






开源代码:https://github.com/medcx/PFAD
摘要
磁共振成像(MRI)中存在的运动伪影会严重干扰临床诊断。去除运动伪影是一个直接明了的解决方案,并且已经得到了广泛研究。然而,在近期的研究工作中仍然严重依赖成对数据,并且k空间(频域)中的扰动没有得到很好的考虑,这限制了它们在临床领域的应用。为了解决这些问题,我们提出了一种新颖的无监督净化方法,该方法利用有噪声的MRI图像的像素-频率信息来引导预训练的扩散模型恢复清晰的MRI图像。具体来说,考虑到运动伪影主要集中在k空间的高频分量中,我们利用低频分量作为引导,以确保组织纹理的正确性。此外,鉴于高频和像素信息有助于恢复形状和细节纹理,我们设计了交替互补掩码,以同时破坏伪影结构并利用有用信息。在来自不同组织的数据集上进行了定量实验,结果表明我们的方法在多个指标上都取得了优异的性能。与放射科医生进行的定性评估也表明,我们的方法提供了更好的临床反馈。
磁共振成像(MRI)作为无创医学成像技术,已在临床诊断中广泛应用。但因其采集时间长,部分患者(如老年人、幽闭恐惧症或癫痫患者等)在扫描过程中易因不适产生运动,这会破坏 MRI 的 k 空间(频域)信号分布,产生运动伪影,严重干扰临床诊断与治疗,因此亟需探索有效缓解运动伪影影响的方法。
最近,去噪扩散概率模型 (DDPM) 在图像生成领域表现出出色的表现 (Song, Meng, and Ermon 2020;Ho 和 Salimans 2022)。已经验证,结合图像(Rombach 等人,2022 年;Saharia 等人,2022a) 或文本(Nichol 等人,2021 年;Ramesh 等人,2022 年;Saharia 等人,2022b;Si 等人,2023 年;Zhang、Rao 和 Agrawala 2023)可以在 DDPM 的推理过程中促进生成针对特定要求量身定制的所需图像。然而,尽管基于扩散的方法在纯化或重建自然图像方面具有出色的能力,但在去除 MRI 图像的运动伪影方面的性能仍然有限。这是因为运动伪影存在于 k 空间中,而在其纯化过程中只有像素域信息感兴趣。
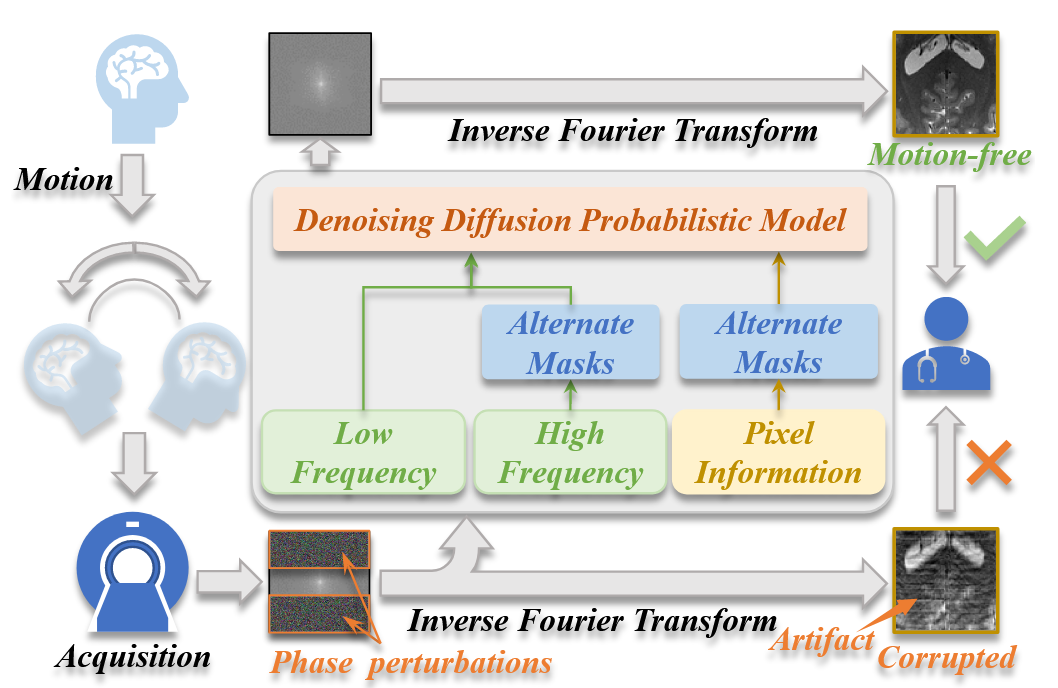
PFAD 方法核心思想概览
-
预训练扩散模型(Diffusion Model)
-
使用未配对的 清晰MRI图像 对扩散模型进行预训练,学习无伪影图像的分布(即理想分布)。
-
-
低频引导(Low-Frequency Guidance)
-
从受污染图像中提取低频部分,提供大致结构/纹理引导,使扩散生成更具结构一致性。
-
-
交替掩码(Alternate Masks)
-
对图像的高频/像素部分及生成图像应用掩码,有选择地打乱伪影,保留有价值信息用于恢复;
-
掩码在每次反向扩散步骤中 交替翻转,覆盖图像不同区域,有助于全局伪影去除。
-
-
扩散扰动调节参数(Diffusion Time-Dependent Parameter)
-
引入一个随时间变化的参数,在扩散过程中增强对伪影的扰动效果,改善最终图像质量。
-
-
频域-像素域恢复权重平衡超参数(Balancing Hyperparameter)
-
控制频域与像素域信号之间的恢复权重,获得最优清晰图像。
-
贡献
-
“无监督 + 像素-频率融合”:避开了配对数据难题,这是很多医学图像问题中的痛点;
-
“替代互补掩码”机制:和常规的掩码不同,PFAD是动态交替的,这种机制确实在频域/像素域去伪影中相当有效;
-
“动态调节参数 + 消融实验”:从方法设计到实验验证都非常严谨完整。
Methodology
Preliminary
Notice
| 符号 | 含义 | 类比理解 |
|---|---|---|
| x | 图像数据(小写) | 就是我们处理的图像,比如 MRI 图像 |
