







原文链接:Learning a Deep Convolutional Network for Image Super-Resolution | SpringerLink
pytorch开源代码:https://github.com/fuyongXu/SRCNN_Pytorch_1.0
一、摘要
我们提出了一种用于单图像超分辨率(SR)的深度学习方法。我们的方法直接学习低分辨率图像与高分辨率图像之间的端到端映射关系。该映射关系由一个深度卷积神经网络(CNN)表示,它以低分辨率图像作为输入,并输出高分辨率图像。我们进一步指出,传统的基于稀疏编码的超分辨率方法也可以被视为一种深度卷积网络。然而,与传统方法分别处理每个组件不同,我们的方法联合优化所有层。我们的深度CNN具有轻量级结构,但展现了最先进的恢复质量,并且实现了快速的速度,适用于实际的在线使用。
二、贡献
总体而言,本研究的主要贡献体现在三个方面:
- 我们提出了用于图像超分辨率的卷积神经网络。该网络直接学习低分辨率图像与高分辨率图像之间的端到端映射关系,除了优化过程之外,几乎无需额外的预处理或后处理步骤。
- 我们建立了基于深度学习的超分辨率方法与传统基于稀疏编码的超分辨率方法之间的联系。这种联系为网络结构的设计提供了指导。
- 我们证明了深度学习在经典的计算机视觉问题——超分辨率中是有效的,并且能够实现高质量和快速处理。
三、SRCNN整体流程
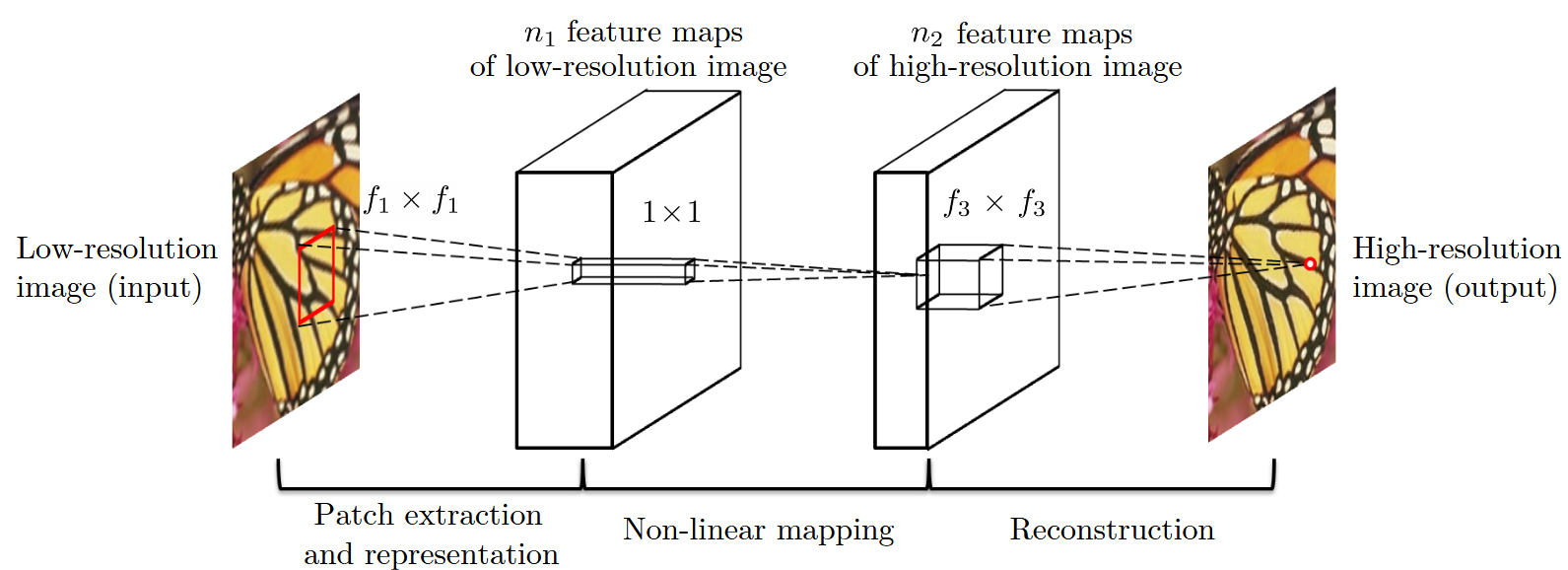
给定一个低分辨率图像 ( Y ),SRCNN 的第一层卷积层提取出一组特征图。第二层将这些特征图非线性地映射到高分辨率图像块的表示中。最后一层将空间邻域内的预测结果进行组合,从而生成最终的高分辨率图像 ( F(Y) )。
1.数据预处理(Prepare)
目的:图像预处理:生成LR-HR训练/评估数据集
整体流程
(以 scale=2 为例)假设我们有一张 高分辨率 HR 图像:256×256,处理过程是这样的:
步骤1:裁剪HR图像,使其能被scale整除:
hr_width = (hr.width // args.scale) * args.scale
hr_height = (hr.height // args.scale) * args.scale
hr = hr.resize((hr_width, hr_height), resample=pil_image.BICUBIC)
步骤2:下采样(模拟生成LR图):
lr = hr.resize((hr_width // args.scale, hr_height // args.scale), resample=pil_image.BICUBIC)
这里是关键一步:
-
将 HR 图像缩小 scale 倍(例如从256×256 -> 128×128);
-
使用双三次插值模拟摄像头采集或图像压缩后产生的“低分辨率图像”。
步骤3:再上采样(生成网络输入图):
lr = lr.resize((lr.width * args.scale, lr.height * args.scale), resample=pil_image.BICUBIC)
又是双三次插值!这次是:
-
把低分辨率图像放大回原始尺寸(128×128 -> 256×256);
-
模拟“简单插值放大的模糊图”;
-
这个就是模型的输入!它很模糊,要让模型学着变清晰。
So , 双三次插值到底是干嘛的?
| 场景 | 用在哪里? | 作用 | 图像是否放大? |
|---|---|---|---|
| 第一次 | 裁剪后 resize 到新 HR 尺寸 | 只是对齐尺寸,不是重点 | 通常 无变化 |
| 第二次 | HR -> LR 缩小图像 | 模拟真实低分辨率图像 | 缩小 |
| 第三次 | LR -> 模糊图 | 插值放大模糊图,供模型学习修复 | 放大 |
为什么不直接用原图训练,而要“缩小再放大”?
SRCNN是做图像超分辨的,它希望输入是放大的模糊图像,输出是清晰图像。 所以要手动制造“模糊输入”,模拟真实应用场景!
总结
