β1 = 0.9, β2 = 0.98及ϵ= ,dropout=0.1,warmup_steps: 4000
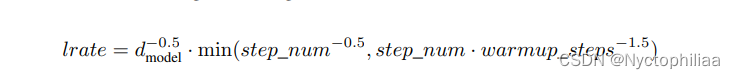
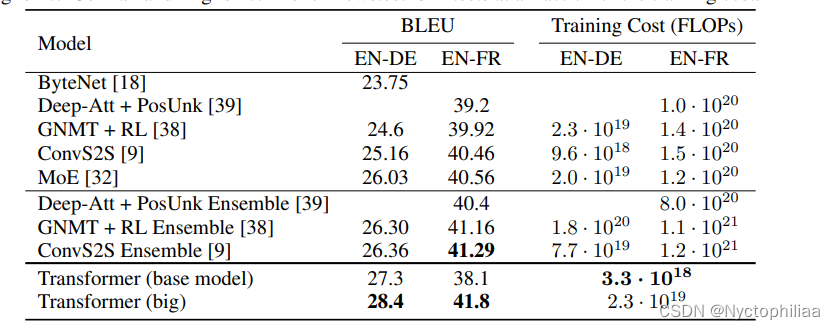
4、实验结果
WMT 2014英语-德语翻译任务表现
(1)评分更高: 取得了28.4的BLEU评分。在现有的表现最好模型的基础上,包括整合模型,提高了2个BLEU评分。
(2)成本更小: 训练成本只是这些模型的一小部分
WMT 2014英语-法语翻译任务表现
(1)评分更高: 大型模型的BLEU得分为41.8,超过了之前发布的所有单一模型
(2)成本更小: 训练成本低于先前最先进模型的1 ∕ 4
四、结论
作者提出了Transformer,第一个完全基于attention的序列转换模型,用multi-headed self-attention取代了encoder-decoder架构中最常用的recurrent layers。对于翻译任务,Transformer比基于循环或卷积层的体系结构训练更快。 在WMT 2014英语-德语和WMT 2014英语-法语翻译任务中,取得了最好的结果。 在前面的任务中,作者的模型甚至胜过以前报道过的所有整合模型。
二、Self-Attention
一、如何运用自注意力机制?

以上是对Thinking Machines这句话进行自注意力的全过程,最终得到z1和z2两个新向量。
其中z1表示的是thinking这个词向量的新的向量表示(通过thinking这个词向量,去查询和thinking machine这句话里面每个单词和thinking之间的相似度)。
也就是说新的z1依然是 thinking 的词向量表示,只不过这个词向量的表示蕴含了 thinking machines 这句话对于 thinking 而言哪个更重要的信息。
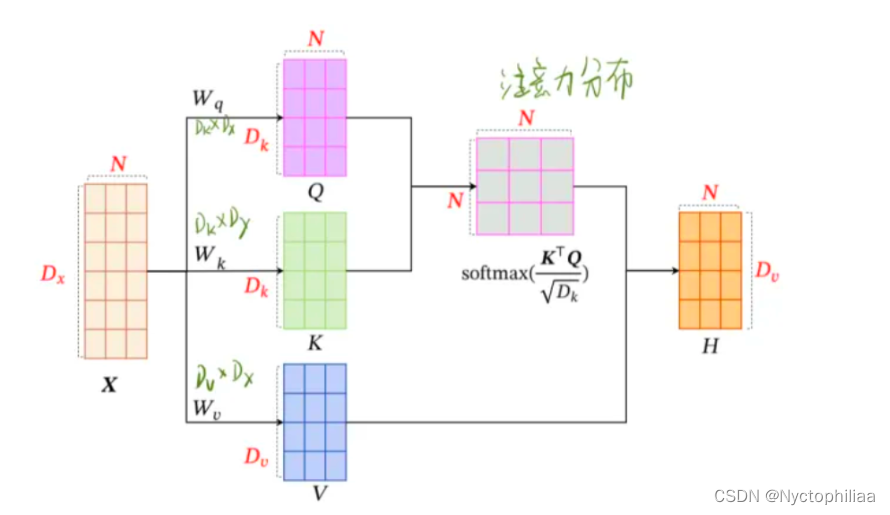
二、自注意力机制如何实现
针对全连接神经网络存在的这个问题,通过自注意力机制来解决,自注意力机制实际上是想让机器注意到整个输入中不同部分之间的相关性,它的实现方法如下:


三、Transformer代码实现
一、数据准备
首先自制一个数据集sentences,其中第一列是中文源句子,第二列是英文句子,第三列是对应的翻译。src_vocab和tgt_vocab将sentences中的中文句子和英文句子定义为字典的形式,使得每一个词都有唯一的整数索引
import math
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
#自制数据集
# Encoder_input Decoder_input Decoder_output
sentences = [['我 是 学 生 P' , 'S I am a student' , 'I am a student E'], # S: 开始符号
['我 喜 欢 学 习', 'S I like learning P', 'I like learning P E'], # E: 结束符号
['我 是 男 生 P' , 'S I am a boy' , 'I am a boy E']] # P: 占位符号,如果当前句子不足固定长度用P占位 pad补0
#定义一个中文字典,将每一个汉字定义一个唯一的整数索引
src_vocab = {'P':0, '我':1, '是':2, '学':3, '生':4, '喜':5, '欢':6,'习':7,'男':8} # 词源字典 字:索引
#{scr_idx2word:{0: 'P', 1: '我', 2: '是', 3: '学', 4: '生', 5: '喜', 6: '欢', 7: '习', 8: '男'}
src_idx2word = {src_vocab[key]: key for key in src_vocab}
src_vocab_size = len(src_vocab) # 字典字的个数
tgt_vocab = {'S':0, 'E':1, 'P':2, 'I':3, 'am':4, 'a':5, 'student':6, 'like':7, 'learning':8, 'boy':9}
idx2word = {tgt_vocab[key]: key for key in tgt_vocab} # 把目标字典转换成 索引:字的形式
tgt_vocab_size = len(tgt_vocab) # 目标字典尺寸
src_len = len(sentences[0][0].split(" ")) # Encoder输入的最大长度 5
tgt_len = len(sentences[0][1].split(" ")) # Decoder输入输出最大长度 5
