








太极AngelPTM数据并行训练策略优化-Part1
| 导言 近期鹅厂“混元”多模态大模型在全球最具权威的MSR-VTT,MSVD,LSMDC,DiDeMo和ActivityNet五大跨模态视频检索数据集榜单中,先后拿下第一名的成绩,实现了该领域的大满贯[1]。随后“混元”NLP大模型在CLUE(中文语言理解评测集合)榜单中又刷新了总榜、分类榜、阅读理解榜和KgCLUE的最好成绩[2,3],实现了跨模态检索和自然语言理解的双佳绩!
“混元”AI大模型基于腾讯太极机器学习平台进行研发,借助GPU算力,实现快速的算法迭代和模型训练,本文将介绍腾讯太极机器学习平台助力“混元”AI大模型的训练框架——AngelPTM。
太极AngelPTM系列文章分Part 1和Part 2两部分,Part 1介绍本文的背景、太极AngelPTM概览和太极AngelPTM训练框架优化策略中的数据并行和模型并行部分,Part 2介绍太极AngelPTM训练框架优化策略中的MoE组件性能优化策略和混合并行策略,实验效果以及总结与展望。
背景
Transformer模型凭借其出色的表达能力在多个人工智能领域,如自然语言处理、计算机视觉和语音处理等均取得了巨大成功,吸引了工业界和学术界许多研究人员的兴趣。随着预训练技术的兴起,研究人员发现Transformer灵活可堆叠的结构可以方便的配置模型规模,而数据量和模型规模的增加可以提高Transformer模型的表现质量[4],
因此,近几年,Transformer系列模型的参数量快速从十亿[5]增长到了千亿[6],随后借助于稀疏门控混合专家 (Mixture-of-experts, MoE)组件,在不显著影响模型训练性能的前提下一年之内已经把模型规模推增到万亿[7]乃至十万亿[8],目前各大AI公司都已卷入到大模型训练的“军备竞赛”中。
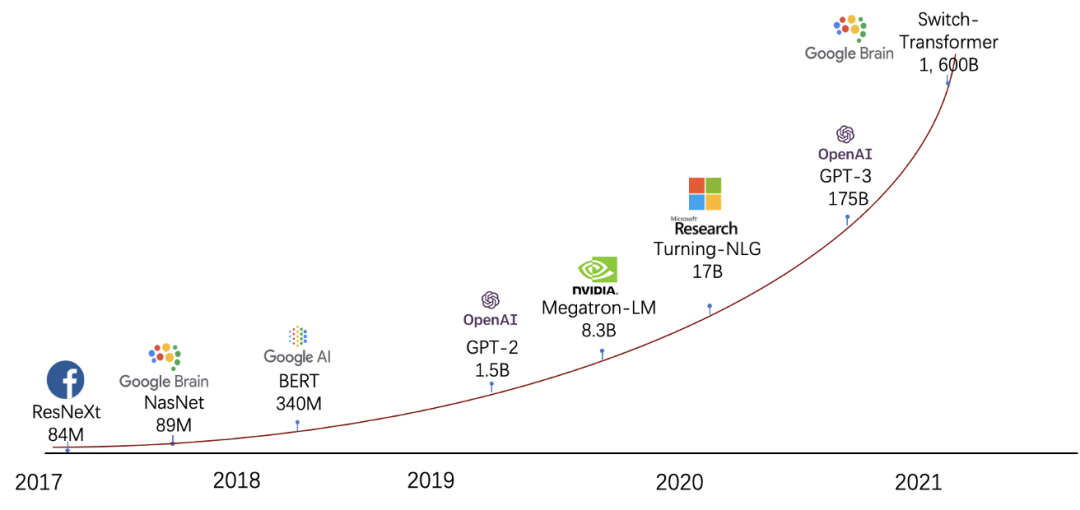
图1 模型规模随时间变化的趋势
相对于指数增长的模型规模,近几年高性能计算设备的存储却增长有限,以英伟达GPU为例,最新的Ampere A100 80G显存相对于4年前Tesla V100 32G显存仅提升1倍多,而模型规模已经扩大了几千~十万倍,如何高效地利用有限显存支持大模型训练成为当前训练框架的挑战之一。

图2 GPU显存容量随时间变化趋势
