






前言
在MySQL中,深分页(deep pagination)指的是在结果集的末尾进行分页查询,例如查询第 1000 页的数据。这种操作通常会导致性能问题,因为 MySQL 必须扫描和跳过大量行数据来找到所需的
结果。
深分页问题
创建表
CREATE TABLE user (
id bigint(20) NOT NULL AUTO_INCREMENT,
name varchar(255) DEFAULT NULL,
phone varchar(255) DEFAULT NULL,
create_by varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
remark varchar(255) DEFAULT NULL,
birthday datetime DEFAULT NULL,
PRIMARY KEY (id),
INDEX idx_name (name)
) ENGINE=InnoDB AUTO_INCREMENT=400001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
添加数据
这里添加了500w条数据到数据库
@Test
public void test3(){
for(int j=0;j<500;j++){
List<UserEntity> userEntityList = new ArrayList<>();
for (int i = 0; i < 10000; i++) { //测试数据
UserEntity client = new UserEntity();
client.setName("小明" + String.format("%09d",j*100000+ i));
client.setPhone("18797" + String.format("%09d",j*100000+ i));
client.setCeateBy("JueYue"+String.format("%09d",j*100000+ i));
client.setRemark("测试" + String.format("%09d",j*100000+ i));
userEntityList.add(client);
}
userService.saveBatch(userEntityList);
System.out.println("插入"+(j+1)+"次");
}
}深分页语句
分别以10w,50w,100w,450w为起点查10条数据
SELECT * FROM user LIMIT 100000,10;
SELECT * FROM user LIMIT 500000,10;
SELECT * FROM user LIMIT 1000000,10;
SELECT * FROM user LIMIT 4500000,10;
可以看到 在偏移量相同的情况下,初始位置越大,耗时越久
优化方案
延迟关联
SELECT * FROM user LIMIT 100000,10;
SELECT user.*FROM user
JOIN (
SELECT id FROM user LIMIT 100000, 10
) AS subquery ON user.id = subquery.id;
SELECT * FROM user LIMIT 500000,10;
SELECT user.*FROM user
JOIN (
SELECT id FROM user LIMIT 500000, 10
) AS subquery ON user.id = subquery.id;
SELECT * FROM user LIMIT 1000000,10;
SELECT user.*FROM user
JOIN (
SELECT id FROM user LIMIT 1000000, 10
) AS subquery ON user.id = subquery.id;
SELECT * FROM user LIMIT 4500000,10;
SELECT user.*FROM user
JOIN (
SELECT id FROM user LIMIT 4500000, 10
) AS subquery ON user.id = subquery.id;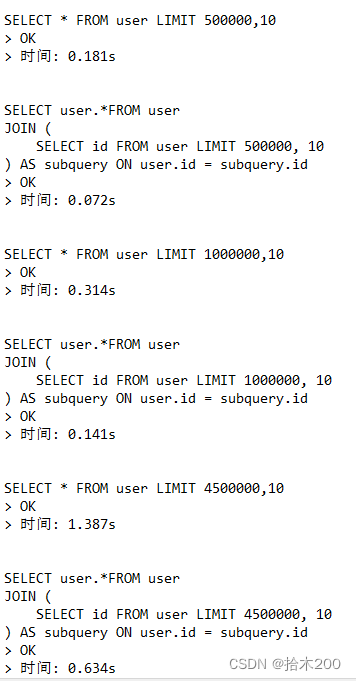
可以看到使用延迟关联的性能是要优于直接查询,这是因为当偏移量很大时(如4500000),MySQL必须扫描并跳过前4500000条记录,这会消耗大量的I/O和计算资源。而优化后的方法只会加载 id 列的值,又因为 id 是有索引的,它可以快速的帮我们定位到 id 对应列的全部数据,但是如果 id 列没有建立索引,那么他就会全表扫描,效率也是非常低的。
覆盖索引和主键优化
SELECT * FROM user LIMIT 4500000,10;
SELECT *
FROM user
WHERE id > (SELECT id FROM user ORDER BY id LIMIT 4500000, 1)
ORDER BY id
LIMIT 10;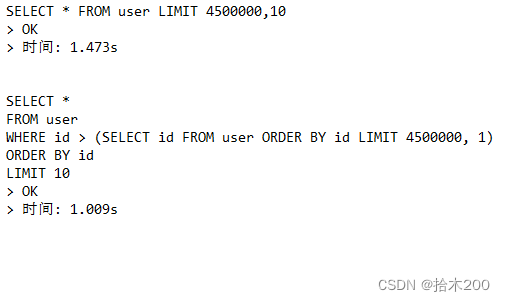
这里通过子查询先获取分页起点的 id 值,然后再进行主查询。这种方式有效减少了跳过的记录数。















 2401
2401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









