







 本文详细介绍了个人信用风险评估项目,包括数据读取、探索性分析、Baseline模型构建以及特征工程。通过使用Python的pandas、matplotlib、seaborn和sklearn等工具,对数据进行统计分析、可视化和模型训练。通过对贷款特征与违约率的关系进行深入研究,建立了逻辑回归和XGBoost模型,并进行了评估,展示了模型的性能和预测能力。
本文详细介绍了个人信用风险评估项目,包括数据读取、探索性分析、Baseline模型构建以及特征工程。通过使用Python的pandas、matplotlib、seaborn和sklearn等工具,对数据进行统计分析、可视化和模型训练。通过对贷款特征与违约率的关系进行深入研究,建立了逻辑回归和XGBoost模型,并进行了评估,展示了模型的性能和预测能力。
读取数据并了解基本情况
1.1数据集描述
本项目使用的数据集包含1000条个人数据,每条数据包含20个贷款相关信息字段以及1个违约类别字段,记录该笔贷款是否违约。 我们将使用该数据集构建个人信用风险评估模型来进行贷款违约预测。
1.2读取数据集
首先,我们需要读取数据。并查看数据的前5行信息。查看数据可以了解各个字段取值的具体情况,字段的名称等等,对数据有一个基础的了解。使用Pandas中的read_csv()函数可以读取csv文件,结果会保存为一个DataFrame或Series对象,调用使用DataFrame或Series对象的head()方法查看可以查看前n行数据,默认为5。
read_csv()函数部分常见参数详解:
filepath_or_buffer:文件所在处的路径(相对路径或绝对路径)
sep:指定分隔符,默认为逗号
header:指定行数用来作为列名,默认设置为0(即第一行作为列名)
index_col :指定哪列数据作为行索引,可以是一列,也可以多列
以路径C:\data\sample.csv为例:
绝对路径:文件在硬盘上真正存在的路径,如:C:\data\sample.csv
相对路径:相对于自己当前文件所处目录的位置,sample.cs
import pandas as pd
#读取数据
credit = pd.read_csv(filepath_or_buffer="credit.csv")
#查看前5行
credit_5 = credit.head(5)
print(credit_5)1.3查看数据基本情况
本节中,我们将查看数据集的基本信息,进一步了解数据的基本情况。DataFrame对象的info()方法用于打印DataFrame对象的摘要,包括列的数据类型dtype、名称以及有无缺失值,数据框的维度以及占用的内存等信息。
info()方法的参数:
verbose:是否显示所有列的信息,若为False,则会省略一部分
memory_usage:是否查看DataFrame的内存使用情况,默认为True
null_counts:是否统计NaN值的个数,默认为True
import pandas as pd
#查看数据的基本信息
credit_info = credit.info()1.4查看数据基本统计信息