| t | 当前时间步 | 相当于“第几次加噪” |
| T | 总共的时间步 | 加噪一共加了几次,比如 1000 步 |
| 高斯分布 | 就是随机生成噪声的“随机函数” | |
| 神经网络(扩散模型) | 我们要训练的模型,参数是 θ\thetaθ | |
| 傅里叶变换/逆变换 | 把图像变成频率域、再变回来 | |
| 理想低通、高通滤波器 | 提取图像的低频轮廓 / 高频细节 | |
| 模值运算 | ||
| ⊙ | Hadamard积(点乘) | 对应元素相乘,比如两个图像重叠的像素点相乘 |
Diffusion Model
扩散过程(Forward Process)
我们从一张干净图像 开始,一步步往里面加随机噪声(白噪声),过程如下:

-
第一步:x1=在 x0 上加一点点噪声
-
第二步:x2=再加一点噪声
-
…
-
第 T 步后:图像变成一堆纯噪声(就像雪花电视)
公式表达:![]()
-
每一步加的噪声强度是
,随着 t 增大;
-
I是单位矩阵,表示噪声是独立的;
-
这一步是固定的,不需要神经网络来学习。
反向去噪(Reverse Process)
这是模型要学习的核心部分!我们希望:
能不能从纯噪声 xT,一步步“去噪”,还原出干净图像 x0?
于是我们设计了一个神经网络 ,学会从
预测出上一步
。
![]()
-
μθ(xt,t):神经网络预测的“去噪后图像的均值”;
-
:是我们手动设置的噪声强度;
-
模型会从
开始,逐步生成
。
训练方法(Learning)
如何训练这个模型呢?我们不直接让模型预测图像本身,而是让它预测“加进去的噪声 ”!
我们构造带噪图像:
![]()
然后让模型预测出 ,用 L2 loss 训练:
![]()
其中:
-
是你训练的神经网络,输入
和时间步 t,输出噪声预测;
-
如果它能正确预测出加进去的噪声,那么我们就能反推出原图
整个流程
| 步骤 | 描述 | 类比 |
|---|---|---|
| 1. Forward | 清晰图像一步步加噪成纯噪声 | 把照片撕碎 |
| 2. Reverse | 模型学会从纯噪声一步步恢复出清晰图像 | 照片修复术 |
| 3. 训练目标 | 让模型学会预测噪声,以间接学会去噪 | 学会还原破坏过程 |
Motion Artifact Removal with PFAD
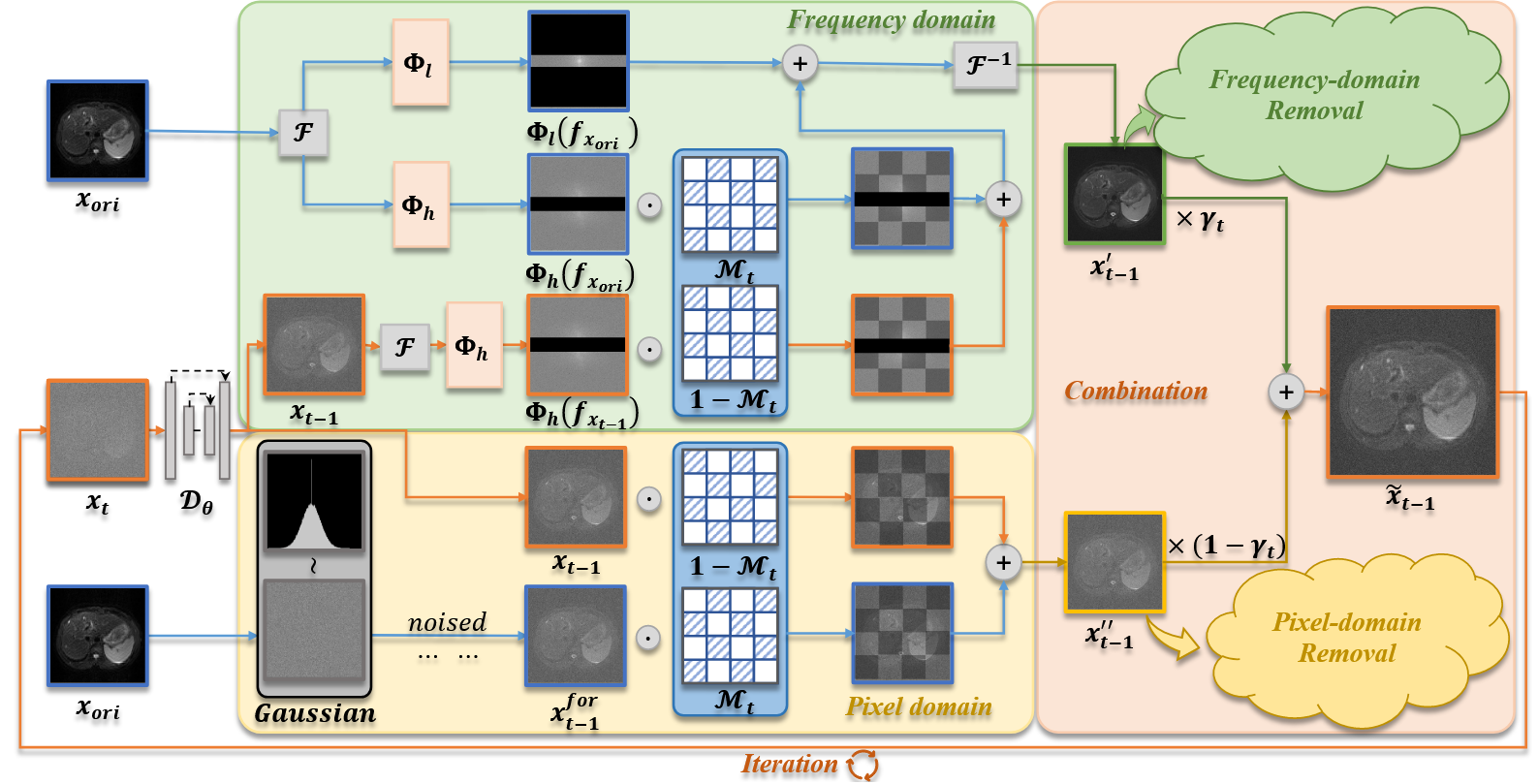
绿色区域是频域中的伪影去除过程。这个过程以运动损坏图像的低频信息和部分高频信息为导向,并使用扩散模型生成另一部分干净的高频信息。黄色区域是像素域伪影去除过程,由前向过程的部分图像信息引导。将两个域的结果组合在一起后,最终迭代生成干净的图像。
PFAD 的原理和过程框架如如图 2 所示。首先,我们介绍了如何在频域和像素域中分别使用交替互补掩码。其次,我们介绍如何创建替代互补掩码。最后,我们设计了一个超参数来平衡频域和像素域的权重。整个过程的详细信息如算法 1 所示。

Frequency Domain Removal
目标是:在频率域中消除运动伪影(Motion Artifact)
-
x_ori:原始的含有运动伪影的图像。 -
x'_{t-1}:在频域上重组后的图像(去伪影处理的目标)。 -
f:图像的频率信息(通过傅里叶变换得到)。 -
Φ_l(.):低频成分提取操作(Low-Frequency Extractor)。 -
Φ_h(.):高频成分提取操作(High-Frequency Extractor)。 -
M_t:交替的互补掩码(Alternate Complementary Mask),用于融合不同图像的高频部分。 -
⊙:表示逐元素乘法。 -
F⁻¹:傅里叶反变换操作,将频域图像还原到时域。
(4)低频保持不变:
![]()
将 x_ori(带有运动伪影的图像)中提取出的低频部分直接保留,用于重建图像的低频结构。
