







论文链接:ECCV 2018 Open Access Repository
Pytorch开源代码:https://github.com/yulunzhang/RCAN
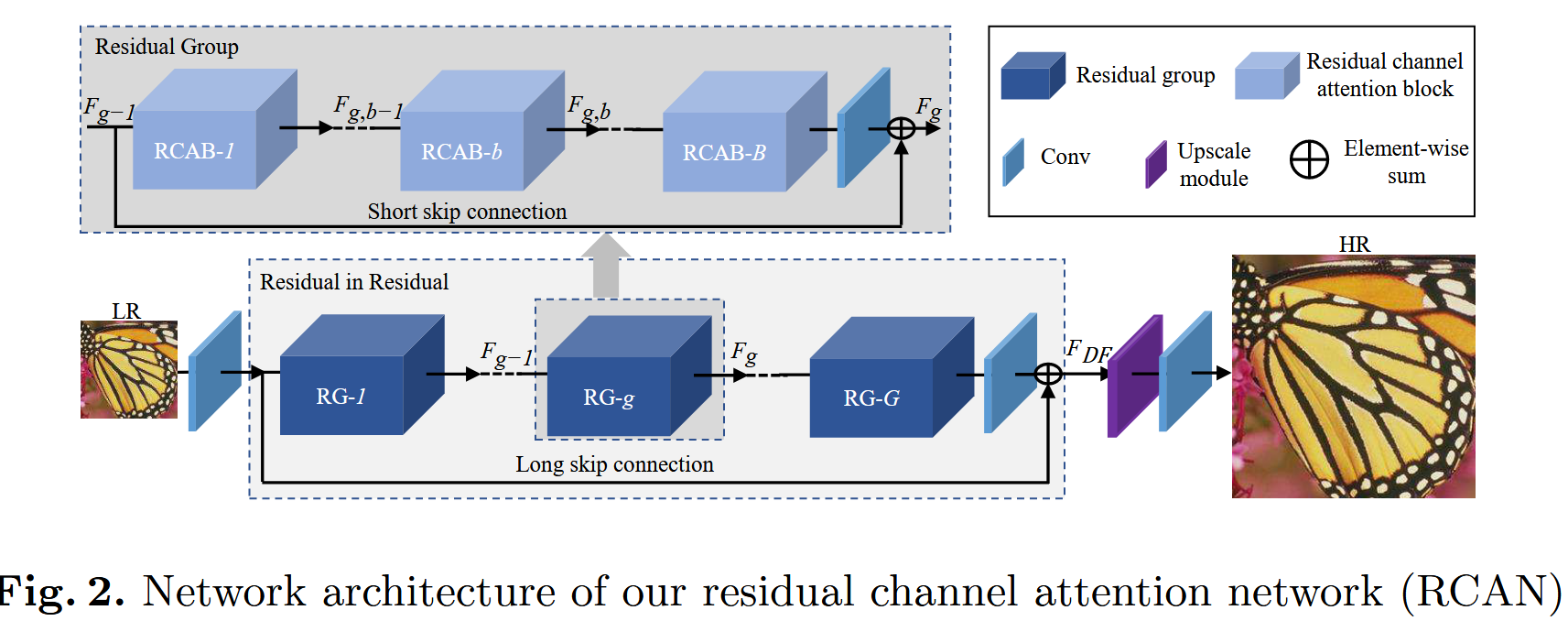
一、网络结构
RACN结构
Input → Shallow Feature Extraction → Residual in Residual (RIR) → Reconstruction → Output
1️⃣ Shallow Feature Extraction:
F0 = H_SF(I_LR)
-
使用一个 3x3 的卷积层对输入低分辨率图像进行特征提取。
-
输出为初始特征图 F0。
2️⃣ Residual in Residual (RIR) Module:
RIR 结构内包含:
-
G 个 Residual Groups(RG)
-
每个 RG 包含 B 个 Residual Channel Attention Blocks(RCAB)
形式化表示:
F = H_RIR(F0) = F0 + H(G1(G2(...(GG(F0))...)))