业界适用于大模型分布式训练且具有代表性的框架主要有DeepSpeed[9]和Megatron-LM[10]。其中,DeepSpeed框架通过ZeRO(Zero Redundancy Optimizer)技术[11]优化数据并行训练中参数、梯度、优化器状态等冗余显存占用,显著提升存储受限场景下训练可支持的模型规模,还借助CPU/NVMe Offload特性进一步将支持的模型规模实现数量级的提升;而Megatron-LM针对Transformer结构定制优化的张量并行[12]作为节省存储和提升性能的标配组件被业界广泛使用,并辅助以数据并行和流水并行,实现高效的3D并行能力[13]。
然而,上述框架对大规模分布式训练的支持强依赖于高速网络集群,比较典型的有SuperPod集群——单节点配置200Gbps*8网卡(带宽1.6Tbps)并配套IB网络。但是高速网络因其高昂的建设成本,远未实现普及,目前国内企业绝大部分网络环境仍然以100Gbps*1网卡(带宽100Gbps)配套RoCE网络为主。常规网络环境也给大模型训练带来了极大的挑战,更限制了对通信效率要求极高的MoE组件的应用。因此,在DeepSpeed和Megatron-LM框架之上建设适配常规网络的高性能大模型训练能力非常必要,太极AngelPTM在此背景下应运而生。
太极AngelPTM概览
太极AngelPTM的设计目标是依托太极机器学习平台,为NLP、CV和多模态等多类预训练任务提供一站式服务。其主要由训练框架、应用框架和平台前端构成:
-
训练框架:含基础框架、模型组件和模型仓库,提供常见模型组网和分布式训练能力,产出预训练模型。
-
应用框架:含预训练下游任务组件及配套的精调、推理和蒸馏等应用工具。
-
交互界面:太极机器学习平台用户界面,构建一站式工作流服务。
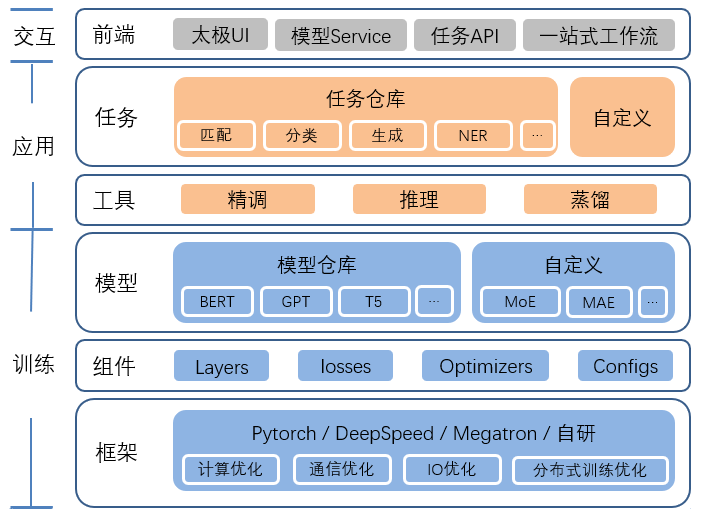
图3 太极AngelPTM概览
本文作为太极AngelPTM系列文章首篇,以训练框架为主对AngelPTM的分布式训练能力进行介绍。
太极AngelPTM训练框架结合四种主流的分布式并行策略,包括ZeRO赋能的数据并行,张量并行,流水并行以及专家并行,并支持以上策略的任意组合。通过分析用户模型的负载,并结合多种并行策略的优势,太极AngelPTM产出高效的分布式训练解决方案,将模型训练任务(包括计算,通信和存储)分配到大规模GPU集群进行处理,取得了业界领先的内存利用率和训练吞吐效率。同时,AngelPTM直击MoE模型在层次网络环境下的痛点,提出了一系列定制性的优化方案,取得了优异的性能。
太极AngelPTM训练框架优化策略
在模型规模比较大,导致单GPU卡无法装载训练所需存储时,常用策略是使用节点内张量并行和节点间数据并行(2D并行)进行训练。虽然张量并行可以用单节点8卡显存去装载训练所需存储,但过大的模型使得每卡也仅能剩余少量的显存供训练使用,从而训练的批量大小仅能设置为很小的值,吞吐极低。因此,需要引入较多的节点,通过数据并行去提高并发度。然而,随着数据并行度增大,集合通信的有效带宽又随之减小,加上梯度规约操作的参数量极大,会明显影响模型训练的效率。