因为低频部分主要包含图像的大致轮廓和颜色,不容易受到运动伪影的影响。
(5)高频交替掩码融合:
![]()
将当前带伪影图像 x_ori 与上一时刻图像 x_{t-1} 的高频部分按掩码 M_t 做融合处理。
-
M_t是一个交替的二值掩码,用来决定当前时刻保留哪一部分频率的信息。 -
M_t的作用是为了在时间上(或多个估计结果之间)互补性地去除伪影,防止同一个区域反复保留错误的高频信息。 -
这一步的目标是:剔除掉受到运动伪影影响的高频区域,同时补充可靠的高频细节。
(6)频域重建:
![]()
将上面获得的高频和低频信息组合,再通过傅里叶反变换 F⁻¹ 恢复出一个在时域中去除了部分运动伪影的图像 x'_{t-1}。
总结
-
保留低频信息(不容易受到伪影影响)。
-
用互补掩码融合高频(去除运动伪影影响大的高频区域)。
-
组合高低频,重建图像。
整个过程就是在频率域里,通过选择性保留信息 + 互补融合机制,来减弱运动伪影对图像的破坏。
Pixel Domain Removal
前面 Frequency Domain Removal 已经做了一轮修复,但为什么还要在像素域再做一次呢?原因有两个核心点:
- 弥补低频信息缺失,提高图像自然度:频率域处理主要是高频修复(细节、纹理),虽然有效,但缺少对低频结构(轮廓、色调等)的处理,导致整体图像会显得不自然、不协调。
- 修正频域中因取模操作造成的轻微相位偏差:频域重建时,因频域处理可能涉及相位错位(尤其在反变换时),会导致图像位置偏差或模糊。而像素域的操作可以直接在图像层面进行细化修复。
方法与公式
![]()
与频率域不同的是,这里用的是 x_for_{t-1} 而不是 x_ori,即前向过程生成的图像。
-
x''_{t-1}:在像素域中重组后的图像。 -
x^{for}_{t-1}:前向扩散过程生成的图像(forward process image),具备一定生成能力。(“由清晰图像加噪得到的第t-1步结果,比较接近真实,能提供修复参考。”) -
x_{t-1}:上一个时间步的重建图像。(“正在恢复图像的当前版本,有点模糊、有些伪影。”) -
M_t:互补掩码(和频域一样),决定保留哪个图像的哪一部分。 -
⊙:逐元素乘法,代表按位融合。
在像素层面重新融合图像内容:
-
x^{for}_{t-1} ⊙ M_t:使用 diffusion 模型生成的图像作为“参考或修复”来源,用于替代图像中含有伪影的区域。 -
x_{t-1} ⊙ (1 - M_t):保留上一时刻的图像中未被污染的部分。
最终生成的 x''_{t-1} 是一个 经过像素级重构 的图像,既借助了扩散模型的生成能力,又保留了稳定的局部信息,从而提升整体质量和自然感。
| 名称 | 形式 | 含义 | 来源 | 作用 |
|---|---|---|---|---|
x_{t-1} | reverse step 中的图像 | 当前反扩散步骤的输出 | 来自 x_t 通过去噪预测得到 | 当前生成的图像版本 |
x^{for}_{t-1} | forward step 中的图像 | 清晰图像通过扩散正向到第 t-1 步 | 从 GT 清晰图像加噪得到 | 提供参考/指导用图像(较真实) |
总结
| 阶段 | 方法 | 目的 | 融合对象 |
|---|---|---|---|
| Frequency Domain Removal | 在频域内对高频信息处理 | 去除明显伪影、恢复细节纹理 | x_ori 与 x_{t-1} 的高频部分 |
| Pixel Domain Removal | 在像素域中融合原图和扩散图像 | 修复低频结构、弥补频域缺陷 | x^{for}_{t-1} 与 x_{t-1} 的像素值 |
Alternate Complementary Masks
1. 设计背景:为什么要使用“掩码”?
