







原文链接:CVPR 2024 Open Access Repository
Pytorch开源代码:https://github.com/nathan66666/DVMSR.git
摘要
高效图像超分辨率(Efficient Image Super-Resolution, SR) 旨在通过最小化计算复杂度和网络参数量来加速SR网络推理,同时保持性能。现有基于卷积神经网络(CNN)的高效图像超分辨率方法已取得先进成果,但鲜有研究尝试利用Mamba的长程建模能力和高效计算特性(该特性在高层视觉任务中表现优异)。本文提出DVMSR——一种结合视觉Mamba(Vision Mamba)和蒸馏策略的新型轻量级图像SR网络。
DVMSR的网络结构包含三个模块:特征提取卷积层、多个堆叠的残差状态空间块(RSSB)和重建模块。其中,深度特征提取模块由若干RSSB组成,每个RSSB包含多个视觉Mamba模块(ViMM)和残差连接。为在保持性能的同时提升效率,我们采用蒸馏策略优化视觉Mamba网络:利用教师网络的丰富表征知识作为轻量级学生网络输出的额外监督。大量实验表明,DVMSR在模型参数量上优于当前最高效的SR方法,同时保持PSNR和SSIM性能。
关键词:图像超分辨率、视觉Mamba、残差状态空间块、模型蒸馏、轻量网络
总结
核心创新
- 提出DVMSR,首个将视觉Mamba(ViMM)引入图像超分辨率的轻量级网络,利用Mamba的长程依赖建模能力和低计算复杂度优势。
- 设计残差状态空间块(RSSB)作为主干模块,结合ViMM与残差连接,平衡性能与效率。
- 采用蒸馏策略,通过教师网络监督轻量学生网络,进一步提升性能。
优势
- 高效轻量:在减少参数量的情况下,保持甚至超越现有CNN-based高效SR方法的PSNR/SSIM指标。
- 开源代码:提供完整实现,便于复现和应用。
意义
- 为高效SR任务提供了新思路,证明Mamba结构在底层视觉任务(如超分)中的潜力。
- 蒸馏策略的引入为轻量模型性能优化提供了可行方案。
引言
🔍 1. 研究背景与意义
-
图像超分辨率(SR) 是图像处理中的一项基础任务,目标是将低分辨率图像重建为高分辨率图像。
-
随着深度学习的发展,越来越多的 CNN 架构被应用于 SR 任务中,显著提升了性能。
-
然而在实际应用中(如移动端、边缘设备),除了精度,还需关注模型的效率,包括:
-
推理时间
-
参数数量
-
计算量(FLOPS)
-
激活值大小
-
网络深度
-
-
因此,“高效超分辨率模型”成为当前研究热点。
🧩 2. 相关工作回顾
-
IMDN(2019):引入信息多重蒸馏模块(IMD Module),AIM 竞赛冠军。
-
RFDN(2020):基于残差学习优化 IMDN,提高重建效果。
-
RLFN(2022):精简蒸馏连接结构,进一步提升推理效率。
-
NTIRE 2022:高效 SR 赛道冠军方案结合知识蒸馏与剪枝,提升效率同时缩小模型规模。
✅ 这一系列模型为构建高效 SR 网络提供了宝贵思路,但都仍以 CNN 架构为主。
🧠 3. 引入 Mamba 模型的动机
-
Transformer 在 NLP 和高阶视觉任务中取得成功,具备全局建模能力,但在低级视觉中的应用仍有限。
-
Mamba 模型作为一种新的状态空间序列建模架构:
-
更高效(支持线性扩展)
-
能处理长序列建模任务
-
在多个尺度和数据集上超越 Transformer
-
-
本文尝试将 Mamba 引入 SR 任务,探索其在高效建模长距离依赖信息方面的潜力。
🧱 4. DVMSR 模型结构简介
-
基础架构:DVMSR 以视觉 Mamba 为核心构建。
-
模块组成:
-
RSSB(Residual State Space Block):残差状态空间模块,构建模型主干。
-