用HR图生成LR图(缩小),再用双三次插值放大回来(模糊),这个模糊图就是输入,HR图就是标签,SRCNN就是学着去除插值造成的模糊失真!
datasets代码详细讲解
import argparse
import glob
import h5py
import numpy as np
import PIL.Image as pil_image
from utils import convert_rgb_to_y # 将RGB图像转换为Y通道(亮度)
# ---------- 函数:生成训练数据 ----------
def train(args):
# 创建HDF5文件用于存储训练样本
h5_file = h5py.File(args.output_path, 'w')
# 存放低分辨率和高分辨率图像块的列表
lr_patches = []
hr_patches = []
# 遍历图像目录下的所有图像路径
for image_path in sorted(glob.glob('{}/*'.format(args.images_dir))):
# 打开图像并转换为RGB格式
hr = pil_image.open(image_path).convert('RGB')
# 裁剪图像,使其尺寸能被scale整除
hr_width = (hr.width // args.scale) * args.scale
hr_height = (hr.height // args.scale) * args.scale
# 使用双三次插值将HR图像缩放到裁剪后的尺寸(初步对齐)
hr = hr.resize((hr_width, hr_height), resample=pil_image.BICUBIC)
# 缩小HR图像,模拟低分辨率图像(LR)
lr = hr.resize((hr_width // args.scale, hr_height // args.scale), resample=pil_image.BICUBIC)
# 再将LR图像通过双三次插值放大回原来的HR尺寸
# 这一步是SRCNN的关键输入处理
lr = lr.resize((lr.width * args.scale, lr.height * args.scale), resample=pil_image.BICUBIC)
# 转换为浮点型NumPy数组
hr = np.array(hr).astype(np.float32)
lr = np.array(lr).astype(np.float32)
# 只保留Y通道(亮度),符合SRCNN论文做法
hr = convert_rgb_to_y(hr)
lr = convert_rgb_to_y(lr)
# 对LR-HR图像进行裁剪,生成小块patches用于训练
for i in range(0, lr.shape[0] - args.patch_size + 1, args.stride):
for j in range(0, lr.shape[1] - args.patch_size + 1, args.stride):
lr_patch = lr[i:i + args.patch_size, j:j + args.patch_size]
hr_patch = hr[i:i + args.patch_size, j:j + args.patch_size]
lr_patches.append(lr_patch)
hr_patches.append(hr_patch)
# 转换为NumPy数组
lr_patches = np.array(lr_patches)
hr_patches = np.array(hr_patches)
# 保存数据到HDF5文件中
h5_file.create_dataset('lr', data=lr_patches)
h5_file.create_dataset('hr', data=hr_patches)
h5_file.close()
# ---------- 函数:生成评估数据 ----------
def eval(args):
# 创建HDF5文件用于存储验证图像
h5_file = h5py.File(args.output_path, 'w')
