






目录
-----------Yolov系列源码网站-GitCode-----------
yolov4:https://gitcode.net/mirrors/Onicc/YoloV4_Insulators?utm_source=csdn_github_accelerator
yolov5: https://github.com/ultralytics/yolov5/tree/v5.0
yolov6:https://gitcode.net/mirrors/meituan/YOLOv6?utm_source=csdn_github_accelerator
yolov7:https://gitcode.net/mirrors/WongKinYiu/yolov7?utm_source=csdn_github_accelerator
--------------持续更新中---------------
了解一下参数
--img:设置训练图像大小。
--batch:设置训练批次大小。
--epochs:设置训练的epoch数。
--data:指定数据集的配置文件,包括训练集、验证集、类别等信息。
--cfg:指定YOLOv5模型的配置文件,包括网络结构、超参数等信息。
--weights:设置预训练模型的路径,如果不使用预训练模型,则设为空。
--name:设置训练结果的保存路径和名称。
★★★♥★★
一、模型训练
【适用于Yolov5所有分支版本】
下面代码(注意img、batch、epochs、data、cfg、weight必须根据自己的情况进行修改即可)
1、★初次训练
常用代码
python train.py --img 640 --batch 4 --epochs 500 --data data/blemish.yaml --cfg models/yolov5s_blemish.yaml --weights weights/yolov5s.pt --name results --cache 2、★恢复训练
假如上次一共需要训练500轮,结果训练到400轮中断了,用该命令恢复训练
使用上次的last.pt权重文件,(上次训练时,最后一轮的权重)。【关键词:--resume】
python train.py --img 640 --batch 4 --epochs 500 --data data/blemish.yaml --cfg models/yolov5s_blemish.yaml --weights runs/train/exp/weights/last.pt --name results --cache --resume
使用上次的best.pt权重文件,建议选这个(上次训练时,所有轮中最好的一次权重)。
python train.py --img 640 --batch 4 --epochs 500 --data data/blemish.yaml --cfg models/yolov5s_blemish.yaml --weights runs/train/exp/weights/best.pt --name results --cache --resume3、★继续训练
假如上次一共需要训练500轮,结果也训练了500轮,此基础上再继续训练200轮
使用如下命令【关键词:--cache】
python train.py --img 640 --batch 4 --epochs 200 --data data/blemish.yaml --cfg models/yolov5s.yaml --weights runs\train\weights\best.pt --name results4 --cache★★★★★★
二、模型预测
1、★预测命令
python detect.py --source test_images/ --weights runs/train/a1/weights/best.pt --conf 0.5
test_images/ 是测试集图像的路径;
runs/train/a1/weights/best.pt 是训练过程中保存的最佳模型权重文件路径;
--conf 0.25 是设置预测置信度阈值为0.25 ;
★★★★★★
三、Yolov7
1、★训练指令
python train.py --workers 2 --device 0 --batch-size 4 --data data/coco128.yaml --cfg cfg/training/yolov7.yaml --weights yolov7.pt --name yolov7 --hyp data/hyp.scratch.p5.yaml --epochs 200
遇到的问题
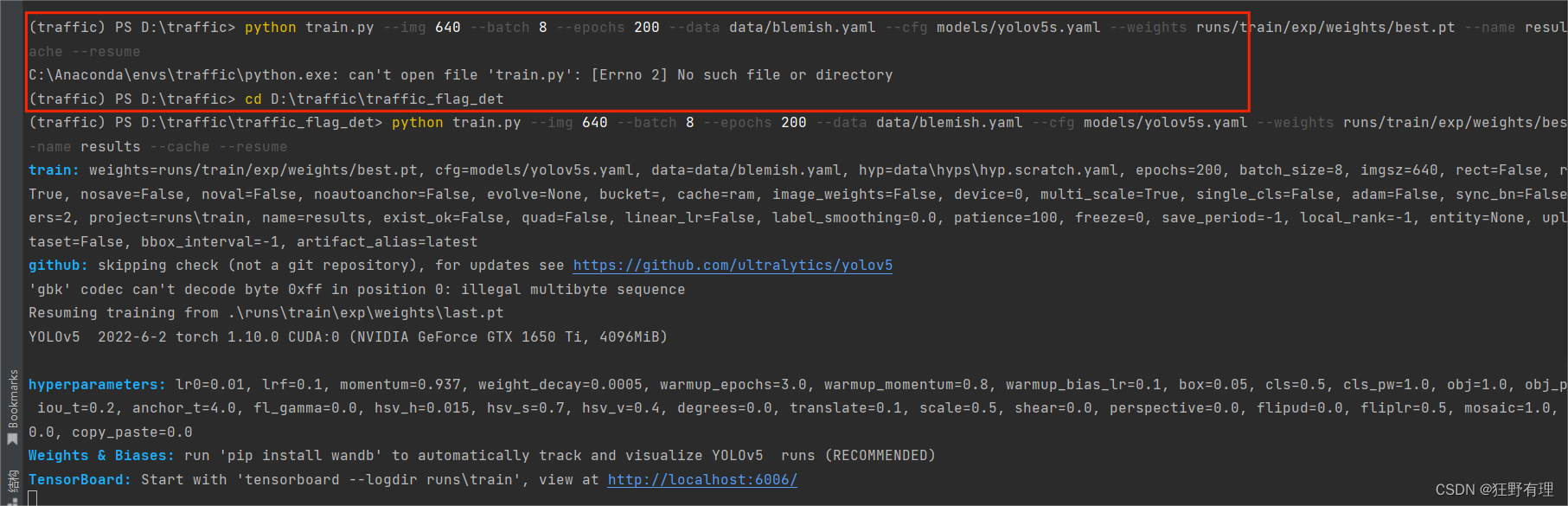
【C:\Anaconda\envs\traffic\python.exe: can't open file 'train.py': [Errno 2] No such file or directory】
原因是未进入当前目录,需要cd一下