每个 RSSB 内部堆叠多个 ViMM(Visual Mamba Module)
-
-
ViMM 结构:
-
单向状态空间模型(SSM) → 长距离建模
-
残差连接 → 稳定训练
-
SiLU 激活函数 → 提升非线性表达能力
-
这些设计帮助 DVMSR 达到更大感受野、快速收敛、高建模效率。
🧪5. 知识蒸馏策略
-
引入教师-学生结构:
-
教师模型:参数较大的 Mamba 网络
-
学生模型:轻量 DVMSR
-
-
教师网络引导学生学习更有效的表示,以实现:
-
更高的重建精度
-
更小的模型体积
-
更快的推理速度
-
✅ 此策略特别适合高效 SR 任务中的轻量网络训练。
🎯6. 作者贡献总结
-
提出一种结合状态空间建模的轻量视觉 Mamba 架构,在 SR 任务中展现出良好建模能力与效率。
-
设计了与 Mamba 结构配套的特征蒸馏机制,提升网络训练效果。
-
在多个实验中验证了模型的有效性,在参数更少的情况下仍保持良好 PSNR 与 SSIM。
✍️7. 个人理解与思考
-
✅ 创新点突出:首次将视觉 Mamba 架构引入高效 SR 任务,结合 SSM 和残差设计是亮点。
-
✅ 应用前景广阔:特别适合边缘计算、移动设备等对推理速度和模型大小有要求的场景。
相关工作
✨ Part1:Lightweight Super Resolution(轻量级超分辨率)
🔎 原文讲了什么?
-
SRCNN(2014) 是第一个将深度学习引入单图像超分辨率(SISR)的工作,掀起了后续的研究热潮。
-
随着研究深入,出现了很多针对真实场景的改进方法:
-
GAN:用生成对抗网络提升图像质量和感知效果。
-
退化建模、多任务学习、系统评估:更好地适应真实图像退化情况和实际应用需求。
-
-
部署环境限制:移动端、边缘设备计算资源有限,因此模型必须小而强大。
-
为了提高效率,出现了一系列轻量化方法:
-
FSRCNN:用反卷积替代双线性插值,减少计算。
-
VDSR / DRCN / DRRN / LapSRN / MemNet:在模型结构上深度优化,引入残差、递归、金字塔、记忆机制等。
-
IMDN / RFDN / RLFN / DIPNet:聚焦信息蒸馏、结构简化、重参数化,在保持性能的同时进一步提高速度。
-
-
DIPNet 获得 2023 NTIRE 高效 SR 挑战赛冠军。
🧠 总结重点:
-
研究从早期追求“性能最优”转向“效率与性能并重”。
-
信息蒸馏、结构重用、递归设计等技术为轻量级 SR 奠定了基础。
-
本文提出的 DVMSR 就是站在这些“轻量高效”方法基础上的进一步创新,探索了非 CNN 架构(即 Mamba)+ 蒸馏的融合设计。
✨ Part 2:State Space Models in Vision(视觉任务中的状态空间模型)
🔎 原文讲了什么?
-
状态空间模型(SSM)的经典代表是卡尔曼滤波器,用于动态系统中的状态估计。
-
新一代 SSM —— Mamba(曼巴)架构:
-
能高效建模长距离依赖
-
计算上具有线性扩展性(比 Transformer 更省资源)
-
-
Mamba 本来应用于 NLP,现在已逐渐扩展到视觉任务:
-
视频理解:建模时间维度上的长依赖
-
图像分类、生物医学分割、遥感图像、多模态学习等
-
-
有研究提出将 Mamba 用于低级视觉任务(如图像修复),取得不错效果。
-
本文在这些探索的基础上,首次提出将 Mamba 应用于图像超分辨率任务,并结合知识蒸馏,取得“精度+效率”的双赢效果。
🧠 总结重点:
-
Mamba 是 Transformer 的高效替代者,具备建模长依赖关系的优势。
-
本文是首批尝试将 Mamba 应用于高效超分辨率的工作之一,结合知识蒸馏以提升轻量模型表现。
✨ Part 3:Feature Distillation(特征蒸馏)
🔎 原文讲了什么?