# 创建分组(group),每张图像一个键值
lr_group = h5_file.create_group('lr')
hr_group = h5_file.create_group('hr')
# 遍历图像路径
for i, image_path in enumerate(sorted(glob.glob('{}/*'.format(args.images_dir)))):
# 打开并转换为RGB图像
hr = pil_image.open(image_path).convert('RGB')
# 裁剪为可整除尺寸
hr_width = (hr.width // args.scale) * args.scale
hr_height = (hr.height // args.scale) * args.scale
hr = hr.resize((hr_width, hr_height), resample=pil_image.BICUBIC)
# 生成LR图像(缩小 + 放大)
lr = hr.resize((hr_width // args.scale, hr_height // args.scale), resample=pil_image.BICUBIC)
lr = lr.resize((lr.width * args.scale, lr.height * args.scale), resample=pil_image.BICUBIC)
# 转成float数组
hr = np.array(hr).astype(np.float32)
lr = np.array(lr).astype(np.float32)
# 转换为Y通道
hr = convert_rgb_to_y(hr)
lr = convert_rgb_to_y(lr)
# 以字符串索引保存每一张图像
lr_group.create_dataset(str(i), data=lr)
hr_group.create_dataset(str(i), data=hr)
h5_file.close()
# ---------- 脚本入口 ----------
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# 输入图像所在目录
parser.add_argument('--images-dir', type=str, required=True)
# 输出HDF5文件路径
parser.add_argument('--output-path', type=str, required=True)
# patch尺寸(默认33×33)
parser.add_argument('--patch-size', type=int, default=33)
# 裁剪滑动窗口步长
parser.add_argument('--stride', type=int, default=14)
# 上采样放大倍率(如2倍、3倍、4倍)
parser.add_argument('--scale', type=int, default=2)
# 是否是评估模式(默认为训练)
parser.add_argument('--eval', action='store_true')
args = parser.parse_args()
# 根据参数决定执行哪部分
if not args.eval:
train(args)
else:
eval(args)
2.SRCNN网络结构
| 层次 | 作用 | 特征图通道变化 | 卷积核大小 |
|---|---|---|---|
| conv1 + ReLU | 特征提取 | num_channels → 64 | 9×9 |
| conv2 + ReLU | 非线性映射 | 64 → 32 | 5×5 |
| conv3 | 图像重建 | 32 → num_channels | 5×5 |
如下所示的model.py 是一个 完整的超分模型结构: 提取 → 映射 → 重建 一整套流程。
⚠️注意:输入图片是先经过双线性插值上采样到目标尺寸,再输入网络的!