src_len,tgt_len
以下代码是把sentences转换成字典索引,生成的输出是三个tensor,其中每一个tensor中的数字代表的是这一句话中的单词所对应的整数索引
# 把sentences 转换成字典索引
def make_data(sentences):
enc_inputs, dec_inputs, dec_outputs = [], [], []
for i in range(len(sentences)):
enc_input = [[src_vocab[n] for n in sentences[i][0].split()]]
dec_input = [[tgt_vocab[n] for n in sentences[i][1].split()]]
dec_output = [[tgt_vocab[n] for n in sentences[i][2].split()]]
enc_inputs.extend(enc_input)
dec_inputs.extend(dec_input)
dec_outputs.extend(dec_output)
return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)
enc_inputs, dec_inputs, dec_outputs = make_data(sentences)
print(enc_inputs)
print(dec_inputs)
print(dec_outputs)二、 自定义数据集函数
这段代码定义了一个自定义的 PyTorch 数据集类
MyDataSet,以及使用该数据集创建一个数据加载器loader。
#自定义数据集函数
class MyDataSet(Data.Dataset):
def __init__(self, enc_inputs, dec_inputs, dec_outputs):
super(MyDataSet, self).__init__()
self.enc_inputs = enc_inputs
self.dec_inputs = dec_inputs
self.dec_outputs = dec_outputs
def __len__(self):
return self.enc_inputs.shape[0]
def __getitem__(self, idx):
return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx]
loader = Data.DataLoader(MyDataSet(enc_inputs, dec_inputs, dec_outputs), 2, True) 三、参数设置
d_model = 512 # 字 Embedding 的维度
d_ff = 2048 # 前向传播隐藏层维度
d_k = d_v = 64 # K(=Q), V的维度
n_layers = 6 # 有多少个encoder和decoder
n_heads = 8 # Multi-Head Attention设置为8四、定义位置信息

class PositionalEncoding(nn.Module):
def __init__(self,d_model,dropout=0.1,max_len=5000):
super(PositionalEncoding,self).__init__()
self.dropout = nn.Dropout(p=dropout)
pos_table = np.array([
[pos / np.power(10000, 2 * i / d_model) for i in range(d_model)]
if pos != 0 else np.zeros(d_model) for pos in range(max_len)])
pos_table[1:, 0::2] = np.sin(pos_table[1:, 0::2]) # 字嵌入维度为偶数时
pos_table[1:, 1::2] = np.cos(pos_table[1:, 1::2]) # 字嵌入维度为奇数时
self.pos_table = torch.FloatTensor(pos_table).cuda() # enc_inputs: [seq_len, d_model]
def forward(self,enc_inputs): # enc_inputs: [batch_size, seq_len, d_model]
enc_inputs += self.pos_table[:enc_inputs.size(1),:]
return self.dropout(enc_inputs.cuda())