-
知识蒸馏(Knowledge Distillation,KD):小模型在大模型(教师)引导下学习特征,是一种有效的压缩方法。
-
蒸馏方式不要求师生结构一致,可广泛适用于不同网络架构。
-
蒸馏技术从最初的Softmax 蒸馏发展到:
-
中间层蒸馏:利用卷积层输出、倒数第二层等中间特征,保留更多语义细节。
-
-
蒸馏在 SR 任务中的应用日益广泛,并被证实可以提升小模型的性能。
-
本文采用 教师网络输出的特征图 作为蒸馏目标,对学生模型进行训练。
🧠 总结重点:
-
蒸馏方法为提升轻量模型性能提供了有效手段;
-
本文通过蒸馏策略,使 DVMSR 能在模型小的同时保证超分效果优良;
-
不需要结构对齐,适配性强,适合 Mamba 这种新架构。
📌 整体小结
🔍 相关工作总结
1️⃣ 轻量级超分辨率
传统超分网络虽精度高但计算开销大,难以部署于移动或边缘设备。为解决这一问题,研究者们发展了如 FSRCNN、IMDN、RFDN 等系列轻量网络,结合结构重用、残差连接、信息蒸馏等手段,有效减少模型参数与计算量。2023 年 NTIRE 高效 SR 竞赛冠军 DIPNet 进一步证明轻量网络的重要性。
2️⃣ 状态空间模型(Mamba)在视觉任务中的应用
Mamba 架构以其高效的长距离依赖建模能力,在 NLP 中表现出色,并逐步拓展至视频分类、图像分类等视觉任务中。近期研究表明其在低级视觉任务(如图像修复)中也具有潜力。本文首次尝试将 Mamba 引入图像超分辨率领域,提出以 ViMM 模块为核心的 DVMSR 架构。
3️⃣ 知识蒸馏在超分任务中的应用
为了进一步提升轻量模型的性能,本文引入了知识蒸馏策略。通过使用预训练教师模型的中间特征图作为监督信号,DVMSR 在推理速度快、参数少的前提下,也能获得较高的超分重建质量。
方法
Motivation
1. 核心问题
现有方法的局限性:
- CNN方法(如IMDN/RFDN):依赖局部卷积,难以建模远距离像素依赖,限制重建质量。
- Transformer方法:虽能捕获全局上下文,但计算复杂度高(如自注意力机制),不适合轻量级SR场景。
2. Mamba的潜力
理论优势:
- 长距离建模:通过状态空间模型(SSM)实现线性复杂度的全局依赖捕获。
- 高效计算:序列长度增加时计算量仅线性增长(Transformer为二次增长)。
未解问题:Mamba在底层视觉(如SR)中的有效性尚未验证。
3. 动机验证工具
局部注意力映射(LAM):
功能:量化输入像素对重建结果的贡献程度(图2中红色标记为关键像素)。
关键发现:
- DVMSR的扩散指数(DI)显著高于CNN/Transformer,证明其能利用更广范围的像素信息。
- 可视化显示Mamba重建的细节更清晰(如边缘和纹理)。
4. 方法目标
- 核心创新:将Mamba的长程建模+高效计算特性引入高效SR任务。
- 对比优势:参数量/计算量接近轻量CNN,性能逼近Transformer。通过LAM实验验证其长距离依赖建模能力。
5. 研究意义
- 新方向:首次系统性探索Mamba在SR任务中的适用性。