在扩散模型中,图像是逐步生成的。由于运动伪影往往呈现区域性分布(比如条纹、拖影),我们不能整张图统一处理,否则会破坏图像中仍然保留的“有用信息”。
因此使用掩码 m_t,只处理图像中的一部分区域:
-
有助于保留未被破坏的信息。
-
但也存在问题:未处理区域可能继续带有运动伪影。
2. 交替互补(Alternate Complementary)是啥意思?
以前的工作(比如 Lugmayr 2022)使用的是固定掩码,也就是说每一轮都遮住相同位置的信息,容易导致某些区域总是没被处理,某些区域总是被处理,信息不均衡。
而 PFAD 的创新点是:
每一轮反向步骤中使用 互补掩码:
![]()
-
假设
m_t是一个“交错网格”掩码(比如类似国际象棋黑白格子), -
那么
m_{t-1}就是它的反色(黑白互换),正好遮住之前没处理的区域。
这样迭代下来,整个图像的所有区域都会被掩盖处理一遍,从而达到完整地打破运动伪影分布的目的,同时最大程度保留有用信息。
3. 问题:掩码虽然打破伪影,但也留下伪影!
虽然掩码有作用,但保留下来的区域依旧含有部分运动伪影,会继续影响扩散模型生成。
怎么办?
4. 解决方法:引入权重因子 ωₜ 来动态调整掩码作用强度
![]()
其中:
-
是布尔掩码(0或1);
-
是一个 时间相关的权重;
-
,这是 DDPM 中的固有参数。
5. 的变化趋势:从1逐渐到0
时间步 t | 位置 | 解释 |
|---|---|---|
| t = T (初始) | ωₜ ≈ 1 | 初始噪声很多,掩码可以大胆保留有用信息 |
| t 减小时 | ωₜ 减小 | 图像越生成越清晰,逐步降低伪影区域的保留强度 |
| t → 0(生成完成) | ωₜ → 0 | 图像已经生成完整,此时若再保留带伪影的区域,会影响质量,需要抑制它 |
📌 所以这个机制的意义是:
初期:注重结构生成,允许有些带伪影区域提供信息;
后期:图像结构已具备,要重点清理掉残留伪影,减少其影响。
总结
PFAD 的交替互补掩码机制,通过交错处理所有区域 + 动态调整掩码作用强度,实现了在保留有用信息的同时,逐步剥离运动伪影的影响,这是其性能优于传统 Diffusion 的关键之一。
Dual Domain Balance(双域融合平衡)
1.问题背景:为什么要双域融合?
| 域 | 优点 | 缺点 |
|---|---|---|
| 频率域 Frequency Domain | 擅长去除结构性伪影(如条纹、重影),恢复纹理细节 | 容易因频域处理带来不自然感 |
| 像素域 Pixel Domain | 更接近图像本身表现,利于还原自然视觉 | 对细节和纹理恢复相对弱 |
所以,如果只靠一个域来重建图像,会有失偏颇:
-
频域强去伪影,但图像不自然;
-
像素域保证自然感,但伪影清理不彻底。
所以——✅ 将两者融合,并且融合比例要“动态变化” —— 这就是 Dual Domain Balance 的核心思想。
2.引入平衡因子 γₜ
作者提出了一个随时间变化的融合权重 γₜ,控制频率域图像 x′_{t-1} 和像素域图像 x′′_{t-1} 的权重。
公式如下:
![]()
-
,即初始时接近 1,后期逐渐降低;
-
超参数 a∈[0,1],可以控制下降速率。
这意味着,在整个去噪(反扩散)过程中,随着时间 t 变小,频域的权重逐步降低,像素域权重逐步提高。
3.融合公式:生成最终的组织图像
![]()
解释如下:
-
:频域重组图像(带细节,擅长去伪影);
-
:像素域重组图像(保持自然感,补偿频域损失);
-
:两者加权融合的最终重组图像,进入下一步扩散。
4.为什么这个设计很妙?
| 时间阶段 | γₜ 值 | 代表策略 | 原因 |
|---|---|---|---|
| 反扩散初期 (t ≈ T) | γₜ ≈ 1 | 主要靠频域去除大伪影 | 此时图像噪声较大,频域更有效 |
| 中期 | γₜ ≈ 0.7~0.5 | 两者加权融合 | 图像逐步成型,开始讲究自然感 |
| 后期 (t → 0) | γₜ → 1 - a(可能≈0.2) | 主要靠像素域恢复真实感 | 此时形状基本定型,需要提升视觉质量 |
总结
PFAD 通过引入 随时间变化的权重 γₜ,实现了频域去伪影与像素域图像自然性的动态平衡融合,实现了既清晰又自然的图像重建,是整个系统精华所在.