from torch import nn
# 定义SRCNN模型,继承自nn.Module
class SRCNN(nn.Module):
def __init__(self, num_channels=1):
super(SRCNN, self).__init__()
# 第一层卷积:
# 输入通道为num_channels(灰度图为1,彩色图为3),输出通道为64
# 卷积核大小为9×9,padding设为9//2=4,保证输出大小不变(与输入相同)
self.conv1 = nn.Conv2d(num_channels, 64, kernel_size=9, padding=9 // 2)
# 第二层卷积:
# 输入通道为64,输出通道为32
# 卷积核大小为5×5,padding设为5//2=2,保持特征图尺寸不变
self.conv2 = nn.Conv2d(64, 32, kernel_size=5, padding=5 // 2)
# 第三层卷积(重建层):
# 输入通道为32,输出通道为num_channels(重建后的图像)
# 卷积核大小为5×5,padding同样为2
self.conv3 = nn.Conv2d(32, num_channels, kernel_size=5, padding=5 // 2)
# ReLU激活函数,inplace=True节省内存
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
# 经过第一层卷积 + ReLU激活
x = self.relu(self.conv1(x))
# 经过第二层卷积 + ReLU激活
x = self.relu(self.conv2(x))
# 经过第三层卷积(不使用激活函数),输出复原图像
x = self.conv3(x)
return x
3.SRCNN 超分流程图
-
输入低分辨率图像
ILR -
图像预处理:用双线性插值将
ILR放大到目标高分辨率尺寸ISR -
输入预训练的 SRCNN 模型
-
卷积三层提取和恢复细节信息
-
输出高分辨率图像
ISR'
↓ (1)
低分辨率图像
↓ (2)
双线性插值放大
↓ (3)
SRCNN网络
↓ (4)
超分辨率图像输出
4.训练代码的详细解释
"""
Author : Xu fuyong
Time : created by 2019/7/16 20:17
"""
import argparse
import os
import copy
import torch
from torch import nn
import torch.optim as optim
import torch.backends.cudnn as cudnn
from torch.utils.data.dataloader import DataLoader
from tqdm import tqdm
from model import SRCNN # SRCNN模型定义
from datasets import TrainDataset, EvalDataset # 自定义的训练集和验证集数据加载
from utils import AverageMeter, calc_psnr # 计算平均值(如loss/psnr)和PSNR指标
# ---------- 主函数开始 ----------
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# 指定训练数据(HDF5格式)的路径
parser.add_argument('--train-file', type=str, required=True)
# 指定验证数据(HDF5格式)的路径
parser.add_argument('--eval-file', type=str, required=True)
# 模型权重文件保存的目录
parser.add_argument('--outputs-dir', type=str, required=True)
# 上采样放大比例,如2倍、3倍、4倍等
parser.add_argument('--scale', type=int, default=3)
# 学习率(初始值)
parser.add_argument('--lr', type=float, default=1e-4)
# 每个训练批次的样本数量
parser.add_argument('--batch-size', type=int, default=16)
# 加载数据时使用的线程数
parser.add_argument('--num-workers', type=int, default=0)
# 总训练轮数
parser.add_argument('--num-epochs', type=int, default=400)
# 随机种子(确保实验可复现)
parser.add_argument('--seed', type=int, default=123)
args = parser.parse_args()
# 输出路径加入放大倍数子目录
args.outputs_dir = os.path.join(args.outputs_dir, 'x{}'.format(args.scale))
if not os.path.exists(args.outputs_dir):
os.makedirs(args.outputs_dir)
cudnn.benchmark = True
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
torch.manual_seed(args.seed)
# 加载模型,并将其移动到GPU/CPU
model = SRCNN().to(device)
# 损失函数:使用MSE(均方误差)
criterion = nn.MSELoss()
# 优化器:Adam,第三层卷积设置更低学习率(SRCNN论文做法)
optimizer = optim.Adam([
{'params': model.conv1.parameters()},
{'params': model.conv2.parameters()},
{'params': model.conv3.parameters(), 'lr': args.lr * 0.1}
], lr=args.lr)
# 构建训练数据加载器
train_dataset = TrainDataset(args.train_file)
train_dataloader = DataLoader(dataset=train_dataset,
batch_size=args.batch_size,
shuffle=True,
num_workers=args.num_workers,
pin_memory=True,
drop_last=True)
# 构建验证数据加载器
eval_dataset = EvalDataset(args.eval_file)