本节中,我们将查看数据的基本统计信息。DataFrame对象的describe()方法可以查看各个列的基本统计信息,describe()方法将输出一个DataFrame对象,对于object类型的列,会输出样本数量count,不同取值个数unique,众数top以及众数的频数freq,对于int或float类型的列,会输出均值mean,方差std,最小值min,下四分位数25%,中位数50%,上四分位数75%,最大值max等信息。
describe()方法参数:
percentiles:结果返回的百分位数,默认值为[.25,.5,.75],即25%、50%和75%分位数,可以传入一个列表进行指定,如[.3,.5,.8]将返回30%、50%和80%分位数
include:返回的结果包含哪些列,默认只返回int或float类型的列的统计量;指定为‘all’,返回所有列的统计量,指定为‘O’,返回object类型的列的统计量
exclude:返回结果要排除哪些列,默认情况下, 不排除任何列
import pandas as pd
#查看数据基本统计信息
credit_desc = credit.describe(include='all')
print(credit_desc)二、探索性分析
2.1探索性分析
在前面的任务中,通过info(),describe()等方法展示了数据的基本信息。在本环节中,我们将通过Python中的绘图库如Matplotlib、Seaborn等,利用一系列可视化的手段,通过绘图的方式展示数据字段的取值分布以及数据字段间的相关关系。我们还将利用Sklearn中的SelectKBest方法,计算连续型和离散型特征与标签之间的相关性,对数据进行更深层次的分析。
2.2违约与未违约数量柱状图
本项目中,字段default表示是否违约,也是建模的目标,违约人数与未违约人数的分布比例对风控模型的构建至关重要。下面使用Seaborn中的countplot()函数绘制柱状图,展示违约与未违约人数的分布情况。
Seaborn中的countplot()函数主要参数如下:
x:在x轴方向指定绘图的字段,即绘制柱状图,不能与y同时使用
y:在y轴方向指定绘图的字段,即绘制条形图,不能与x同时使用
hue:按照指定的字段进行分组
data:传入DataFrame对象,用于绘图的数据框
color:设置颜色
palette:使用不同调色板
ax:指定子图索引
import matplotlib.pyplot as plt
import seaborn as sns
fig = plt.figure(figsize=(7,5))
#绘制柱状图,查看违约与未违约的取值分布情况
sns.countplot(x='default',data=credit,palette='Set3')
plt.xlabel('是否违约',fontsize=10)
plt.ylabel('数量',fontsize=10)
plt.title('违约与未违约数量柱状图',fontsize=13)
plt.box(False)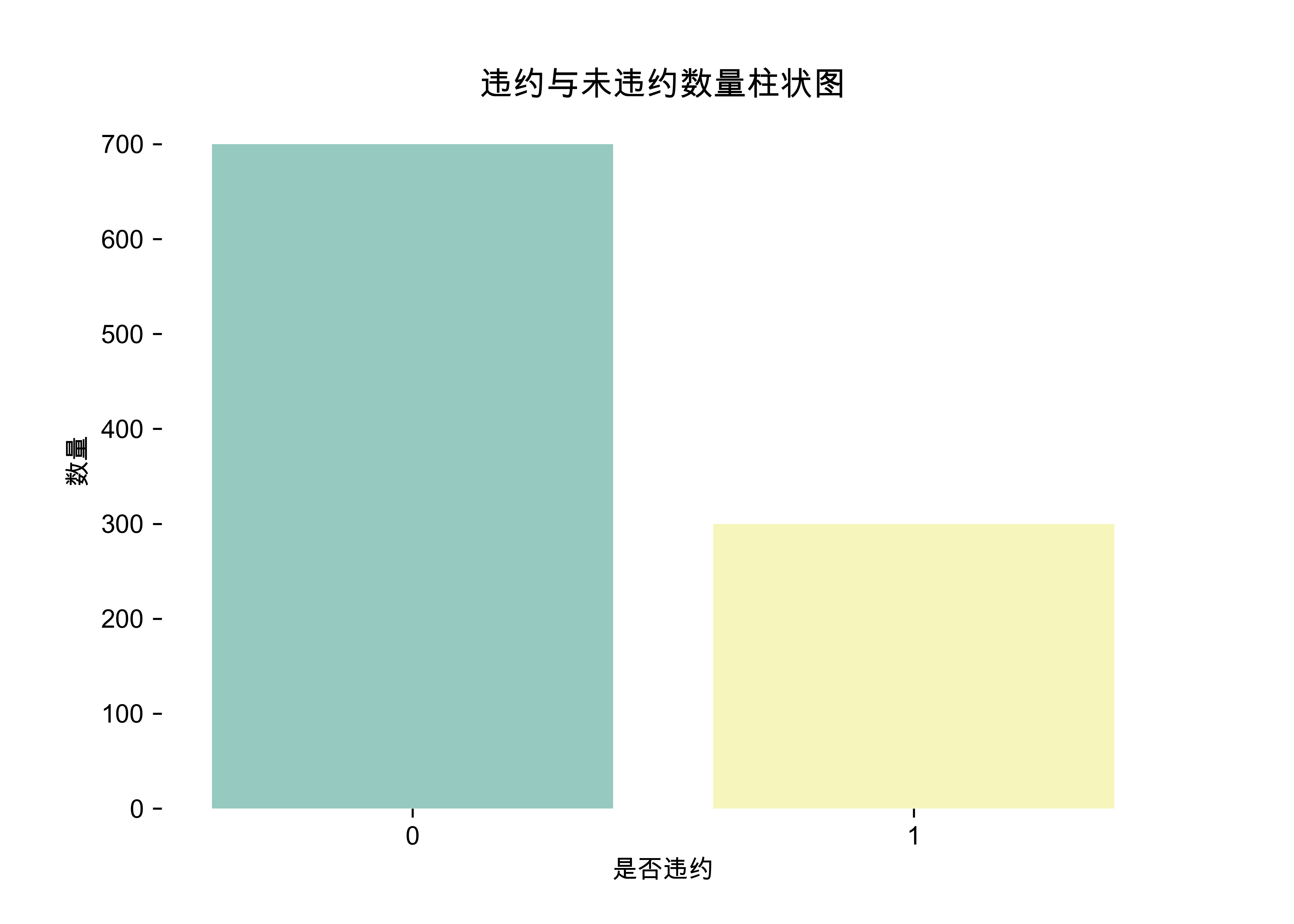
2.3贷款持续时间违约率条形图