下图实验使用10个8卡A100节点对GPT2 13B模型2D并行训练评测发现,单步迭代耗时高达约12.5s,其中梯度归约步骤耗时约11.4秒,占总耗时比例达到惊人的92%。并且因模型规模较大,即便加上了重计算策略,批量大小最大也只能设置到2。
表1 GPT2 13B模型80 GPUs单步迭代耗时分析

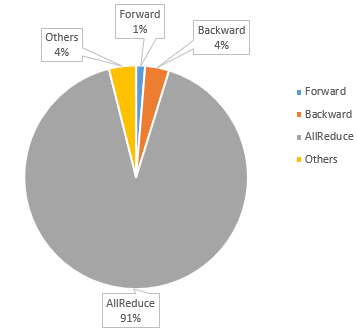
图4 GPT2 13B模型训练单步迭代时间分布
进一步,在常规网络环境下评测AllReduce集合通信在不同GPU卡规模下的通信效率发现,随着GPU卡数增多,通信效率会随之下降。
表2 常规网络环境AllReduce集合通信效率

由此可见,常规网络环境带宽偏低的问题会引发通信瓶颈,限制了模型训练的效率,使得A100 GPU强悍的算力难以充分发挥,造成了极大的资源浪费。因此,需要对这个问题进行针对性的优化。
数据并行训练策略优化
梯度累积
对于数据并行训练模式而言(包含2D并行中数据并行部分),梯度累积是比较常用的性能优化策略,该策略利用样本 i.i.d.特性将多步迭代积累的大批量样本生成的梯度累加后进行通信,从而减少通信频次,提升训练效率。但为了避免梯度累积的批量太大引入精度损失,一般不会设置过大的累积迭代步长。于是还需要从减少通信量的维度进一步优化。
PowerSGD
减少通信量的经典策略是做梯度压缩,比如DGC选择当前梯度中前k个显著的值通信[14],1-bit Adam将梯度进行1 bit量化后通信[15],PowerSGD对梯度进行低秩矩阵分解后通信[16]。DGC对精度损失比较大,且不适用于Adam系列的具有二阶统计量的优化器;1-bit Adam对梯度的压缩率最大只能到全精度训练的1/32,对带宽节省比较有限;而PowerSGD可以通过调整压缩率实现通信效率和训练精度上的平衡,在实践中更为适用。
PowerSGD算法思路可以借助下图的SVD矩阵分解进行理解,即将梯度矩阵根据用户指定的R值分解(压缩)为两个更小量级的矩阵U和V后跨rank进行AllReduce通信,再把通信后的结果恢复回梯度矩阵(解压缩)。该算法相对DGC和1-bit Adam有两个亮点:
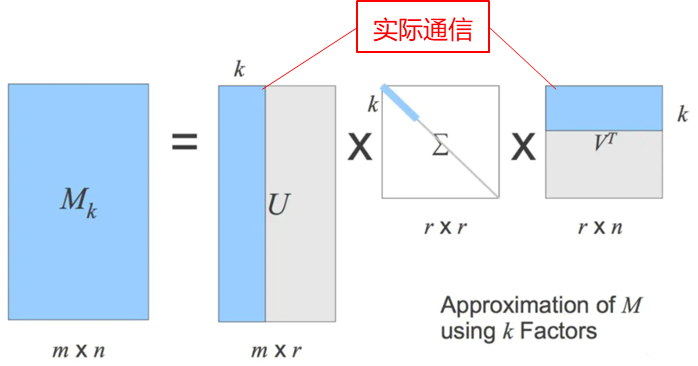
图5 PowerSGD算法原理示意图
-