总结
- 研究贡献:提出新颖扩散模型架构用于运动伪影去除
- 方法创新:引入 Pixel-Frequency 双域互补掩码
- 实验效果:真实图像效果好,模拟图像略逊
- 总结意义:提升诊断可靠性,有望辅助临床医生
代码讲解
scripts/image_sample.py
PFAD 的“推理入口脚本”,它负责加载预训练模型、读取运动伪影图像、进行图像还原(artifact removal),并将还原后的图像保存下来。
总体结构:
| 部分 | 说明 |
|---|---|
| 1️⃣ 配置与参数 | 设置种子,读取 YAML 配置文件,准备推理参数。 |
| 2️⃣ 模型加载 | 创建 model 和 diffusion,并加载权重。 |
| 3️⃣ 读取数据 | 从本地读取运动伪影图像。 |
| 4️⃣ 前向推理 | 利用 PFAD 进行 artifact removal。 |
| 5️⃣ 保存图像 | 把还原图像写入 .tiff 文件。 |
"""
生成去伪影后的图像样本,并保存为.tiff格式
此脚本用于PFAD模型的推理过程
"""
import argparse
import os
import random
import numpy as np
import torch
import yaml
import SimpleITK as sitk # 用于处理医学图像格式(如TIFF)
# 导入PFAD相关模块
from guided_diffusion import dist_util, logger
from guided_diffusion.script_util import (
model_and_diffusion_defaults, # 获取默认模型配置
create_model_and_diffusion, # 创建模型和扩散器
add_dict_to_argparser, # 将配置字典转为argparser参数
args_to_dict # 从argparser对象提取参数为字典
)
def main():
# 指定GPU设备(这里默认用第0块卡)
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
# 固定随机种子,保证结果可复现
seed = 42
np.random.seed(seed)
random.seed(seed)
torch.manual_seed(seed)
# 命令行参数:配置路径、图像目录、保存目录
parser = argparse.ArgumentParser()
parser.add_argument('--conf_path', type=str, default='../conf/brain_sample_config.yml')
parser.add_argument('--img_dir', type=str, default='brain') # 图像子目录名
parser.add_argument('--save_path', type=str, default='motion_remove') # 结果保存目录
config = parser.parse_args()
# 加载 YAML 配置文件
with open(config.conf_path) as f:
c = yaml.load(f, Loader=yaml.FullLoader)
# 将配置文件中参数添加到 parser 中,并解析
add_dict_to_argparser(parser, c)
args = parser.parse_args()
# 设置分布式(这里虽然是单卡,但PFAD框架是为多卡设计的)
dist_util.setup_dist()
# 日志记录初始化
logger.configure()
logger.log("creating model and diffusion...")
# 创建模型与diffusion对象
model, diffusion = create_model_and_diffusion(
**args_to_dict(args, model_and_diffusion_defaults().keys())
)
# 加载预训练模型权重
model.load_state_dict(
dist_util.load_state_dict(args.model_path, map_location="cpu")
)
# 将模型放到GPU上
model.to(dist_util.dev())
# 若设置fp16精度,进行转换
if args.use_fp16:
model.convert_to_fp16()
# 获取 PFAD 中定义的采样函数
sample_fn = diffusion.PFAD_sample
logger.log("sampling...")
# ========== 图像推理主循环 ==========
# 设置运动伪影图像路径与结果保存路径
motion_corrupted_dir = f'../data/{args.img_dir}'
save_path = f'../results/{args.save_path}/{args.img_dir}'
os.makedirs(save_path, exist_ok=True)
# 获取所有待处理图像名列表
motion_corrupted_list = os.listdir(motion_corrupted_dir)
motion_corrupted_list.sort() # 保证处理顺序一致
# 遍历每张图像进行去伪影
for i, d in enumerate(motion_corrupted_list):
d_path = f'{motion_corrupted_dir}/{d}'
# 读取图像并归一化到 [-1, 1]
t = sitk.GetArrayFromImage(sitk.ReadImage(d_path)).astype(np.float32)
t = (t - t.min()) / (t.max() - t.min()) * 2 - 1
# 增加 batch 维度和通道维度,形成 shape: (1, 1, H, W)
t_d = np.expand_dims(t, axis=(0, 1))
logger.log(f"Artifact Removal: {d}")
# 构建输入 batch
batch = {
'GT': t_d, # GT 是运动伪影图像(PFAD 以此为输入)
}
# 转为 tensor,并移动到 GPU
for k in batch.keys():
if not isinstance(batch[k], torch.Tensor):