- 实用价值:为轻量级SR模型提供「全局感知+低计算」的新方案。
Preliminaries
Mamba 利用状态空间模型(SSM)来实现对长序列(如图像行、视频帧)的高效建模,并通过将连续系统离散化,获得能在深度学习中训练的可微结构。
1. 状态空间模型基本定义(连续形式)
SSM 的定义形式如下:
h′(t) = A h(t) + B x(t) (隐藏状态的微分方程)
y(t) = C h(t) (输出是隐藏状态的线性变换)
解释:
-
这是一个连续时间系统(continuous-time system),以输入序列 x(t)驱动隐藏状态 h(t),进而输出 y(t)。
-
这个思想来自控制论中常见的模型,比如卡尔曼滤波、物理系统建模等。
其中:
:隐藏状态向量
:状态转移矩阵
:输入到状态的权重
:状态到输出的映射
2. 离散化:从连续系统变成神经网络可训练结构
离散化公式:
Ā = exp(ΔA)
B̄ = (ΔA)⁻¹ (exp(ΔA) − I) ⋅ ΔB
解释:
-
为了在神经网络中使用,我们需将微分形式转化为“步进”的离散形式(也就是从
)
-
ZOH(Zero-Order Hold)是一种常见的离散化方法,它近似连续时间信号在每一小段时间内保持常值。
3. 离散状态空间模型(适用于深度学习)
离散后得到的更新公式:
解释:
-
这就是我们在模型中迭代计算的方式。每个时刻的状态由前一个状态和当前输入共同决定,输出则是当前状态的映射。
-
可以看作是一个结构化的、线性递归神经网络(Linear RNN)。
4.在 Mamba 模型中的意义
-
Mamba 用这种结构代替了传统的 Self-Attention(如 Transformer)或 CNN,来实现长依赖建模。
-
优势是线性计算复杂度(O(n)),比 Attention 的 O(n²) 高效得多。
-
而且是可微的模块,可以嵌入到图像/视频/多模态任务中。
小结
-
状态空间模型(SSM)源自控制系统,用一组线性方程建模输入、状态与输出的关系,适用于处理长序列。
-
Mamba 模型通过 ZOH 将连续系统离散化,得到可用于深度学习训练的递推公式。
-
相比于 Transformer,Mamba 在序列建模中具有线性复杂度与更强的长依赖建模能力,并已扩展到视觉、语言等多模态任务。
Overall network architecture
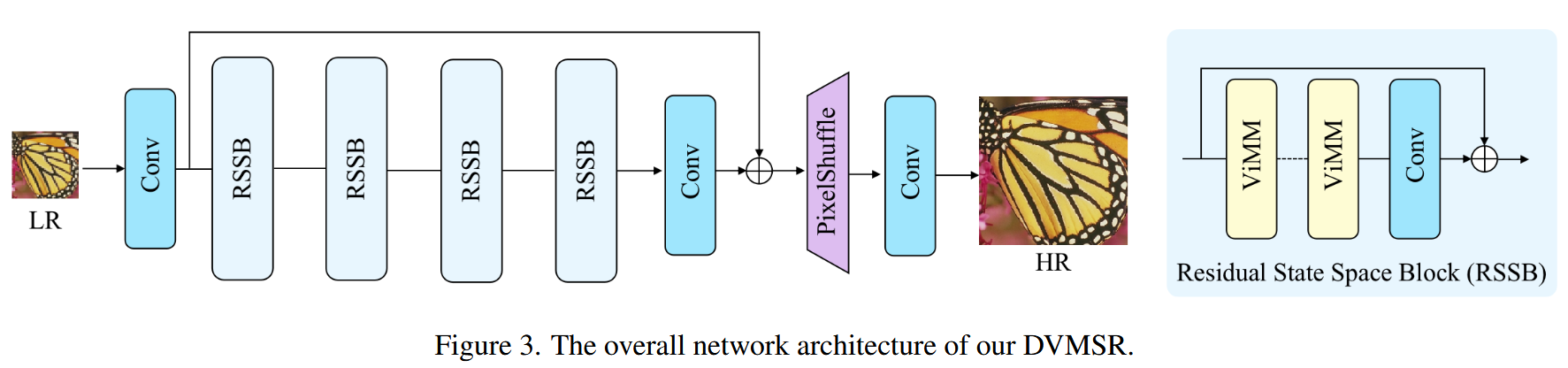
DVMSR 网络的整体架构如图3所示。DVMSR 主要由三个模块构成:特征提取卷积层、多个堆叠的残差状态空间模块(RSSB),以及一个重建模块。
- 输入是一个尺寸为 H×W,通道数为 Cin的低分辨率图像;使用一个卷积层提取浅层特征,得到 F0,用于后续的残差连接。
- 利用一系列的 RSSB 模块和一个 3×3 卷积层 HConv(⋅)来进行深度特征提取。接着,我们通过一个全局残差连接将浅层特征 F0F_0F0 与深层特征 FD融合,