矩阵分解是线性的,集合通信过程直接加和不会影响梯度的重建,对原通信逻辑的入侵很小,可以最大程度复用数据并行的训练和通信步骤。
-
该压缩过程虽然有损,但用户可以借助R值调整压缩损失。以MxN矩阵压缩为MxR和RxN两个矩阵为例,压缩率如下式所示。其中R值越大,损失越小,通信量越大;反之,R值越小,损失越大,通信量越小。
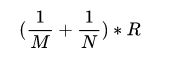
具体实现中,PowerSGD使用子空间迭代算法power iteration替代SVD分解以确保计算效率,具体算法细节请参考[16]。
相对于常规数据并行的梯度规约通信,PowerSGD额外有两次矩阵乘和一次斯密特正交化运算,并多了一次AllReduce通信,因此,只要PowerSGD算法压缩通信量减少的延时比额外计算和通信引入的延时大,那么使用该算法就能取得训练性能上的收益。文章[22]首次将PowerSGD算法引入到腾讯社交和广告等业务模型训练中,并且在常规网络环境下基于大规模数据并行训练取得了显著的性能收益。
共享解锁参数训练
需要注意的是,在使用Adam优化器训练时,Adam里梯度的二阶统计量对梯度变化比较敏感,如果在该统计量数值稳定前就使用PowerSGD策略训练,会影响训练的收敛性。因此,PowerSGD策略会设置热启动步数,一般建议为训练总步数的10%,即在这个步数内,不执行压缩通信。所以还得继续优化这10%步数内的训练性能,毕竟大模型训练动辄几亿样本的数据集,10%样本数也有几千万规模。
得益于Transformer模型重复的子图结构,除了梯度压缩外,还有一种便捷的减少通信量的办法——共享子图参数训练。Transformer结构里的N层参数(N>20)全部共享第1层参数启动训练,如下图左所示。共享参数模型的总参数量为非共享版本的1/N,从而梯度通信量也相应缩减为1/N,极大地提升了训练效率,可以作为PowerSGD热启动训练组件使用。待训练到PowerSGD期望的热启动步数或者等Adam二阶统计量稳定以后再通过参数解锁工具,把第1层参数及Adam统计量拷贝到各层中,热启动PowerSGD继续训练。
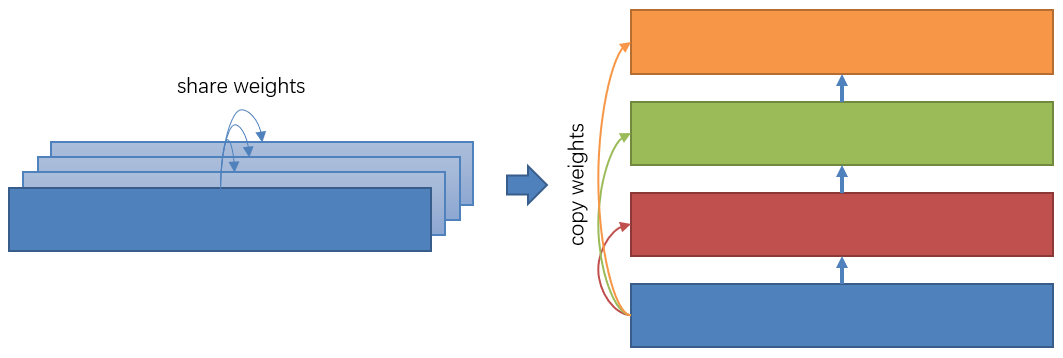
图6 共享解锁参数训练示意图
模型并行
在数据并行中,每个GPU都需要保存完整的模型状态(包括参数,梯度以及优化器状态,如Adam),如40GB的A100最大只能存下2.5B模型的模型状态。使得最大可训练的模型只跟单GPU的显存有关,而与集群中的GPU数量无关。为了支持万亿大模型的训练,AngelPTM引入了模型并行的相关技术将模型分散存储到多个GPU上,包括ZeRO赋能的数据并行,流水并行,张量并行和专家并行。