五、停掉用词
Mask句子中没有实际意义的占位符,例如’我 是 学 生 P’ ,P对应句子没有实际意义,所以需要被Mask,Encoder_input 和Decoder_input占位符都需要被Mask。
这就是为了处理,句子不一样长,但是输入有需要定长,不够长的pad填充,但是计算又不需要这个pad,所以mask掉这个函数最核心的一句代码是 seq_k.data.eq(0),这句的作用是返回一个大小和 seq_k 一样的 tensor,只不过里面的值只有 True 和 False。如果 seq_k 某个位置的值等于 0,那么对应位置就是 True,否则即为 False。举个例子,输入为 seq_data = [1, 2, 3, 4, 0],seq_data.data.eq(0) 就会返回 [False, False, False, False, True]
def get_attn_pad_mask(seq_q,seq_k):
batch_size, len_q = seq_q.size()# seq_q 用于升维,为了做attention,mask score矩阵用的
batch_size, len_k = seq_k.size()
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # 判断 输入那些含有P(=0),用1标记 ,[batch_size, 1, len_k]
return pad_attn_mask.expand(batch_size,len_q,len_k) # 扩展成多维度 [batch_size, len_q, len_k]六、Decoder输入Mask
用来Mask未来输入信息,返回的是一个上三角矩阵。比如我们在中英文翻译时候,会先把"我是学生"整个句子输入到Encoder中,得到最后一层的输出后,才会在Decoder输入"S I am a student"(s表示开始),但是"S I am a student"这个句子我们不会一起输入,而是在T0时刻先输入"S"预测,预测第一个词"I";在下一个T1时刻,同时输入"S"和"I"到Decoder预测下一个单词"am";然后在T2时刻把"S,I,am"同时输入到Decoder预测下一个单词"a",依次把整个句子输入到Decoder,预测出"I am a student E"。
def get_attn_subsequence_mask(seq): # seq: [batch_size, tgt_len]
attn_shape = [seq.size(0), seq.size(1), seq.size(1)] # 生成上三角矩阵,[batch_size, tgt_len, tgt_len]
subsequence_mask = np.triu(np.ones(attn_shape), k=1)
subsequence_mask = torch.from_numpy(subsequence_mask).byte() # [batch_size, tgt_len, tgt_len]
return subsequence_mask七、计算注意力信息、残差和归一化

class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask): # Q: [batch_size, n_heads, len_q, d_k]
# K: [batch_size, n_heads, len_k, d_k]
# V: [batch_size, n_heads, len_v(=len_k), d_v]
# attn_mask: [batch_size, n_heads, seq_len, seq_len]
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size, n_heads, len_q, len_k]
scores.masked_fill_(attn_mask, -1e9) # 如果是停用词P就等于 0
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V) # [batch_size, n_heads, len_q, d_v]
return context, attn八、多头注意力机制
计算注意力信息
矩阵会拆分成 8 个小矩阵。注意传入的 input_Q, input_K, input_V, 在Encoder和Decoder的第一次调用传入的三个矩阵是相同的,但 Decoder的第二次调用传入的三个矩阵input_Q 等于 input_K 不等于 input_V,因为decoder中是计算的cross attention,如下图所示.