- 最后通过重建模块恢复高分辨率图像。在重建模块中,使用 pixel-shuffle 方法对融合特征进行上采样,生成最终的高清图像。
如图3所示,每个 RSSB 包含两个 Vision Mamba 模块(ViMM)和一个带有残差连接的 3×3 卷积层。
-
ViMM 是基于 Mamba 架构的视觉模块;
-
每个 RSSB 内部包含两个 ViMM,加一个卷积层,并通过残差连接将输入与输出相加;
-
这种结构可以增强时序建模能力,适用于视觉任务中的长距离依赖建模。
Mamba network
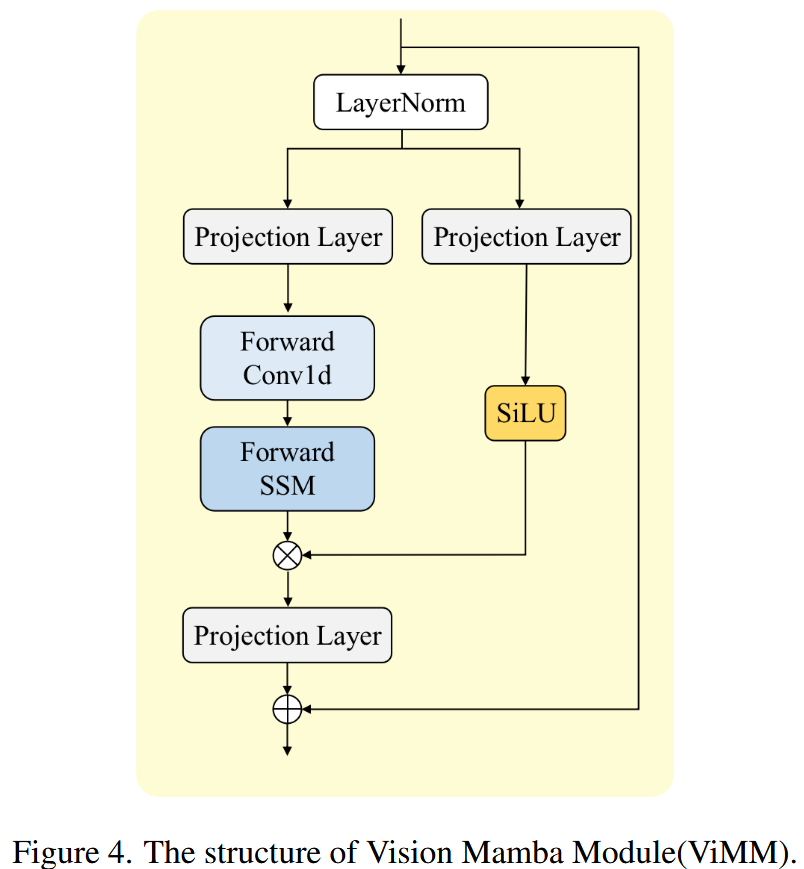
🧠 ViMM(Vision Mamba Module)模块介绍:
Mamba 网络的结构如图4所示,即视觉 Mamba 模块(ViMM),采用单向序列建模方式。
-
ViMM 是把 Mamba 引入视觉任务的一个模块,核心思想是用 状态空间模型(SSM) 进行序列建模,模拟长距离依赖。
-
在视觉任务中,输入的图像特征 X 被展开为类似 token 的序列,然后按“时序”的方式进行建模(虽然本质是空间上的序列)。
🪄 步骤 1:输入归一化
输入序列
首先经过 Layer Normalization(LN)层进行归一化。
-
图像的每个像素点的通道向量会进行归一化,增强训练稳定性;
-
通常 LN 是对最后一个维度(即通道维)做归一化处理。
🔁 步骤 2:线性映射 + 升维
然后对归一化后的序列做线性变换,将通道数从 C扩展为 λC。
-
这是为了给后续的状态建模提供更多特征空间;
-
λ是一个扩展因子,通常是 2 或 4,表示升维比例。
🧱 步骤 3:使用 1D 卷积 + SSM 模型计算
接着,将线性变换后的特征送入 1D 卷积层,再进入状态空间模块(SSM),得到中间结果
-
卷积是为了引入局部建模;
-
SSM 模块可以看作是一个轻量的序列处理器(类似 Transformer 但更高效),擅长捕捉长距离依赖。
✨ 步骤 4:门控机制计算 
并行地,再用另一条分支将归一化后的输入做线性映射 + SiLU 激活函数,得到门控向量
-
这是用于对
-
SiLU 是一种光滑的激活函数,形式是
,它比 ReLU 更柔和,适合表达细粒度变化。
🔗 步骤 5:融合与残差连接
最后将
-
⊙ 是 Hadamard 乘积,表示逐元素相乘;
-
再通过线性变换映射回原通道维度 C,并加上原始输入 X,形成残差连接,保留输入信息。
🧩 总结一下结构流程:
输入 X ∈ [H, W, C]
│
LayerNorm(归一化)
├──→ Linear → Conv1d → SSM ────→ X1
└──→ Linear → SiLU → X2
↓
X1 ⊙ X2 → Linear → +X(残差)→ Xout
🧠 模块优势:
-
ViMM 使用 轻量级状态空间建模(SSM) 替代了传统的自注意力;
-
通过 双分支门控机制 增强了表达能力;
-
模块计算效率高,适合部署在资源受限设备上(比如轻量超分模型中);
-
带有 残差结构,帮助梯度更好传播。
门控机制(Gating Mechanism)?