batch[k] = torch.from_numpy(batch[k])
batch[k] = batch[k].to(dist_util.dev())
# 传入模型的附加信息
model_kwargs = {
"gt": batch['GT'], # PFAD网络需要的原始图像
"diff": diffusion # 采样函数可能会用到diffusion对象本身
}
# 推理过程,不需要计算梯度
with torch.no_grad():
sample = sample_fn(
model,
(t_d.shape[0], 1, args.image_size, args.image_size), # 输出尺寸
clip_denoised=args.clip_denoised,
model_kwargs=model_kwargs,
device=dist_util.dev(),
conf=args
)
# 取出结果,并还原回 [0, 65535](保存为 uint16 图像)
recovered = sample['out'].cpu().detach().numpy().squeeze()
recovered = recovered.clip(-1, 1)
recovered = (((recovered + 1) / 2) * 65535).astype(np.uint16)
# 保存为 tiff 图像
recovered = sitk.GetImageFromArray(recovered)
sitk.WriteImage(recovered, f'{save_path}/clean_{i}.tiff')
logger.log("sampling complete")
# 用于未来扩展时的argparser创建函数(当前没用上)
def create_argparser():
defaults = dict(
clip_denoised=True,
num_samples=10000,
batch_size=16,
use_ddim=False,
model_path="",
)
defaults.update(model_and_diffusion_defaults())
parser = argparse.ArgumentParser()
add_dict_to_argparser(parser, defaults)
return parser
if __name__ == "__main__":
main()
GaussianDiffusion
核心任务:
-
前向扩散过程:给图像添加噪声。
-
反向去噪采样过程:逐步还原图像。
-
训练损失计算:构建监督信号进行模型训练。
| 方法名 | 作用 | 所属阶段 |
|---|---|---|
q_sample | 将噪声添加到图像,模拟前向过程 | 前向扩散 |
q_mean_variance | 给定原图和时间步,计算前向分布的均值和方差 | 前向扩散 |
q_posterior_mean_variance | 给定 t 时刻噪声图,预测 t-1 时刻的图 | 反向过程 |
p_mean_variance | 模型预测的均值、方差输出 | 反向采样 |
p_sample | 单步采样,即从 t 到 t-1 的预测 | 反向采样 |
training_losses | 训练阶段计算损失函数 | 训练 |
PFAD_sample | PFAD中特有,带mask引导的扩散采样 | 反向采样 |
deal_out | 结合 GT mask 和 gamma 计算最终输出图像 | 后处理 |
_scale_timesteps | 如果使用浮点数时间步,进行归一化处理 | 时间步变换 |
第1步:首先,了解扩散模型的前向过程(加噪声)和反向过程(去噪声)
def q_sample(self, x_start, t, noise=None):
"""
执行正向扩散步骤,通过向数据添加噪声。
该函数从 q(x_t | x_0) 中采样,通过将噪声添加到输入图像 `x_start` 中进行 `t` 次扩散步骤。
:param x_start: 初始数据批次(原始图像)。
:param t: 当前扩散步骤的时间步(从 0 开始,表示一次扩散步骤,`t` 对应于扩散的次数)。
:param noise: 可选参数,添加的噪声。如果未提供,将生成正态分布的随机噪声。
:return: 扩散 `t` 步之后的噪声图像。
"""
if noise is None:
# 如果未提供噪声,则生成与 `x_start` 形状相同的随机噪声。
noise = th.randn_like(x_start)
# 检查噪声的形状是否与 `x_start` 相匹配。
assert noise.shape == x_start.shape
# 通过应用扩散过程的 alpha 系数来计算带噪声的图像。
# 我们为每个时间步提取相关的 alpha 值,并将噪声添加到图像中。
return (
_extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start # 缩放的 x_start
+ _extract_into_tensor(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise # 噪声
)
def p_sample(
self,
model,
x,
t,
clip_denoised=True,
denoised_fn=None,
cond_fn=None,
model_kwargs=None
):
"""
从模型中采样前一个时间步 `x_{t-1}`。
该函数根据给定的时间步 `t` 从模型中采样前一个状态 `x_{t-1}`。
模型生成用于去噪的预测均值和方差。
:param model: 用于执行去噪的模型。
:param x: 当前在时间步 `t` 的噪声图像。
:param t: 当前时间步。
:param clip_denoised: 如果为 True,则对去噪后的图像进行裁剪,将其值限制在 [-1, 1] 之间。
:param denoised_fn: 如果不为 None,则应用该函数来处理去噪后的 `x_start` 预测结果。
:param cond_fn: 如果不为 None,则这是一个类似于模型的梯度函数,用于条件化模型。
:param model_kwargs: 如果不为 None,这是一个字典,包含要传递给模型的额外关键词参数。这可以用于条件化。
:return: 一个字典,包含以下键:
- 'sample': 从模型中采样得到的随机样本。
- 'pred_xstart': 对 `x_0` 的预测。
"""