🔁 2.1 Residual Group (RG):
每个 RG 是一个深度残差块组,它的结构如下:
RG:
Input
↓
RCAB × B(B 个 RCAB 块串联)
↓
Conv (3x3)
↓
+ Skip Connection(将RG的输入加到输出上)
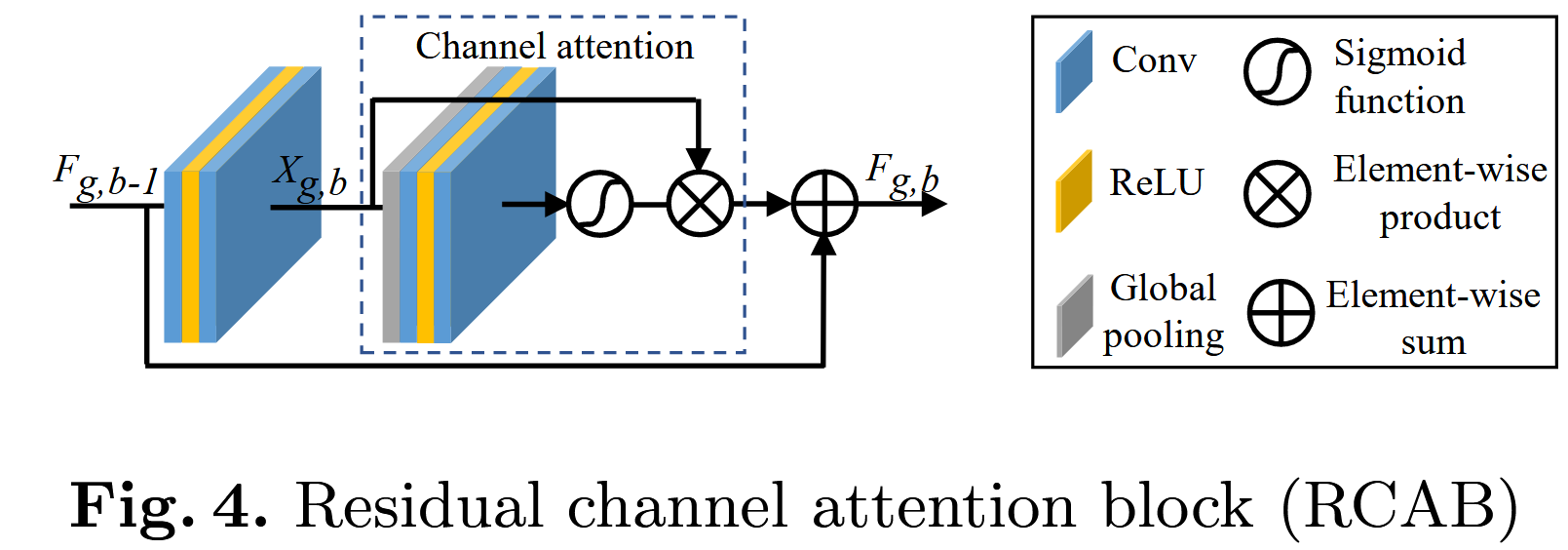
💡 2.2 Residual Channel Attention Block (RCAB):
RCAB 是融合了通道注意力机制的残差块,结构如下:
RCAB:
Input
↓
Conv (3x3) + ReLU + Conv (3x3)
↓
Channel Attention Module (CA)
↓
*(乘以注意力系数)+ Skip Connection
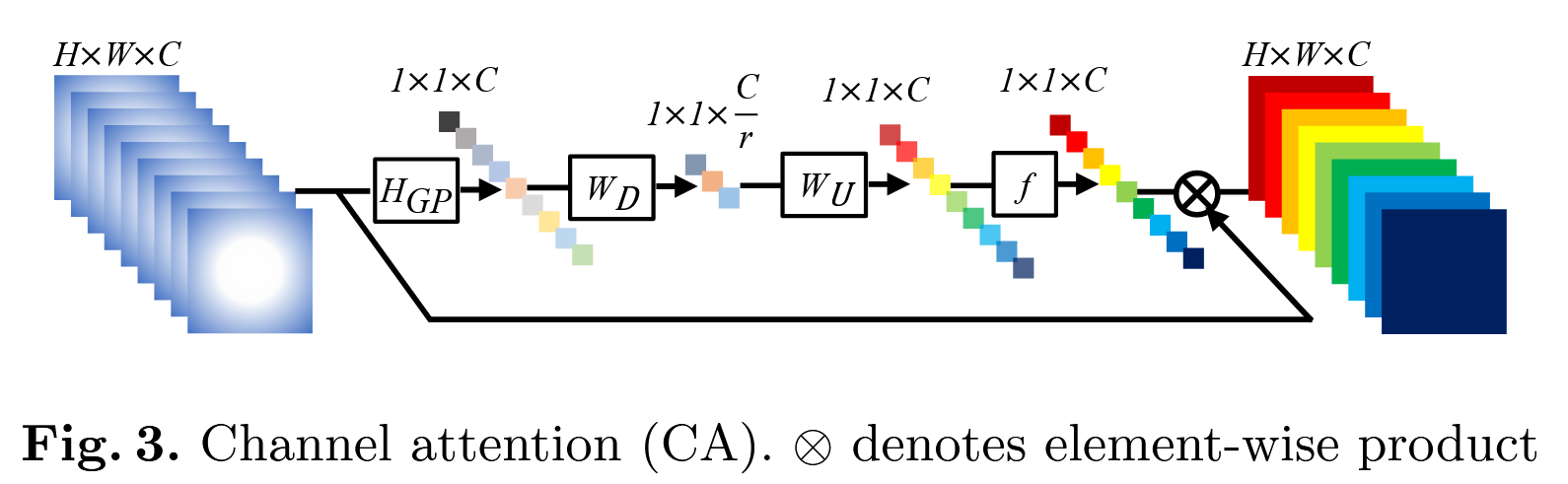
🧠 Channel Attention(通道注意力模块):
主要操作如下:
-
Global Average Pooling(GAP):对每个通道进行全局平均池化。
-
FC → ReLU → FC → Sigmoid:一个两层的MLP,提取通道注意力权重。
-
乘法缩放:用得到的注意力向量对输入特征通道进行逐通道缩放。
公式如下:
CA(F) = σ(W2·ReLU(W1·GAP(F)))
🧠 通道注意力模块的动机:通道注意力就是告诉模型“哪个通道更重要”,让模型重点关注重要的通道,抑制无用信息。