门控机制是一种通过“控制信号”来调节信息流动的机制。最经典的例子就是 RNN 里的 LSTM/GRU——里面的“遗忘门”、“输入门”就是用来控制“保留多少、忘掉多少”。
在深度学习中,门控机制一般形式如下:
Output = Gate ⊙ Value
-
Gate:一个控制信号(通常经过激活函数,如 Sigmoid/SiLU)
-
Value:要处理的主分支特征
-
⊙:表示 Hadamard 乘积(逐元素相乘)
这个乘法操作可以理解为“打个权重”,让某些信息通过、某些信息被抑制。
那什么是“双分支门控”?
双分支门控机制(Two-Branch Gating Mechanism)指的是:
将输入特征 X 分成两条计算路径(分支),分别生成:
一个是信息分支:提取主要特征(在 ViMM 中是经过 Conv1d 和 SSM 的
一个是门控分支:计算一个“控制信号”或“门值”(ViMM 中是
最后两者做元素级乘积:
这就像是给特征加了一个“调音器”:
只有那些“门”值高的通道,才会让特征顺利通过;门值低的,就会被抑制。
📌 为什么要这样设计?
-
信息选择性增强
不同的通道、空间位置的重要性是不一样的。门控机制能帮模型“学会关注重点”。 -
模型更具表达能力
比单一路径强,尤其在轻量模型中,可以用很少的参数实现灵活的特征调整。 -
与残差结合,梯度更稳定
输出还加了原始输入残差,让训练更稳定,信息保留更充分。
🖼️ 用一句话总结结构(类比):
“一个人(模型)做决定之前(输出结果),左脑(主分支)分析问题,右脑(门控分支)判断是否采纳,然后再决定说出口(最终输出)。”
🚀 小结:
| 项目 | 内容 |
|---|---|
| 机制名称 | 双分支门控机制 |
| 主要构成 | 主分支(信息提取)+ 门控分支(控制信号) |
| 关键操作 | 元素级乘法(Hadamard Product) |
| 作用 | 控制特征流通,提升表达能力,增加非线性 |
🧠 门控机制 vs 注意力机制
| 项目 | 门控机制(Gating) | 注意力机制(Attention) |
|---|---|---|
| 目标 | 控制信息流通,突出重点 | 赋予不同位置/通道不同权重 |
| 核心操作 | 元素级乘法:Gate ⊙ Value | 权重加权求和:Σ (Weight ⊗ Value) |
| 门/权重来源 | 通过一条分支动态生成 Gate | 通过 Query/Key/Value 计算 Attention Score |