eval_dataloader = DataLoader(dataset=eval_dataset, batch_size=1)
# 初始化最优模型参数
best_weights = copy.deepcopy(model.state_dict())
best_epoch = 0
best_psnr = 0.0
# ---------- 训练主循环 ----------
for epoch in range(args.num_epochs):
model.train()
epoch_losses = AverageMeter() # 用于记录当前轮的平均loss
with tqdm(total=(len(train_dataset) - len(train_dataset) % args.batch_size)) as t:
t.set_description('epoch:{}/{}'.format(epoch, args.num_epochs - 1))
for data in train_dataloader:
inputs, labels = data # inputs是LR图像,labels是HR图像
inputs = inputs.to(device)
labels = labels.to(device)
preds = model(inputs) # 前向传播得到预测图像
loss = criterion(preds, labels) # 与高分辨率标签图像计算loss
epoch_losses.update(loss.item(), len(inputs))
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播
optimizer.step() # 参数更新
t.set_postfix(loss='{:.6f}'.format(epoch_losses.avg))
t.update(len(inputs))
# 每一轮训练后保存一次模型
torch.save(model.state_dict(), os.path.join(args.outputs_dir, 'epoch_{}.pth'.format(epoch)))
# ---------- 验证部分 ----------
model.eval()
epoch_psnr = AverageMeter()
for data in eval_dataloader:
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
with torch.no_grad():
preds = model(inputs).clamp(0.0, 1.0) # 推理阶段不进行梯度计算
epoch_psnr.update(calc_psnr(preds, labels), len(inputs))
print('eval psnr: {:.2f}'.format(epoch_psnr.avg))
# 如果当前轮的PSNR更高,则保存为最佳模型
if epoch_psnr.avg > best_psnr:
best_epoch = epoch
best_psnr = epoch_psnr.avg
best_weights = copy.deepcopy(model.state_dict())
# 最后保存最好的模型
print('best epoch: {}, psnr: {:.2f}'.format(best_epoch, best_psnr))
torch.save(best_weights, os.path.join(args.outputs_dir, 'best.pth'))
5.工具模块(utils.py)
包含了图像颜色空间转换、PSNR计算、平均值统计器这几类功能,训练与评估 SRCNN 时都会用到。
-
convert_rgb_to_y(img):将 RGB 图像转成亮度 Y 分量(灰度图)
def convert_rgb_to_y(img):
"""
将 RGB 图像转换为 Y 分量(亮度),返回单通道图像
适用于 numpy 或 torch.Tensor 格式图像
"""
if type(img) == np.ndarray:
return 16. + (64.738 * img[:, :, 0] + 129.057 * img[:, :, 1] + 25.064 * img[:, :, 2]) / 256.
elif type(img) == torch.Tensor:
if len(img.shape) == 4:
img = img.squeeze(0) # 去除 batch 维度
return 16. + (64.738 * img[0, :, :] + 129.057 * img[1, :, :] + 25.064 * img[2, :, :]) / 256.
else:
raise Exception('Unknown Type', type(img))
✅ 通常超分模型只对亮度 Y 通道做增强(因为人眼对亮度更敏感,色差通道变化对主观质量影响小)
convert_rgb_to_ycbcr(img):RGB 转 YCbCr(三通道)
def convert_rgb_to_ycbcr(img):
"""
将 RGB 图像转换为 YCbCr 图像格式,返回 [Y, Cb, Cr] 三通道
"""
if type(img) == np.ndarray:
y = 16. + (64.738 * img[:, :, 0] + 129.057 * img[:, :, 1] + 25.064 * img[:, :, 2]) / 256.
cb = 128. + (-37.945 * img[:, :, 0] - 74.494 * img[:, :, 1] + 112.439 * img[:, :, 2]) / 256.
cr = 128. + (112.439 * img[:, :, 0] - 94.154 * img[:, :, 1] - 18.285 * img[:, :, 2]) / 256.
return np.array([y, cb, cr]).transpose([1, 2, 0])
elif type(img) == torch.Tensor:
if len(img.shape) == 4:
img = img.squeeze(0)
y = 16. + (64.738 * img[0, :, :] + 129.057 * img[1, :, :] + 25.064 * img[2, :, :]) / 256.
cb = 128. + (-37.945 * img[0, :, :] - 74.494 * img[1, :, :] + 112.439 * img[2, :, :]) / 256.
cr = 128. + (112.439 * img[0, :, :] - 94.154 * img[1, :, :] - 18.285 * img[2, :, :]) / 256.
