






注意力机制理解及代码:
理解:

因此,每个q向量都会对应一个v向量,同时,不同的评分函数对于注意力权重有不同的影响。
缩放点积注意力:

参考链接:10.3. 注意力评分函数 — 动手学深度学习 2.0.0 documentation
注意,这种评分函数要求q和k拥有相同的长度d,对于小批量(有了批量,向量dim=3),给出公式如上。
对于点积可以衡量向量相似度的理解:向量点积越大,方向越接近,一定程度上刻画了两个向量的相似度。
代码:
import math
import torch
from torch import nn
from d2l import torch as d2l
#掩码softmax,用于指定有效序列长度
def masked_softmax(X, valid_lens):
"""通过在最后一个轴上掩蔽元素来执行softmax操作"""
# X:3D张量(batch_size,sequence_length,embedding_dim),valid_lens:1D或2D张量
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape
if valid_lens.dim() == 1:
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
'''repeat_interleave(input:tensor,repeats:int or tensor, dim)用于指定维度上重复张量中的元素,将有效长度扩充到句子长度'''
else:
valid_lens = valid_lens.reshape(-1)
# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0
X = d2l.sequence_mask(X.reshape(-1, shape[-1]), valid_lens,
value=-1e6)
return nn.functional.softmax(X.reshape(shape), dim=-1)
class DotProductAttention(nn.Module):
"""缩放点积注意力"""
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# queries的形状:(batch_size,查询的个数,d)
# keys的形状:(batch_size,“键-值”对的个数,d)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
# valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
# 设置transpose_b=True为了交换keys的最后两个维度
#torch.bmm()用于批量矩阵相乘,transpose对矩阵K转置
scores = torch.bmm(queries, keys.transpose(1,2)) / math.sqrt(d) #注意力分数
self.attention_weights = masked_softmax(scores, valid_lens)
# 由于矩阵乘法的性质,可以用torch.bmm()进行注意力公式最后的加权求和
return torch.bmm(self.dropout(self.attention_weights), values)
自注意力与位置编码
自注意力:
对self-attention而言,q和k的维度相同,事实上,在transformer中,Q,K,V都相同
代码:
from d2l import torch as d2l
num_hiddens, num_heads = 10, 5
'''class MultiHeadAttention(nn.Module): # 多头注意力
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
'''主要看forward函数'''
def forward(self, queries, keys, values, valid_lens):
# Shape of `queries`, `keys`, or `values`:
# (`batch_size`, no. of queries or key-value pairs, `num_hiddens`)
# Shape of `valid_lens`:
# (`batch_size`,) or (`batch_size`, no. of queries)
# After transposing, shape of output `queries`, `keys`, or `values`:
# (`batch_size` * `num_heads`, no. of queries or key-value pairs,
# `num_hiddens` / `num_heads`)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
if valid_lens is not None:
# On axis 0, copy the first item (scalar or vector) for
# `num_heads` times, then copy the next item, and so on
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)
# Shape of `output`: (`batch_size` * `num_heads`, no. of queries,
# `num_hiddens` / `num_heads`)
output = self.attention(queries, keys, values, valid_lens)
# Shape of `output_concat`:
# (`batch_size`, no. of queries, `num_hiddens`)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)
'''
attention = d2l.MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,
num_hiddens, num_heads, 0.5)
attention.eval()
batch_size, num_queries, valid_lens = 2, 4, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
print(attention(X, X, X, valid_lens).shape) #torch.size([2,4,10])
print(X)
print(X.shape) # torch.size([2,4,10])位置编码:
在自然语言处理(NLP)中,绝对位置(Absolute Position)和相对位置(Relative Position)通常用来描述序列中不同元素之间的位置关系。
绝对位置是指序列中每个元素的具体位置,通常通过元素在序列中的索引或位置来表示。
相对位置是指序列中不同元素之间的相对距离或位置关系。相对位置通常以相对于某个参考元素的距离来表示。例如,在一个句子中,一个单词相对于另一个单词的位置可以用距离来表示,例如距离为1表示紧邻相邻,距离为2表示间隔一个单词,依此类推。相对位置可以更好地捕捉序列中元素之间的上下文关系和依赖关系。
以下为transformer中所使用的位置编码方法:

其中所蕴含的绝对位置信息:这种编码方式使得编码维度频率逐渐降低,而编码维度单调降低的频率与绝对位置信息的关系是,维度越高,频率越低,与这种三角函数编码方式相吻合。
相对位置信息:利用三角函数周期性的性质,如下公式可以证明其中蕴含相对位置信息。
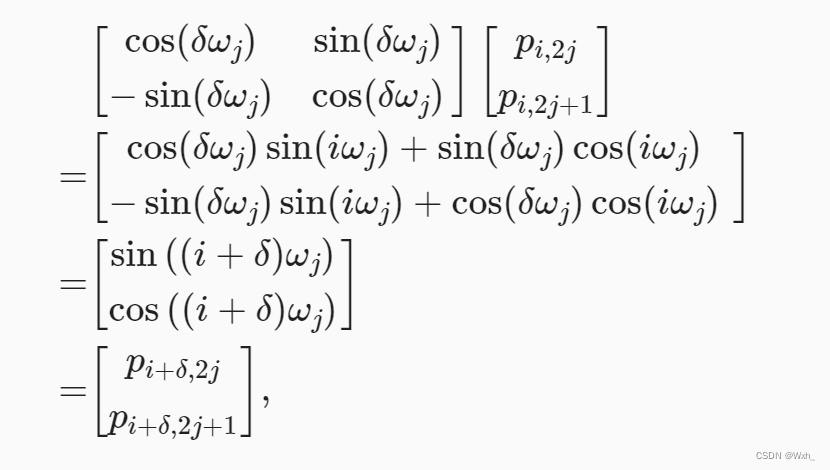
其中,为任意位置i的偏移量。可以看到,投影矩阵与i无关,只与
有关。
代码:
class PositionalEncoding(nn.Module):
"""位置编码"""
def __init__(self, num_hiddens, dropout, max_len=1000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(dropout)
# 创建一个足够长的P,用来存放编码矩阵
self.P = torch.zeros((1, max_len, num_hiddens))
#利用torch.pow()计算幂次方以及广播机制,计算位置编码矩阵中的数值
X = torch.arange(max_len, dtype=torch.float32).reshape(
-1, 1) / torch.pow(10000, torch.arange(
0, num_hiddens, 2, dtype=torch.float32) / num_hiddens)
#维度方向上,从0开始,每隔两个位置取一个,也就是奇数位
self.P[:, :, 0::2] = torch.sin(X)
self.P[:, :, 1::2] = torch.cos(X)
def forward(self, X):
X = X + self.P[:, :X.shape[1], :].to(X.device)
return self.dropout(X)














 684
684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