# 生成随机噪声,形状与当前输入图像 `x` 相同。
noise = th.randn_like(x)
# 获取模型对当前图像 `x` 在时间步 `t` 下的均值和方差。
out = self.p_mean_variance(
model,
x,
t,
clip_denoised=clip_denoised,
denoised_fn=denoised_fn,
model_kwargs=model_kwargs,
)
# 创建一个非零掩码,如果当前时间步 `t` 不为 0,则掩码为 1,否则为 0。
nonzero_mask = (
(t != 0).float().view(-1, *([1] * (len(x.shape) - 1)))
)
# 如果提供了条件函数,则使用该函数来条件化均值。
if cond_fn is not None:
out["mean"] = self.condition_mean(
cond_fn, out, x, t, model_kwargs=model_kwargs
)
# 使用均值和方差对噪声进行采样。
sample = out["mean"] + nonzero_mask * \
th.exp(0.5 * out["log_variance"]) * noise
# 返回一个字典,包含采样结果和 `x_0` 的预测。
result = {"sample": sample,
"pred_xstart": out["pred_xstart"], 'gt': model_kwargs.get('gt')}
return result
def PFAD_sample(
self,
model,
shape,
noise=None,
clip_denoised=True,
denoised_fn=None,
cond_fn=None,
model_kwargs=None,
device=None,
conf=None
):
"""
从模型生成样本,并在每个扩散时间步生成中间样本。
参数与 `p_sample_loop()` 函数相同。
返回一个生成器,每次迭代返回一个字典,字典包含 `p_sample()` 函数的返回值。
:param model: 用于生成样本的模型。
:param shape: 生成样本的形状(例如,图像的大小)。
:param noise: 添加到样本的噪声,默认为 None。
:param clip_denoised: 如果为 True,则对去噪后的图像进行裁剪。
:param denoised_fn: 如果不为 None,则应用该函数来处理去噪后的图像。
:param cond_fn: 如果不为 None,则使用该函数进行条件化。
:param model_kwargs: 包含额外的关键词参数,传递给模型。
:param device: 设备(如 CPU 或 GPU),默认为 None。
:param conf: 配置参数,控制扩散过程的细节(例如,时间步数、补丁大小等)。
:return: 返回一个字典,包含最终生成的图像。
"""
if device is None:
# 如果未指定设备,则使用模型的默认设备(通常是 GPU)。
device = next(model.parameters()).device
# 确保 `shape` 是元组或列表。
assert isinstance(shape, (tuple, list))
# 获取原始图像
ori_img = model_kwargs['gt']
# 初始化图像
image_after_step = th.randn_like(ori_img)
if conf.middel_removal:
# 如果启用了中间去除,则按照指定的中间去除步数进行扩散。
t_f = th.tensor([conf.middel_removal] * shape[0], device=device)
image_after_step = self.q_sample(ori_img, t_f, noise)
time = conf.middel_removal
else:
# 否则,使用配置中的时间步数。
time = int(conf.timestep_respacing) if conf.timestep_respacing is not None else 1000
# 创建交替的互补掩码
patch_size = conf.patch_size
image_size = (shape[-1], shape[-1])
mask = create_mask(patch_size, image_size)
# 设定扩散步骤的时间序列,从高时间步到低时间步。
times = range(time - 1, -1, -1)
from tqdm import tqdm
time_pairs = tqdm(times)
j = 0
# 在每个扩散时间步进行样本生成
for t_cur in time_pairs:
t = th.tensor([t_cur] * shape[0], device=device)
img_forward = self.q_sample(ori_img, t, noise)
if j % 2 == 1:
mask = 1 - mask # 切换掩码
with th.no_grad():
# 从模型中采样并去噪
out = self.p_sample(
model,
image_after_step,
t,
clip_denoised=clip_denoised,
denoised_fn=denoised_fn,
cond_fn=cond_fn,
model_kwargs={},
)
# 处理输出图像
image_after_step = self.deal_out(out["sample"], ori_img, img_forward, t, mask, conf.gamma_t)
j += 1
return {'out': image_after_step} # 返回最终生成的图像
PFAD_sample
PFAD 中的核心采样过程,它基于扩散模型的反向过程进行图像恢复,同时加入了一种创新性的 “交替掩膜机制” 来控制哪些区域恢复、哪些保持原始结构,是 PFAD 的最大亮点之一。
这个函数从一个随机噪声图像开始,利用反向扩散过程一步步还原图像,同时引导模型专注于恢复图像的模糊区域,并保留清晰区域不被破坏。
函数结构拆解图(流程图级别理解):
输入:
model, shape, ori_img (from model_kwargs), mask配置conf, etc.
↓(初始化)
1. image_after_step ← 纯噪声图(randn_like ori_img)