return torch.cat([y, cb, cr], 0).permute(1, 2, 0)
else:
raise Exception('Unknown Type', type(img))
convert_ycbcr_to_rgb(img):YCbCr 转 RGB
def convert_ycbcr_to_rgb(img):
"""
将 YCbCr 图像转换为 RGB 图像格式
"""
if type(img) == np.ndarray:
r = 298.082 * img[:, :, 0] / 256. + 408.583 * img[:, :, 2] / 256. - 222.921
g = 298.082 * img[:, :, 0] / 256. - 100.291 * img[:, :, 1] / 256. - 208.120 * img[:, :, 2] / 256. + 135.576
b = 298.082 * img[:, :, 0] / 256. + 516.412 * img[:, :, 1] / 256. - 276.836
return np.array([r, g, b]).transpose([1, 2, 0])
elif type(img) == torch.Tensor:
if len(img.shape) == 4:
img = img.squeeze(0)
r = 298.082 * img[0, :, :] / 256. + 408.583 * img[2, :, :] / 256. - 222.921
g = 298.082 * img[0, :, :] / 256. - 100.291 * img[1, :, :] / 256. - 208.120 * img[2, :, :] / 256. + 135.576
b = 298.082 * img[0, :, :] / 256. + 516.412 * img[1, :, :] / 256. - 276.836
return torch.cat([r, g, b], 0).permute(1, 2, 0)
else:
raise Exception('Unknown Type', type(img))
calc_psnr(img1, img2):计算两个图像之间的 PSNR
def calc_psnr(img1, img2):
"""
计算 PSNR(峰值信噪比),用于评估图像质量
公式:PSNR = 10 * log10(MAX^2 / MSE)
"""
return 10. * torch.log10(1. / torch.mean((img1 - img2) ** 2))
💡 PSNR 越高,表示生成图像与真实图像越接近。一般 PSNR > 30dB 代表质量较好。
AverageMeter:计算损失或指标的平均值
class AverageMeter(object):
"""
用于记录每个 epoch 中 loss 或 PSNR 的平均值
"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0 # 当前值
self.avg = 0 # 平均值
self.sum = 0 # 总和
self.count = 0 # 样本数量
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
✅ 在训练过程中,每个 batch 的 loss 会不断更新到 AverageMeter 中,用来输出当前 epoch 的整体表现。
总结
| 工具函数 | 作用 |
|---|---|
convert_rgb_to_y | 提取亮度 Y 通道 |
convert_rgb_to_ycbcr / convert_ycbcr_to_rgb | YCbCr 和 RGB 互转 |
calc_psnr | 衡量超分图像质量的指标 |
AverageMeter | 记录 loss 或 PSNR 的平均值,用于日志输出 |
PS:
✅ YCbCr 和 RGB 是啥?
| 颜色空间 | 含义 | 通道解释 |
|---|---|---|
| RGB | 人眼直接看到的红绿蓝三通道颜色 | R:红,G:绿,B:蓝 |
| YCbCr | 亮度-色差通道(常用于压缩) | Y:亮度(Luma),Cb:蓝色色差,Cr:红色色差 |
✅ 为什么要转成 YCbCr?
-
Y 分量对人眼最敏感,图像的结构、轮廓主要靠 Y 分量;
-
Cb 和 Cr 是色彩细节,对人眼感知影响较小;
-
很多图像超分模型只处理亮度 Y 分量(加快训练速度,提升效果);
-
像 JPEG、MPEG 这类图像视频压缩格式就是基于 YCbCr 的;
-
YCbCr 分离后,可以只对 Y 通道增强,然后再和原始的 Cb、Cr 组合回去生成彩色图像。
✅ 举个例子,SRCNN 超分里怎么用的?
以 convert_rgb_to_ycbcr → 超分模型处理 Y → 再 convert_ycbcr_to_rgb 为例流程:
原始 RGB 图像
↓
RGB → YCbCr(分离 Y、Cb、Cr)
↓
模型只处理 Y(比如提升清晰度)
↓
保持原 Cb、Cr 不变,增强后的 Y 和它们合并
↓
YCbCr → RGB,恢复成彩色图像
这样模型就只专注提升图像亮度结构,既高效又有效!
✅ 总结一句话:
YCbCr 转换是为了“分离亮度和色彩”,专注处理对图像质量最关键的亮度部分,提升效率和效果。
6.补充解释
🔸 模型输入 & 标签
-
输入图像(inputs):是低分辨率(LR)图像,经过双三次插值放大到HR尺寸,但图像细节丢失。
-
标签图像(labels):是高分辨率(HR)原图(也只用Y通道),作为监督信号,用于计算损失。
-
在训练过程中,模型的任务就是学习从模糊的LR图像中恢复出接近HR的图像。
🔸 为什么要用标签?
超分属于监督学习,需要“输入-输出对”来训练模型。标签是我们希望模型输出的“真值”,没有它,模型就无法知道“自己错了多少”。
🔸 batch size 是什么?
-
batch_size=16表示每次训练喂给模型 16张图像块(patch)----每次训练迭代,模型会同时处理 16 张图像(具体是 16 对 LR 输入图像 和 HR 标签图像)。 -
较大的 batch size 训练更稳定,但显存占用更高。
-
如果你的GPU显存小,可以调成 8、4 等。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