ZeRO赋能的数据并行
为了消除数据并行中的冗余存储,微软DeepSpeed团队提出了零冗余优化器(The Zero Redundancy Optimizer,简称ZeRO),将模型状态分区存储到多个GPU。当一个参数需要使用的时候,ZeRO利用通信来收集其他GPU所存储的该参数相关部分。ZeRO优化共分为3个级别,1)对优化器状态进行分区;2)对参数的梯度进行分区;3)对参数进行分区。级别越高,显存节省越多,同时带来的额外通信也就越多。
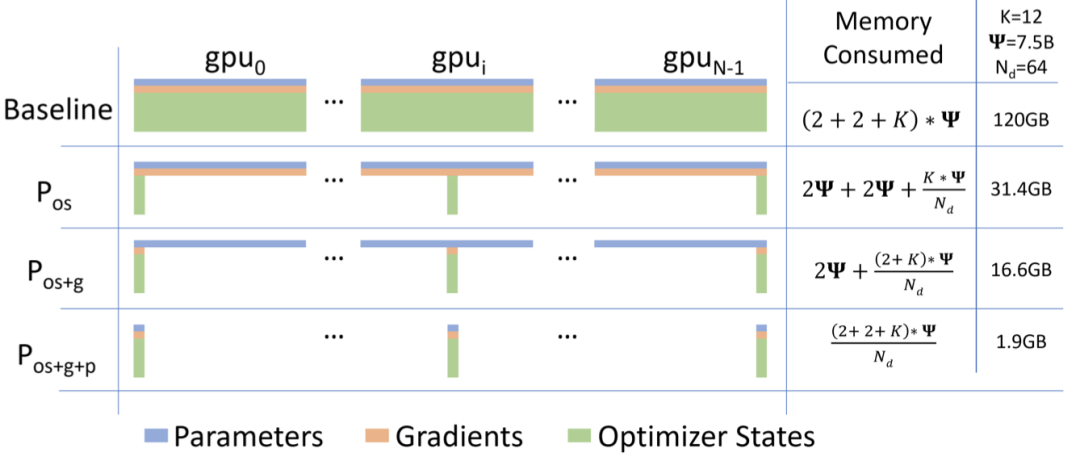
图7 零冗余优化器(ZeRO)工作原理示意图
流水并行
在流水并行中,不同层被放置到不同的GPU上进行计算,如图(a)所示,将模型的4层计算分配给4个设备进行计算。由于不同层之间有计算的依赖关系(如F1的输入是F0的输出),因此同时只能有1个设备在工作,如图(b)所示。GPipe通过切分输入数据为多个micro-batch,来重叠不同设备上计算过程,减少Bubble Time,如图(b)所示。在训练时,Bubble time占比如公式所示,其中N为GPU数量,M为切分的micro batch数量。从存储角度,所有GPU共同保存了一份模型状态,其冗余存储为切分处的数据,如图中F0的输出既要保存在Device 0上也要保存在Device 1上。从通信角度,GPU之间需要通信模型切分处的中间结果(正向阶段)及其梯度(反向阶段)。
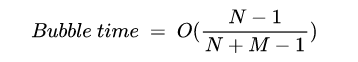
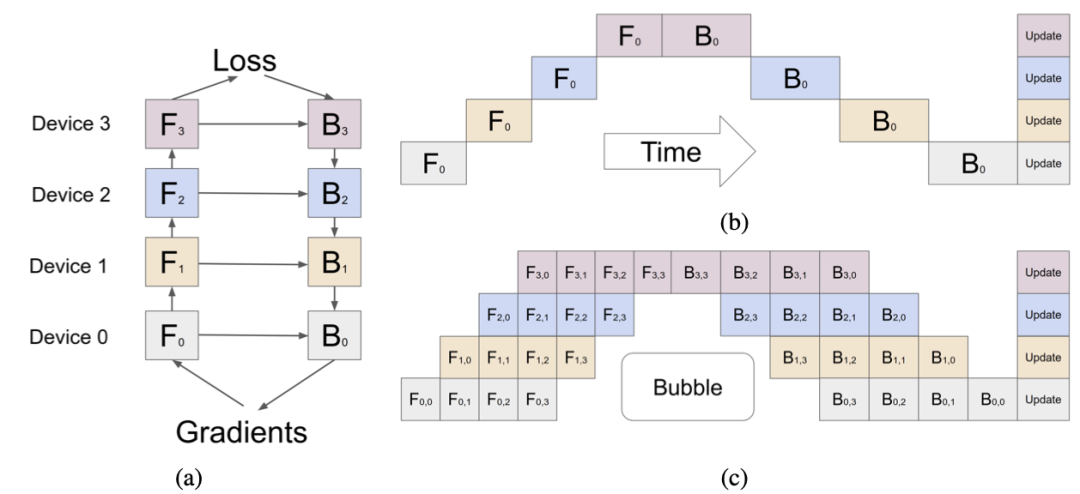
图8 流水并行工作原理示意图
张量并行
Transformer的主要结构是Self-Attention网络和FFN网络(2层MLP结构)。Megatron-LM提出了张量并行的方式,将模型中的连续两个GEMMs操作切分到多个GPU进行操作。如图所示,考虑到减少模型切分引入的额外通信量,Megatron-LM将第一个GEMM按照列进行切分,第二个GEMM按照行进行切分,这样多个GPU仅需要进行一次AllReduce通信便可得到输出结果Z。具体来说,在FFN网络中,两个Linear层组成了连续的两个GEMMs操作;在Self-Attention网络中,Attention层和Post-attention Linear层组成了连续的两个GEMMs操作。