2. 如果 conf 设置了 middel_removal → 用 q_sample 加中间t加噪(=partial blur)
↓(for 循环,逆扩散)
3. for t in T-1 to 0:
- 构造 img_forward = ori_img 在当前 t 的加噪版本
- 隔一步翻转 mask(实现交替采样)
- 执行 p_sample 得到模型预测图 sample
- 调用 deal_out 将 sample + ori_img + img_forward + mask 组合成新的 image_after_step
↑ 重复
输出:
image_after_step(恢复后的图像)
deal_out(双频融合)
PFAD 的核心处理函数之一,它将频域知识融合进了扩散模型的图像恢复过程中
deal_out接收模型预测图(img_reverse)、原图(ori_img)、当前加噪图(img_forward)和交替掩膜,通过频域混合 + 空间域插值,生成新的更合理的图像状态img_re,以便进入下一个扩散步。
大致结构如下(流程拆解):
img_reverse ← 当前模型预测的图像
ori_img ← 原始清晰图像(GT)
img_forward ← 当前时间步的前向噪声图(模糊版本)
gt_keep_mask ← 控制哪个区域保留原图的掩膜
gamma_t ← 控制两个输出融合程度的参数
→ step 1: 频域融合(得到x_1)
→ step 2: 空间域融合(得到x_2)
→ step 3: 两个结果再加权融合(输出img_re)
第一步:频域重建 x_1:结合原图和模型预测图的频率成分
gt_k_space = fft2(ori_img_2d) # 原图的频谱
x_reverse_space = fft2(img_reverse_2d) # 模型预测图的频谱
傅里叶变换后的图像变成频域图,每个值表示一种频率成分的强弱。
接着:
low_freq[keep, :] = gt_k_space[keep, :]
high_freq_keep[change, :] = gt_k_space[change, :]
high_freq_change[change, :] = x_reverse_space[change, :]
把:
-
低频部分(图像结构信息) → 保留原图
-
高频部分 → 保留原图的一部分 + 模型预测图的一部分
然后构造融合频谱:
x_re_freq = low_freq + high_freq_keep * freq_mask + high_freq_change * (1 - freq_mask)
这个 freq_mask 控制“用 GT 还是预测的高频”。
最后你用反傅里叶:
x_re = np.abs(ifft2(x_re_freq))
得到 x_1,它是一个 频域混合出来的新图像。
第二步:像素混合图 x_2
k_2 = gt_keep_mask_2d * omega_t
x_2 = img_forward_2d * k_2 + img_reverse_2d * (1 - k_2)
得到 x_2,是另一个版本的新图像。
第三步:加权融合两个图像 x_1 & x_2
k = 1 - gamma_t * np.exp(-t_c / 1000)
img_re = k * x_1 + (1 - k) * x_2
一个随时间变化的融合系数 k:
-
时间步越小,
k越大 → 更信任x_1(频域精细重建) -
时间步越大,
k越小 → 更信任x_2(空间更平滑)
最终输出 img_re:融合频域重建图像和空间混合图像的结果。
总结
deal_out 和 PFAD_sample 就是双域互补掩码的核心代码:
| 模块 | 作用 | |
|---|---|---|
🔁 PFAD_sample | 扩散逆过程控制流程(判断 mask 轮换、执行 deal_out) | |
🔀 deal_out | 执行“双域融合”:频域和空间域互补 + 掩膜引导 |
dist_util.py
封装了分布式训练中最常用的辅助函数,比如:
-
初始化多GPU环境
-
获取当前 GPU
-
多GPU 同步模型参数
-
从主GPU广播变量
-
多卡下加载模型权重
| 功能 | 函数名 | 用途 |
|---|---|---|
| 初始化通信 | setup_dist() | 构建分布式环境(GPU通信) |
| 设备分配 | dev() | 给当前进程分配对应 GPU |
| 载入模型权重 | load_state_dict() | 避免多卡重复加载模型 |
| 参数同步 | sync_params() | 保证多卡的模型参数完全一致 |
| 通信端口管理 | _find_free_port() | 自动找可用端口做通信 |
👉 分布式训练流程:
-
所有进程并行执行一套相同的训练逻辑;
-
每个 GPU 加载自己的 mini-batch 数据;
-
前向传播 → 损失计算 → 反向传播;
-
PyTorch 自动在多个 GPU 之间 同步梯度(AllReduce);
-
更新模型参数。
代码复现
运用conda+mamba搭建环境实现:
1.配置环境
mamba create -n pfa_test python=3.9 -y
conda activate pfa_test
conda install -c conda-forge simpleitk=2.3.1 libitk=5.3.0 -y验证(pfa_test) D:\B——SR_project\PFAD>conda list | findstr "itk":
libitk 5.3.0 h170c4af_8 conda-forge
simpleitk 2.3.1 py39h99910a6_2 conda-forge安装必要包:
pip install numpy
pip install blobfile
pip install mpi4py
pip install scipy
pip install numpy==1.24.3
pip install tqdm
由于我的电脑是单卡,所以,修改原来的开源代码,禁用分布式训练,修改:PFAD\scripts\guided_diffusion\dist_util.py文件,
测试:
cd scripts
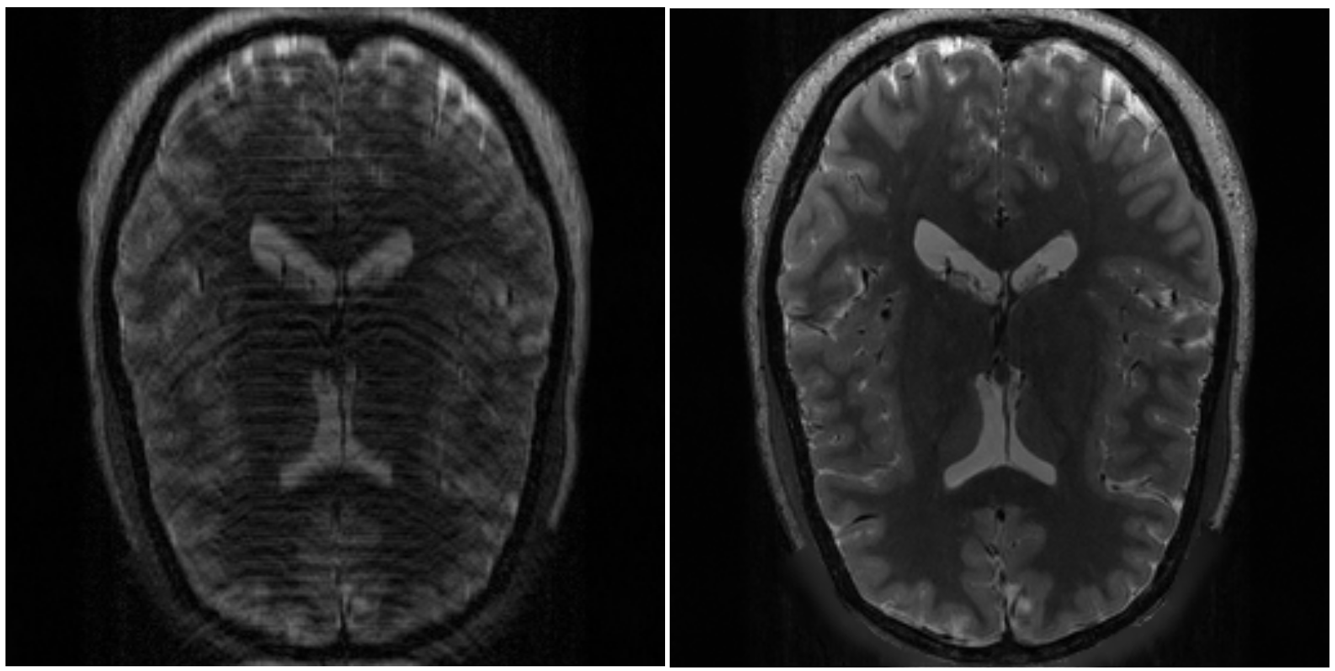
python image_sample.py --conf_path ../conf/brain_sample_config.yml --img_dir brain --save_path motion_remove效果



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