在深度神经网络中,每一层卷积的输出是一个三维张量,形状为:
[Batch_Size, Channels, Height, Width]
传统卷积对所有通道一视同仁。但其实某些通道提取了更重要的特征(比如边缘、纹理),而有些可能是“噪声”。
→ 通道注意力模块的作用就是:给每个通道打一个“权重分数”,让重要的通道更突出。
🔧 RCAN中的通道注意力模块结构(简称 CA 模块)结构:
Input Feature (C x H x W)
↓
Global Average Pooling
↓
C维 → 1维(每个通道得到一个平均值)
↓
全连接 FC1(降维) → ReLU → FC2(升维)
↓
Sigmoid(归一化为权重 0~1)
↓
和原始特征做通道乘法
↓
输出 Attention 加权后的特征图
总结一句话:
通道注意力 = 给每个通道一个重要程度打分 → 保留重要的 → 抑制无关的!
3️⃣ Reconstruction(重建模块):
RCAN 最后使用上采样模块将特征图放大为目标高分辨率图像。
一般使用的是:
-
PixelShuffle(子像素卷积)
-
或者亚像素卷积方式进行上采样
I_SR = H_REC(F) = UpSample(F) → Conv(3x3)
🔁 总体结构层级图示(简化版):
Input
↓
Conv(3x3)
↓
Residual in Residual:
├─ RG1 ─┬─ RCAB1
│ ├─ RCAB2
│ └─ ... RCABB
├─ RG2 ─┬─ ...
└─ ...