| 作用方式 | 控制某一位置/通道“放大或抑制” | 控制某一位置对其他位置的关注度 |
| 本质 | 局部注意力(不显式建图) | 显式建图的全局注意力 |
-
注意力机制:通常是全局加权,比如 Transformer 是每个 token 对所有 token 建图,计算注意力分数;
-
门控机制:更像是局部权重控制,用轻量级结构(比如 Linear + 激活)学习每个位置/通道的权重,计算代价低,非常适合用在轻量模型或边缘设备上(比如 DVMSR 这种超分模型)。
📌 类比一个生活场景:
| 模型结构 | 类比说明 |
|---|---|
| 注意力机制 | 像在会议上,每个人都听所有人发言,然后决定重点关注谁(全局互动) |
| 门控机制 | 像给每个员工发一个“工作许可”按钮(控制当前人是否继续做事) |
Distillation strategy
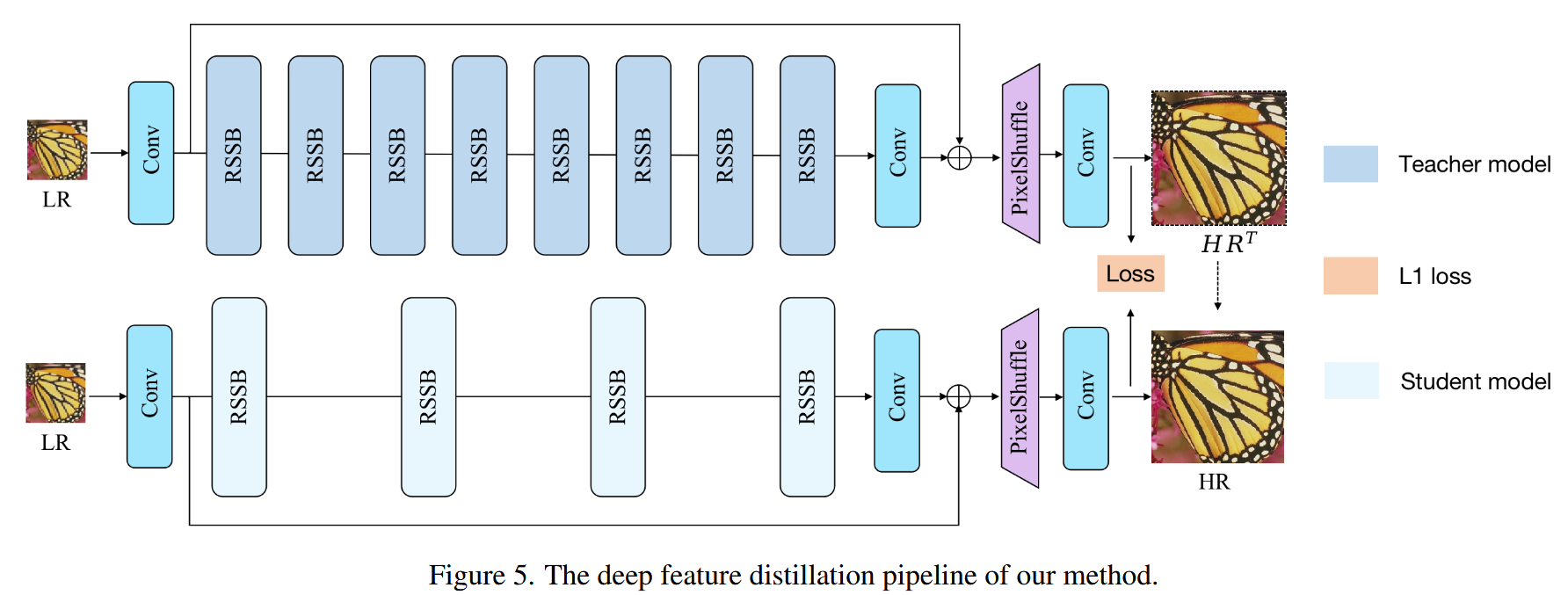
🌟 什么是蒸馏(Distillation)?
在深度学习中,知识蒸馏(Knowledge Distillation)的本质是:
用一个性能更强的大模型(教师)去“指导”一个更小或更轻量的模型(学生),让它也学会类似的表示和能力。
这样可以:
-
保证轻量模型精度不掉太多
-
提升小模型的泛化能力
📚 DVMSR 中的蒸馏结构(来自 Fig. 5)
论文中提到,他们引入了一个叫 Deep Feature Distillation Strategy 的方法,主要包括几个关键部分:
🧠 教师网络(Teacher Network):T(·)
-
它是一个大模型/强模型
-
在蒸馏时保持 固定不变(不更新参数)
-
对输入图像提取出深层次特征,作为学生学习的“目标”
🧒 学生网络(Student Network):S(·)
-
就是我们正在训练的 DVMSR 模型
-
它不仅要学会还原高分辨率图像,还要学会模仿教师的中间特征
✍️ 损失函数解析(Loss Function)
他们的总损失函数是:
其中各部分是:
| 名称 | 表达式 | 含义 |
|---|---|---|
| Ldis(蒸馏损失) | 教师和学生的特征差距,鼓励学生“学得像老师” | |
| L1(重建损失) | 学生输出图像与真实高分图像的差异 | |
| λdis, λ1 | 都设为 1 | 控制两种损失的权重(论文里默认相等) |
也就是说,学生模型既要:
-
还原图像好(L1)
-
特征学得像老师(Ldis)
这是一个双目标学习,强化模型学习深层表示能力。
🎯 为什么这样设计?