从存储角度,所有GPU共同保存了一份模型状态,由于张量并行的每个模型分片都需要拿到该层的输入数据进行计算,所以其冗余存储为额外的输入数据。从通信角度,GPU之间需要通信模型切分处的中间结果(正向阶段)及其梯度(反向阶段)。从计算角度,每个GPU执行的Layer计算变小了,可能会导致GPU Kernel计算资源不能打满。
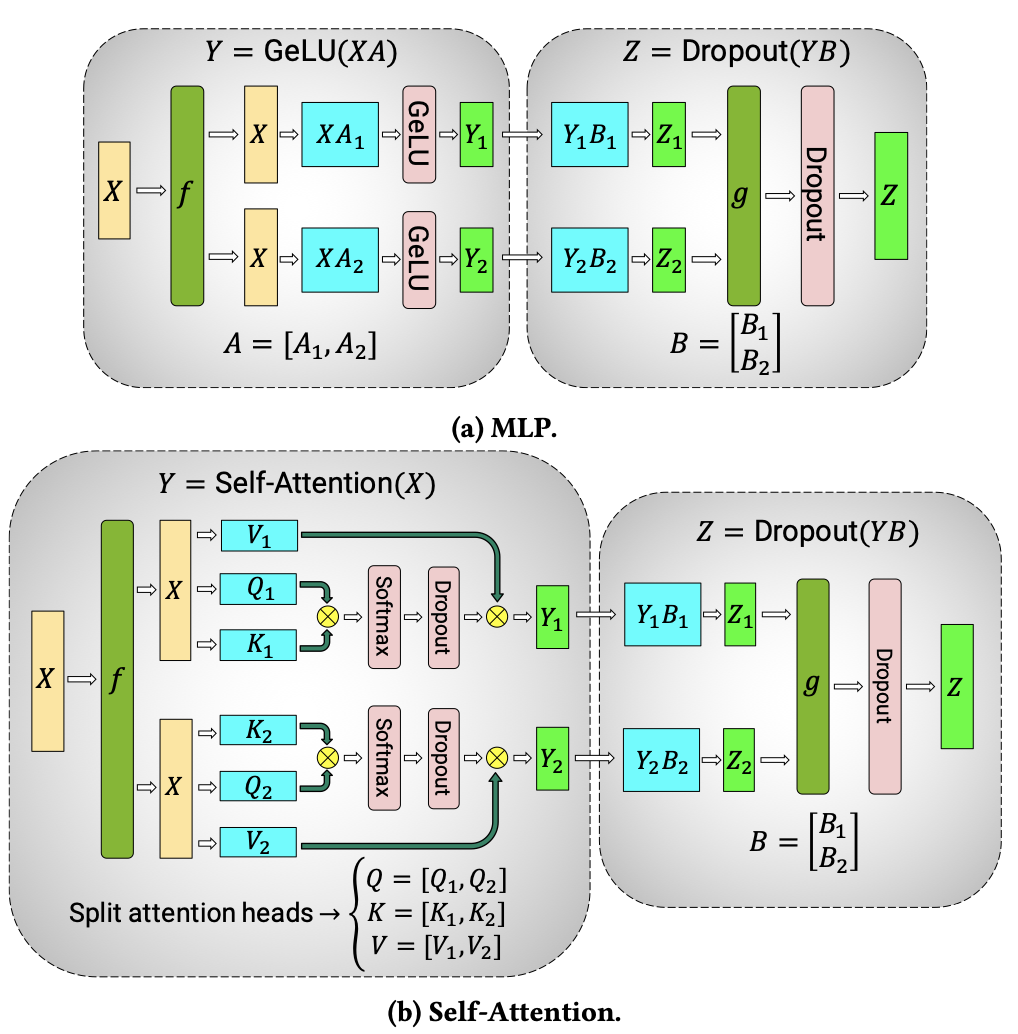
图9 张量并行示意图
专家并行
在混合专家模型中,MoE由多个专家子网络(Expert)和一个门控网络(Gate)组成,输入数据由Gate来决定激活哪个专家子网络。GShard[19]提出专家并行,将专家网络切分到多个GPU共同维护,其他层仍采用数据并行的方式。如图所示,共有E个设备和E个专家子网络(FFN1, ..., FFNE),每个专家子网络只在其对应的设备上存储(第i个FFN存储在第i个Device上),非专家网络存储在每个Device上。当输入数据由Gate决定激活另一个设备上的Expert时,便会进行一次远端通信,由于每个设备上的数据都要分给所有的Expert,所以引入了AllToAll通信。
从存储角度,所有GPU共同维护了一个MoE层,但非MoE层存储在每个GPU上,因此冗余存储是非MoE层的模型状态。从通信角度,GPU之间需要进行非MoE层的AllReduce通信以及MoE层的AllToAll通信。
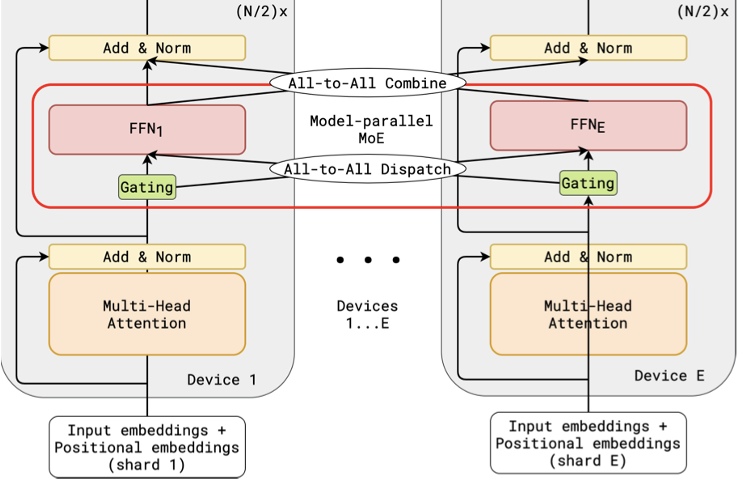
图10 专家并行示意图
北京大学-腾讯协同创新实验室
北京大学-腾讯协同创新实验室成立于2017年,主要在人工智能、大数据等领域展开前沿探索和人才培养,打造国际领先的校企合作科研平台和产学研用基地。实验室通过合作研究,在理论和技术创新、系统研发和产业应用方面取得重要成果和进展,如分布式机器学习平台Angel,已在国际顶级学术会议和期刊发表学术论文20余篇。
AngelPTM由腾讯和北京大学河图团队共同设计开发完成。北大河图团队来自北京大学-腾讯协同创新实验室主任崔斌教授课题组,自主研发了分布式深度学习系统河图(Hetu[20],https://github.com/PKU-DAIR/Hetu),面向拥有海量训练数据、超大模型参数的深度学习训练场景,并具备通用、高效、敏捷、灵活和可扩展等特性。AngelPTM集成了多项北大河图团队在大规模预训练模型的系统优化方面的工作,兼顾学术界的创新性和工业界的可用性。
此前,河图团队还参与了腾讯稀疏大模型训练框架HEAP及新一代大模型参数服务器 AngelPS的前瞻研究[21]和系统建设工作,推动河图创新成果在腾讯实际业务中的应用落地,促进产学研合作和成果转化。
参考文献
-
腾讯“混元”AI大模型登顶CLUE三大榜单,打破多项行业记录