↓
UpSample + Conv
↓
Output (I_SR)
🔢 超参数常见设置:
| 模块 | 参数 |
|---|---|
| Residual Groups G | 10 |
| 每组RCAB数 B | 20 |
| 特征维度(channels) | 64 |
| 通道注意力中缩减率 r | 16 |
✨ RCAN 优点总结:
-
很深很深但稳定:采用 Residual-in-Residual 结构,避免梯度消失。
-
细节增强明显:通道注意力模块可以增强关键特征,去除无用信息。
-
SOTA 性能:在多个超分数据集上取得领先表现。
二、开源代码结构
RCAN.py
RCAN 网络结构总览
RCAN 主要由三大部分组成,对应于代码中的模块如下:
输入图像
↓
【Head 模块】(特征提取) → `self.head`
↓
【Body 模块】(残差组堆叠) → `self.body`
↓
【Tail 模块】(上采样输出) → `self.tail`
↓
输出高分辨图像
其中 Body 模块是核心部分,它由多个 Residual Group 组成,每个 Residual Group 中又嵌套多个 RCAB(残差通道注意力块)。
RCAN.py 添加详细注释版
from model import common
import torch.nn as nn
# 创建模型的入口函数
def make_model(args, parent=False):
return RCAN(args)
# ========================================================
# 模块 1: 通道注意力层(Channel Attention Layer)
# 功能:用于捕捉“通道维度”上的重要性,增强特征表达
# 对应论文中的 CA Layer 模块
# ========================================================
class CALayer(nn.Module):
def __init__(self, channel, reduction=16):
super(CALayer, self).__init__()
# 自适应池化,将特征图变成通道维度的描述子(形状: B×C×1×1)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_du = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True), # 降维
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True), # 升维
nn.Sigmoid() # 输出权重 [0, 1]
)
def forward(self, x):
y = self.avg_pool(x) # B×C×1×1
y = self.conv_du(y) # 经过 FC(1×1卷积)生成通道注意力权重
return x * y # 对原始特征做加权(通道注意力)
# ========================================================
# 模块 2: 残差通道注意力块(RCAB)
# 功能:基本构建单元,融合残差连接 + 通道注意力
# 对应论文中的 Residual Channel Attention Block
# ========================================================
class RCAB(nn.Module):
def __init__(self, conv, n_feat, kernel_size, reduction,
bias=True, bn=False, act=nn.ReLU(True), res_scale=1):
super(RCAB, self).__init__()
modules_body = []
# 2 个卷积层 + ReLU 激活
for i in range(2):
modules_body.append(conv(n_feat, n_feat, kernel_size, bias=bias))
if bn:
modules_body.append(nn.BatchNorm2d(n_feat))
if i == 0:
modules_body.append(act)
# 通道注意力
modules_body.append(CALayer(n_feat, reduction))
self.body = nn.Sequential(*modules_body)
self.res_scale = res_scale # 残差缩放(默认=1)
def forward(self, x):
res = self.body(x)
res += x # 残差连接
return res
# ========================================================
# 模块 3: 残差组(Residual Group)
# 功能:多个RCAB串联 + 一个跳连接
# 对应论文中的 Residual Group(RG)
# ========================================================
class ResidualGroup(nn.Module):
def __init__(self, conv, n_feat, kernel_size, reduction, act, res_scale, n_resblocks):
super(ResidualGroup, self).__init__()
# n_resblocks 个 RCAB 块
modules_body = [
RCAB(conv, n_feat, kernel_size, reduction, bias=True, bn=False, act=act, res_scale=res_scale)
for _ in range(n_resblocks)
]
# 加一个卷积层用于整体残差连接
modules_body.append(conv(n_feat, n_feat, kernel_size))
self.body = nn.Sequential(*modules_body)
def forward(self, x):
res = self.body(x)
res += x # 残差连接
return res
# ========================================================
# 模块 4: RCAN 主体
# 包括 Head(输入提特征)+ Body(残差组)+ Tail(上采样)
# ========================================================
class RCAN(nn.Module):