因为对于图像超分任务来说,仅仅看输出图像和 GT 的 L1 差距还不够,如果学生模型的中间特征表达能力不足,就算图像看起来差不多,可能细节信息不对
- 加入教师指导的中间特征对齐,可以让学生更好地学到细节结构、纹理等高阶语义信息。
总结
DVMSR 的蒸馏策略通过引入教师模型的中间特征作为引导,让学生模型在还原高分图像的同时,学到更深更丰富的图像表达,提升了性能和泛化能力。
实验
数据集和指标
在本文中,使用具有 3450 张图像的 DF2K (DIV2K + Flickr2K) [48] 从头开始训练所提出的模型。在测试过程中,我们选择了五个标准基准数据集:Set5 [3]、Set14 [58]、BSD100 [41]、Urban100 [16] 和 Manga109 [42]。低分辨率图像是通过 MATLAB 中的“双立方”下采样从真实图像生成的。通过丢弃图像周围的 4 像素边界来测量的 PSNR/SSIM,并在 Y 通道上计算的 PSNR/SSIM 报告为定量指标。
实现细节
在训练过程中,我们将输入patch size: 256 × 256,并使用随机旋转和水平翻转进行数据增强。批处理大小设置为 128,迭代总数为 500k。初始学习率设置为 2 × 10−4。我们采用多步骤学习率策略,当迭代分别达到 250000、400000、450000 和 475000 时,学习率将减半。使用 β1 = 0.9 和 β2 = 0.99 的 Adam 优化器来训练模型。
Distillation training.在教师学习阶段,我们利用 2K 分辨率的 DF2K 数据集来训练教师网络,该网络包括 8 个 RSSB 和 2 个 ViMM 模块,具有 192 个通道。在蒸馏训练阶段,我们将 DF2K 数据集用于学生网络,其中包含 4 个 RSSB 和 2 个 ViMM 块,具有 60 个通道。
模型 SwinIR & DVMSR
我们的调查重点是 Mamba 在超分辨率 (SR) 任务中的表现。在图 2 中,我们展示了使用 LAM 的 DVMSR 出色的远程建模能力。此外,我们还在模型复杂性方面将 DVMSR 与基于 transformer 的模型 SwinIR 进行了比较。SwinIR 在 PSNR 方面的性能比 DVMSR 高出 0.23 dB,但代价是参数数量大约是 DVMSR 的两倍,FLOPS 明显更高,推理时间长约 20 倍。这些发现表明,基于 Mamba 的模型有望实现高效的 SR。
1.性能对比
- 精度(PSNR):SwinIR(29.20 dB)略优于DVMSR(28.97 dB)
- 速度(Time):DVMSR(0.048s)比SwinIR(0.865s)快约18倍
2.复杂度指标
- 参数量:DVMSR(0.42M)仅为SwinIR(0.93M)的45.6%,显示更紧凑的模型设计。
- 计算量(FLOPs):DVMSR(20.17G)减少71.5%,得益于状态空间模型(SSM)的线性复杂度特性。
- 内存占用:DVMSR(1094MB)降低24.8%,更适合资源受限场景。
3.关键发现
- 效率-精度权衡:DVMSR以微小PSNR损失换取显著加速,适合实时超分辨率任务。
- 激活值相同(26.7387):表明两者特征图尺寸设计一致,差异主要源于计算方式(ViMM vs. Transformer)。
总结
我们提出了轻量级超分网络 DVMSR,结合 Vision Mamba 模块与蒸馏策略。网络由特征提取、多个残差状态空间块(RSSB)和重建模块构成,具备建模远程依赖的能力。通过引入教师模型监督,有效提升了学生模型性能。尽管本工作展示了 Mamba 在图像超分中的潜力,但仍有待进一步深入探索。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