本节中,我们分析贷款持续时间months_loan_duration与是否违约的关系。由于贷款持续时间的取值较多,因此我们将贷款持续时间进行等距离散化,计算离散化后各个组的违约率,绘制条形图进行展示。
Pandas中的cut()函数可以进行等距离散化,主要参数有:
x:需要离散化的数据对象,可以传入列表、一维NumPy数组或Series对象
bins:输入整数,表示将x划分为多少个等距的区间,输入序列,表示将x按照指定区间进行离散化,列表中的元素表示分点,若不在区间范围内的数据,则表示为Nan
right: 是否包含右分点
labels:是否用标签来代替返回的值
include_lowest:是否包含左分点
Seaborn的barplot()函数可以绘制条形图,主要参数有:
x:x轴数据,柱状图时为标签名称,条形图时为数值
y:y轴数据,柱状图时为数值,条形图时为标签名称
hue:按照指定的字段进行分组
data:传入DataFrame对象,用于绘图的数据框
color:设置颜色
palette:使用不同调色板
ax:指定子图索引
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
months = (0,6,12,18,24,30,36,42,48,54,72)
#对'months_loan_duration'进行离散化
months_cut = pd.cut(credit['months_loan_duration'],bins=months)
#groupby操作计算各个分组的违约率
months_rate = credit.groupby(months_cut).apply(lambda x: x['default'].sum()/x['default'].count())
#将各个分组的违约率绘制条形图进行展示
fig = plt.figure(figsize=(7,5))
sns.barplot(months_rate.values,months_rate.index,palette="Set2")
plt.xlabel('违约率',fontsize=10)
plt.ylabel('贷款持续时间',fontsize=10)
plt.title('贷款持续时间违约率条形图',fontsize=13)
plt.box(False)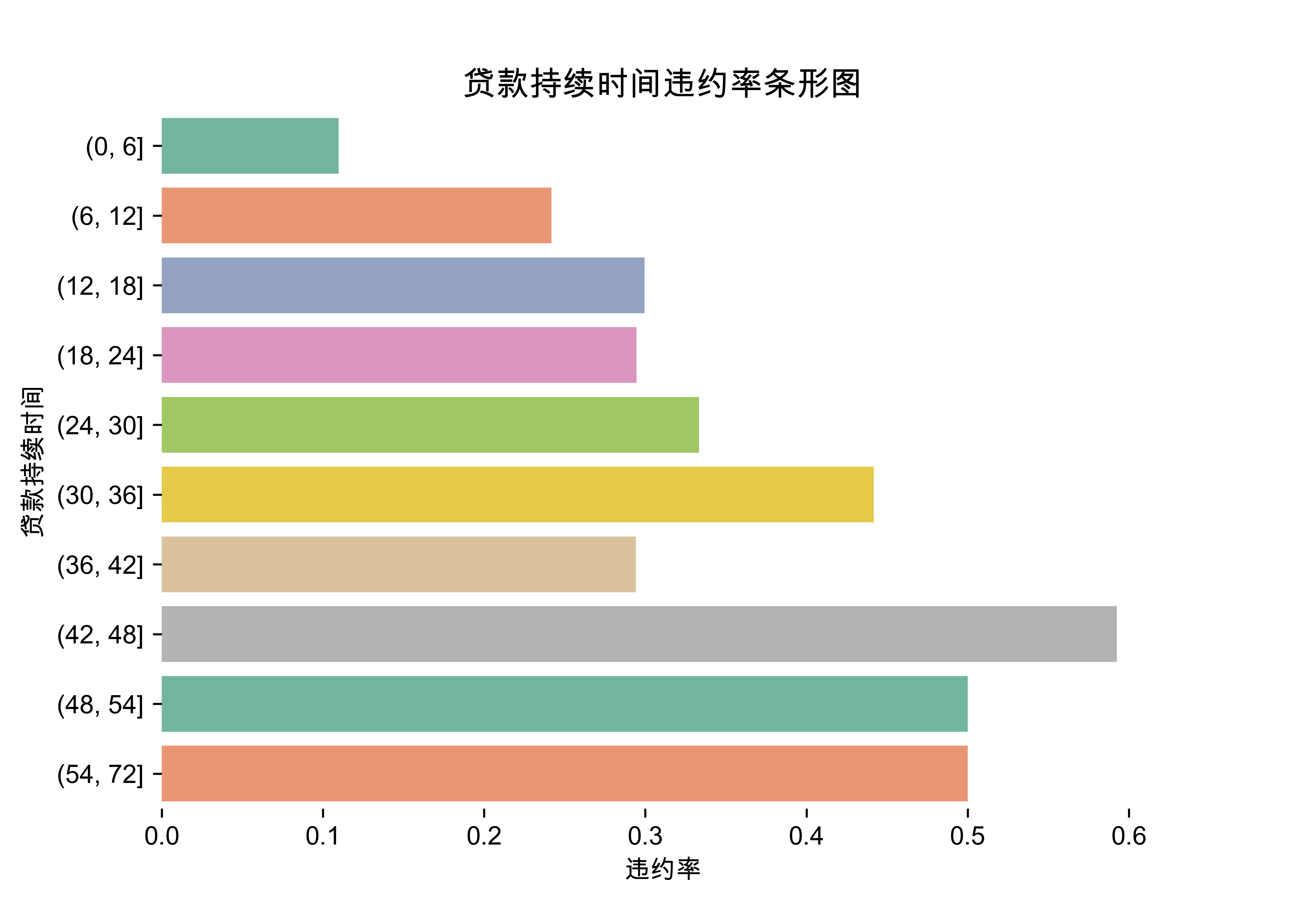
2.4违约与未违约贷款金额分布分组条形图
本节中,我们分析贷款金额amount与是否违约的关系。由于贷款金额的取值较多,因此我们将贷款金额进行等距离散化,统计离散化后各个组违约与未违约人数的分布,绘制条形图进行展示。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
interval = (0,2000, 4000, 6000,8000,10000,1200 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7064
7064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