def __init__(self, args, conv=common.default_conv):
super(RCAN, self).__init__()
# 参数设定
n_resgroups = args.n_resgroups # 残差组数量(通常 10)
n_resblocks = args.n_resblocks # 每组内 RCAB 数量(通常 20)
n_feats = args.n_feats # 特征图通道数(通常 64)
kernel_size = 3
reduction = args.reduction # 通道注意力中的 reduction(通常 16)
scale = args.scale[0] # 放大倍数(2, 3, 4)
act = nn.ReLU(True)
# 数据归一化(减去数据集均值)
if args.data_train == 'DIV2K':
print('Use DIV2K mean (0.4488, 0.4371, 0.4040)')
rgb_mean = (0.4488, 0.4371, 0.4040)
elif args.data_train == 'DIVFlickr2K':
print('Use DIVFlickr2K mean (0.4690, 0.4490, 0.4036)')
rgb_mean = (0.4690, 0.4490, 0.4036)
rgb_std = (1.0, 1.0, 1.0)
self.sub_mean = common.MeanShift(args.rgb_range, rgb_mean, rgb_std)
# 【Head模块】:一个卷积层提取初始特征
modules_head = [conv(args.n_colors, n_feats, kernel_size)]
# 【Body模块】:多个 ResidualGroup + 一个卷积
modules_body = [
ResidualGroup(conv, n_feats, kernel_size, reduction, act=act, res_scale=args.res_scale, n_resblocks=n_resblocks)
for _ in range(n_resgroups)
]
modules_body.append(conv(n_feats, n_feats, kernel_size))
# 【Tail模块】:上采样模块 + 输出图像
modules_tail = [
common.Upsampler(conv, scale, n_feats, act=False),
conv(n_feats, args.n_colors, kernel_size)
]
self.add_mean = common.MeanShift(args.rgb_range, rgb_mean, rgb_std, 1)
# 封装为 Sequential 模块
self.head = nn.Sequential(*modules_head)
self.body = nn.Sequential(*modules_body)
self.tail = nn.Sequential(*modules_tail)
def forward(self, x):
x = self.sub_mean(x) # 减去均值(归一化)
x = self.head(x) # Head 特征提取
res = self.body(x) # Body 处理(多个残差组)
res += x # 长距离残差连接
x = self.tail(res) # 上采样恢复图像
x = self.add_mean(x) # 加回均值
return x
# 加载预训练权重
def load_state_dict(self, state_dict, strict=False):
own_state = self.state_dict()
for name, param in state_dict.items():
if name in own_state:
if isinstance(param, nn.Parameter):
param = param.data
try:
own_state[name].copy_(param)
except Exception:
if name.find('tail') >= 0:
print('Replace pre-trained upsampler to new one...')
else:
raise RuntimeError(...)
elif strict:
if name.find('tail') == -1:
raise KeyError(...)
if strict:
missing = set(own_state.keys()) - set(state_dict.keys())
if len(missing) > 0:
raise KeyError(...)
📌 总结
| 模块名 | 功能 | 论文中结构 |
|---|---|---|
CALayer | 通道注意力 | Channel Attention |
RCAB | 残差+注意力块 | Residual Channel Attention Block |
ResidualGroup | 一组RCAB | Residual Group |
RCAN | 总体网络 | 整体框架 |
common.py
这段代码定义了一个用于图像超分辨率任务的神经网络模块库,包含基础卷积模块、残差块、上采样模块,以及引入注意力机制的改进模块。
🔧 工具函数
def default_conv(in_channels, out_channels, kernel_size, bias=True):
return nn.Conv2d(
in_channels, out_channels, kernel_size,
padding=(kernel_size//2), bias=bias)
默认卷积层,自动补零使输出尺寸一致。
🌈 MeanShift 模块
class MeanShift(nn.Conv2d):
-
用于图像归一化和反归一化的变换。
-
输入输出通道数为3,使用单位矩阵作为权重。
-
sign=-1表示去均值;sign=+1表示加回均值(常在训练前后使用)。
🧱 BasicBlock(基础块)
class BasicBlock(nn.Sequential):
-
卷积 + BN + 激活(ReLU)组合,可选用。
-
结构类似 VGG 风格。
🔁 ResBlock(残差块)
class ResBlock(nn.Module):
-
结构为 Conv -> Act -> Conv + 残差连接。
-
可配置是否使用 BN。
-
res_scale控制残差缩放因子,适用于深层网络稳定训练。
📈 Upsampler(上采样模块)