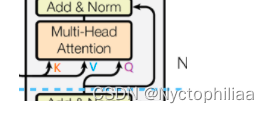
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
def forward(self, input_Q, input_K, input_V, attn_mask): # input_Q: [batch_size, len_q, d_model]
# input_K: [batch_size, len_k, d_model]
# input_V: [batch_size, len_v(=len_k), d_model]
# attn_mask: [batch_size, seq_len, seq_len]
residual, batch_size = input_Q, input_Q.size(0)
Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # Q: [batch_size, n_heads, len_q, d_k]
K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # K: [batch_size, n_heads, len_k, d_k]
V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size, n_heads, seq_len, seq_len]
context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask) # context: [batch_size, n_heads, len_q, d_v]
# attn: [batch_size, n_heads, len_q, len_k]
context = context.transpose(1, 2).reshape(batch_size, -1, n_heads * d_v) # context: [batch_size, len_q, n_heads * d_v]
output = self.fc(context) # [batch_size, len_q, d_model]
return nn.LayerNorm(d_model).cuda()(output + residual), attn
九、前馈神经网络
输入inputs ,经过两个全连接层,得到的结果再加上 inputs (残差),再做LayerNorm归一化。LayerNorm归一化可以理解层是把Batch中每一句话进行归一化。
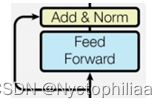
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc = nn.Sequential(
nn.Linear(d_model, d_ff, bias=False),
nn.ReLU(),
nn.Linear(d_ff, d_model, bias=False))
def forward(self, inputs): # inputs: [batch_size, seq_len, d_model]
residual = inputs
output = self.fc(inputs)
return nn.LayerNorm(d_model).cuda()(output + residual) # [batch_size, seq_len, d_model]
十、encoder layer(block)
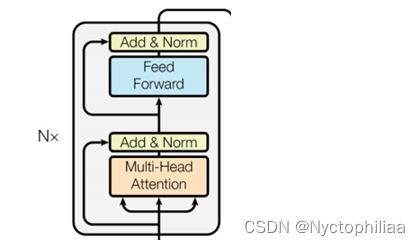
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention() # 多头注意力机制
self.pos_ffn = PoswiseFeedForwardNet() # 前馈神经网络
def forward(self, enc_inputs, enc_self_attn_mask): # enc_inputs: [batch_size, src_len, d_model]
#输入3个enc_inputs分别与W_q、W_k、W_v相乘得到Q、K、V # enc_self_attn_mask: [batch_size, src_len, src_len]
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, # enc_outputs: [batch_size, src_len, d_model],
enc_self_attn_mask) # attn: [batch_size, n_heads, src_len, src_len]
enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size, src_len, d_model]
return enc_outputs, attn十一、Encoder
第一步,中文字索引进行Embedding,转换成512维度的字向量。第二步,在子向量上面加上位置信息。第三步,Mask掉句子中的占位符号。第四步,通过6层的encoder(上一层的输出作为下一层的输入)。

class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model)
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
def forward(self, enc_inputs):
'''
enc_inputs: [batch_size, src_len]
'''
enc_outputs = self.src_emb(enc_inputs) # [batch_size, src_len, d_model]
enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, src_len, d_model]
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # [batch_size, src_len, src_len]
enc_self_attns = []
for layer in self.layers:
# enc_outputs: [batch_size, src_len, d_model], enc_self_attn: [batch_size, n_heads, src_len, src_len]
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns
十二、decoder layer(block)¶
decoder两次调用MultiHeadAttention时,第一次调用传入的 Q,K,V 的值是相同的,都等于dec_inputs,第二次调用 Q 矩阵是来自Decoder的输入。K,V 两个矩阵是来自Encoder的输出,等于enc_outputs。
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask): # dec_inputs: [batch_size, tgt_len, d_model]