-
Brown T, Mann B, Ryder N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
-
Alec R, Jeff W, Rewon C, et al. Language Models are Unsupervised Multitask Learners. OpenAI blog, 1(8):9, 2019.
-
Shaden S, Mostofa P, Brandon N, et al. Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model. arXiv:2201.11990
-
Fedus W, Zoph B, Shazeer N, et al. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arXiv:2101.03961.
-
Lin J, Yang A, Bai J, et al. M6-10T: A Sharing-Delinking Paradigm for Efficient Multi-Trillion Parameter Pretraining. arXiv:2110.03888
-
GitHub - microsoft/DeepSpeed: DeepSpeed is a deep learning optimization library that makes distributed training and inference easy, efficient, and effective.
-
GitHub - NVIDIA/Megatron-LM: Ongoing research training transformer models at scale
-
Samyam R, Jeff R, Olatunji R, et al. ZeRO: Memory Optimizations Toward Training Trillion Parameter Models. SC 2020.
-
Shoeybi M, Patwary M, Puri R, et al. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053. 2019.
-
Narayanan D, Shoeybi M, Casper J, et al. Efficient large-scale language model training on GPU clusters using megatron-LM. SC 2021.
-
Lin Y, Han S, Mao H, Wang Y, Dally WJ. Deep gradient compression: Reducing the communication bandwidth for distributed training. arXiv preprint arXiv:1712.01887.
-
LLin Y, Han S, Mao H, Wang Y, Dally WJ. Deep gradient compression: Reducing the communication bandwidth for distributed training. arXiv preprint arXiv:1712.01887.
-
Tang H, Gan S, Awan AA, et al. 1-bit adam: Communication efficient large-scale training with adam’s convergence speed. ICML 2021.
-
Vogels T, Karimireddy SP, Jaggi M. PowerSGD: Practical low-rank gradient compression for distributed optimization. NIPS 2019.
-
Nie X, Zhao P, Miao X, et al. HetuMoE: An Efficient Trillion-scale Mixture-of-Expert Distributed Training System[J]. arXiv preprint arXiv:2203.14685, 2022.
-
Lepikhin D, Lee H J, Xu Y, et al. Gshard: Scaling giant models with conditional computation and automatic sharding[J]. arXiv preprint arXiv:2006.16668, 2020.
-
“使用PowerSGD算法解决大模型训练中的通信瓶颈”
大模型预训练相关技术讨论
欢迎随时联系我:callbackliu@tencent.com
系列文章“Part2”后续接着发布
记得关注我们,及时接收精彩内容哦~















 1613
1613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