class Upsampler(nn.Sequential):
-
利用 PixelShuffle 进行图像分辨率提升。
-
支持 2 的幂次和 3 倍上采样(例如 ×2, ×4, ×8 或 ×3)。
🔍 SELayer(通道注意力机制)
class SELayer(nn.Module):
-
基于 Squeeze-and-Excitation(SE)结构。
-
全局平均池化 → 两层1x1卷积 → Sigmoid。
-
输出通道注意力权重,用于重新加权特征图。
🧠 SEResBlock(带 SE 的残差块)
class SEResBlock(nn.Module):
-
在普通
ResBlock基础上添加 SE 模块。 -
SELayer被放在两个卷积之后。 -
可提升模型对重要特征的关注度,提升重建质量。
trainer.py
import os
import math
from decimal import Decimal
import utility # 工具函数模块(如定时器、保存图像、计算PSNR等)
import torch
from torch.autograd import Variable
from tqdm import tqdm # 用于训练和测试中的进度条显示
# Trainer 类是 RCAN 模型训练和测试的核心结构
class Trainer():
def __init__(self, args, loader, my_model, my_loss, ckp):
# 初始化训练器:传入配置参数、数据加载器、模型、损失函数、日志记录器
self.args = args
self.scale = args.scale # 放大倍数(可能是列表)
self.ckp = ckp # 日志与检查点记录
self.loader_train = loader.loader_train # 训练数据加载器
self.loader_test = loader.loader_test # 测试数据加载器
self.model = my_model # RCAN 模型
self.loss = my_loss # 损失函数组合
self.optimizer = utility.make_optimizer(args, self.model) # 优化器
self.scheduler = utility.make_scheduler(args, self.optimizer) # 学习率调度器
# 如果加载已训练模型,恢复优化器状态和调度器进度
if self.args.load != '.':
self.optimizer.load_state_dict(
torch.load(os.path.join(ckp.dir, 'optimizer.pt'))
)
for _ in range(len(ckp.log)):
self.scheduler.step()
self.error_last = 1e8 # 上一轮的误差,用于跳过损失异常的 batch
# 训练过程
def train(self):
self.scheduler.step() # 学习率更新
self.loss.step() # 损失记录初始化
epoch = self.scheduler.last_epoch + 1
lr = self.scheduler.get_lr()[0]
# 写入当前 epoch 的日志
self.ckp.write_log(
'[Epoch {}]\tLearning rate: {:.2e}'.format(epoch, Decimal(lr))
)
self.loss.start_log()
self.model.train()
timer_data, timer_model = utility.timer(), utility.timer()
# 开始每一个 batch 的训练
for batch, (lr, hr, _, idx_scale) in enumerate(self.loader_train):
lr, hr = self.prepare([lr, hr]) # 将低分辨率、高分辨率数据转到设备
timer_data.hold() # 记录数据加载时间
timer_model.tic() # 模型运行时间开始计时
self.optimizer.zero_grad()
sr = self.model(lr, idx_scale) # 前向传播,得到超分图像
loss = self.loss(sr, hr) # 计算损失
# 如果损失太大,说明该 batch 可能异常,跳过
if loss.item() < self.args.skip_threshold * self.error_last:
loss.backward() # 反向传播
self.optimizer.step() # 更新参数
else:
print('Skip this batch {}! (Loss: {})'.format(
batch + 1, loss.item()
))
timer_model.hold()
# 每 print_every 个 batch 输出一次日志
if (batch + 1) % self.args.print_every == 0:
self.ckp.write_log('[{}/{}]\t{}\t{:.1f}+{:.1f}s'.format(
(batch + 1) * self.args.batch_size,
len(self.loader_train.dataset),
self.loss.display_loss(batch), # 显示当前损失
timer_model.release(),
timer_data.release()))
timer_data.tic()
self.loss.end_log(len(self.loader_train)) # 记录当前 epoch 的平均损失
self.error_last = self.loss.log[-1, -1] # 保存当前最后损失值
# 测试过程
def test(self):
epoch = self.scheduler.last_epoch + 1
self.ckp.write_log('\nEvaluation:')
self.ckp.add_log(torch.zeros(1, len(self.scale))) # 初始化 log 表
self.model.eval()
timer_test = utility.timer()
with torch.no_grad():
for idx_scale, scale in enumerate(self.scale):
eval_acc = 0
self.loader_test.dataset.set_scale(idx_scale)
tqdm_test = tqdm(self.loader_test, ncols=80)