# enc_outputs: [batch_size, src_len, d_model]
# dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
# dec_enc_attn_mask: [batch_size, tgt_len, src_len]
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs,
dec_inputs, dec_self_attn_mask) # dec_outputs: [batch_size, tgt_len, d_model]
# dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs,
enc_outputs, dec_enc_attn_mask) # dec_outputs: [batch_size, tgt_len, d_model]
# dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs = self.pos_ffn(dec_outputs) # dec_outputs: [batch_size, tgt_len, d_model]
return dec_outputs, dec_self_attn, dec_enc_attn
十三、Decoder
第一步,英文字索引进行Embedding,转换成512维度的字向量。第二步,在子向量上面加上位置信息。第三步,Mask掉句子中的占位符号和输出顺序.第四步,通过6层的decoder(上一层的输出作为下一层的输入)
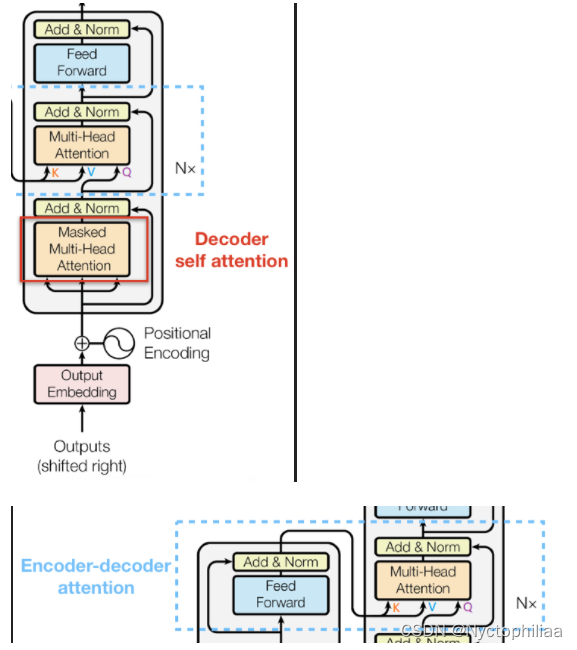
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self, dec_inputs, enc_inputs, enc_outputs):
'''
dec_inputs: [batch_size, tgt_len]
enc_intpus: [batch_size, src_len]
enc_outputs: [batch_size, src_len, d_model]
'''
dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]
dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1).cuda() # [batch_size, tgt_len, d_model]
# Decoder输入序列的pad mask矩阵(这个例子中decoder是没有加pad的,实际应用中都是有pad填充的)
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs).cuda() # [batch_size, tgt_len, tgt_len]
# Masked Self_Attention:当前时刻是看不到未来的信息的
dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs).cuda() # [batch_size, tgt_len, tgt_len]
# Decoder中把两种mask矩阵相加(既屏蔽了pad的信息,也屏蔽了未来时刻的信息)
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask), 0).cuda() # [batch_size, tgt_len, tgt_len]
# 这个mask主要用于encoder-decoder attention层
# get_attn_pad_mask主要是enc_inputs的pad mask矩阵(因为enc是处理K,V的,求Attention时是用v1,v2,..vm去加权的,
# 要把pad对应的v_i的相关系数设为0,这样注意力就不会关注pad向量)
# dec_inputs只是提供expand的size的
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # [batc_size, tgt_len, src_len]
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers:
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs, dec_self_attns, dec_enc_attns
十四、Transformer
Trasformer的整体结构,输入数据先通过Encoder,再同个Decoder,最后把输出进行多分类,分类数为英文字典长度,也就是判断每一个字的概率。
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.Encoder = Encoder().cuda()
self.Decoder = Decoder().cuda()
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False).cuda()
def forward(self, enc_inputs, dec_inputs): # enc_inputs: [batch_size, src_len]
# dec_inputs: [batch_size, tgt_len]
enc_outputs, enc_self_attns = self.Encoder(enc_inputs) # enc_outputs: [batch_size, src_len, d_model],
# enc_self_attns: [n_layers, batch_size, n_heads, src_len, src_len]
dec_outputs, dec_self_attns, dec_enc_attns = self.Decoder(
dec_inputs, enc_inputs, enc_outputs) # dec_outpus : [batch_size, tgt_len, d_model],
# dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len],
# dec_enc_attn : [n_layers, batch_size, tgt_len, src_len]
dec_logits = self.projection(dec_outputs) # dec_logits: [batch_size, tgt_len, tgt_vocab_size]
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
总结
通过手动实现Transformer的代码推导,对Transformer的结构有了更进一步的认识,学习到了Transformer架构中每一步的用处以及其是如何实现的,下周我将继续对GRU进行学习。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