for idx_img, (lr, hr, filename, _) in enumerate(tqdm_test):
filename = filename[0]
no_eval = (hr.nelement() == 1) # 是否存在高分辨率图像
if not no_eval:
lr, hr = self.prepare([lr, hr])
else:
lr = self.prepare([lr])[0]
sr = self.model(lr, idx_scale)
sr = utility.quantize(sr, self.args.rgb_range) # 限制输出值范围
save_list = [sr]
if not no_eval:
eval_acc += utility.calc_psnr(
sr, hr, scale, self.args.rgb_range,
benchmark=self.loader_test.dataset.benchmark
)
save_list.extend([lr, hr])
# 保存预测结果(可选)
if self.args.save_results:
self.ckp.save_results_nopostfix(filename, save_list, scale)
self.ckp.log[-1, idx_scale] = eval_acc / len(self.loader_test)
best = self.ckp.log.max(0)
self.ckp.write_log(
'[{} x{}]\tPSNR: {:.3f} (Best: {:.3f} @epoch {})'.format(
self.args.data_test,
scale,
self.ckp.log[-1, idx_scale],
best[0][idx_scale],
best[1][idx_scale] + 1
)
)
self.ckp.write_log(
'Total time: {:.2f}s, ave time: {:.2f}s\n'.format(timer_test.toc(), timer_test.toc()/len(self.loader_test)), refresh=True
)
if not self.args.test_only:
self.ckp.save(self, epoch, is_best=(best[1][0] + 1 == epoch)) # 保存模型
# 将张量准备好放入模型(转到设备、精度处理)
def prepare(self, l, volatile=False):
device = torch.device('cpu' if self.args.cpu else 'cuda')
def _prepare(tensor):
if self.args.precision == 'half': tensor = tensor.half()
return tensor.to(device)
return [_prepare(_l) for _l in l]
# 判断是否终止训练
def terminate(self):
if self.args.test_only:
self.test()
return True
else:
epoch = self.scheduler.last_epoch + 1
return epoch >= self.args.epochs
🌟RCAN 训练流程总结(基于 trainer.py):
🏗 1. 初始化阶段 __init__
-
读取参数(如学习率、batch_size、放大倍数等)。
-
加载训练和测试数据集(
loader_train,loader_test)。 -
加载模型
my_model和损失函数my_loss。 -
创建优化器(Adam)和学习率调度器(StepLR)。
-
如果设置了
args.load,则尝试加载之前训练好的优化器状态。
🏋️♀️ 2. 训练阶段 train()
每一轮 epoch 的训练过程如下:
-
更新学习率:
self.scheduler.step() -
准备模型进入训练模式:
self.model.train() -
遍历训练数据(一个 epoch 中所有 batch):
-
拿到每个 batch 的数据:低分辨率图像
lr和高分辨率图像hr。 -
将图像转到设备(CPU 或 GPU)上。
-
清空梯度:
optimizer.zero_grad() -
前向传播:生成超分图像
sr = model(lr) -
计算损失:与
hr计算 loss。 -
若损失过大(异常),则跳过该 batch。
-
否则进行 反向传播 + 优化器更新参数。
-
每隔一定步数打印一次当前损失和耗时信息。
-
-
记录当前 epoch 的平均损失,更新
self.error_last。
🧪 3. 测试阶段 test()
每训练一个 epoch 后或在 test_only 模式下:
-
设置模型为评估模式:
model.eval()。 -
遍历所有测试图像,进行:
-
图像推理(前向传播)得到
sr。 -
计算 PSNR(Peak Signal-to-Noise Ratio)评价指标。
-
如果设置了
save_results,还会保存推理图像。
-
-
打印当前 epoch 在每个放大倍数下的 PSNR 结果。
-
保存最佳模型(PSNR 最好的那次)。
🛑 4. 判断是否终止训练 terminate()
-
若设置
--test_only,训练前直接测试并终止。 -
否则判断当前 epoch 是否达到
args.epochs,达到则终止训练。
🔁 总体训练循环(外部调用逻辑):
训练主循环大概如下:
while not trainer.terminate():
trainer.train()
trainer.test()
✅ 总结一句话
RCAN 的训练过程是一个经典的 PyTorch 深度学习训练框架结构:
准备 → 前向传播 → 损失计算 → 反向传播 → 更新参数 → 测试评估 → 日志保存 → 下一轮
三、损失函数/优化算法
| 项目 | 默认设置 |
|---|---|
| 🎯 损失函数 | L1 Loss(Mean Absolute Error) |
| 🧠 可选扩展 | 感知损失(vgg)、对抗损失(adversarial) |
| ⚙️ 优化器 | Adam |
| 📉 学习率调度 | StepLR(每隔一定 epoch 衰减) |
四、创新点
- RIR结构:通过多层次跳跃连接实现极深网络训练,同时分离低频与高频信息处理。
- 通道注意力:动态调整通道权重,提升特征表示能力。
- 端到端优化:联合RIR与注意力机制,实现高效超分辨率重建。


















 2080
2080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