(traffic) PS D:\traffic> python train.py --img 640 --batch 8 --epochs 200 --data data/blemish.yaml --cfg models/yolov5s.yaml --weights runs/train/exp/weights/best.pt --name results --cache --resume
C:\Anaconda\envs\traffic\python.exe: can't open file 'train.py': [Errno 2] No such file or directory
(traffic) PS D:\traffic> cd D:\traffic\traffic_flag_det
(traffic) PS D:\traffic\traffic_flag_det> python train.py --img 640 --batch 8 --epochs 200 --data data/blemish.yaml --cfg models/yolov5s.yaml --weights runs/train/exp/weights/best.pt --name results --cache --resume
 ★★★★★★
★★★★★★
四、Yolov5代码注释理解
★Yolov5★
1、train.py文件(部分)
import argparse # 解析命令行参数的库
import math # 数学函数库
import os # 处理文件和目录的库
import random # 随机数生成库
import subprocess # 子进程管理库
import sys # 系统相关库
import time # 时间相关库
from copy import deepcopy # 深度复制库
from datetime import datetime # 时间日期库
from pathlib import Path # 处理文件路径的库
import numpy as np # 处理数值数组的库
import torch # PyTorch 深度学习框架
import torch.distributed as dist # 分布式训练库
import torch.nn as nn # PyTorch 模型库
import yaml # 处理 YAML 格式文件的库
from torch.optim import lr_scheduler # PyTorch 优化器库
from tqdm import tqdm # 显示进度条的库
# 获取当前 train.py 脚本文件的路径,然后获取其父目录作为 YOLOv5 根目录
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
# 导入 YOLOv5 中的 val.py 文件中定义的 validate() 函数
import val as validate # for end-of-epoch mAP
# 导入 YOLOv5 中的 models 目录下的相关类和函数
from models.experimental import attempt_load
from models.yolo import Model
# 导入 YOLOv5 中的 utils 目录下的相关类和函数
from utils.autoanchor import check_anchors
from utils.autobatch import check_train_batch_size
from utils.callbacks import Callbacks
from utils.dataloaders import create_dataloader
from utils.downloads import attempt_download, is_url
from utils.general import (LOGGER, TQDM_BAR_FORMAT, check_amp, check_dataset, check_file, check_git_info,
check_git_status, check_img_size, check_requirements, check_suffix, check_yaml, colorstr,
get_latest_run, increment_path, init_seeds, intersect_dicts, labels_to_class_weights,
labels_to_image_weights, methods, one_cycle, print_args, print_mutation, strip_optimizer,
yaml_save)
from utils.loggers import Loggers
from utils.loggers.comet.comet_utils import check_comet_resume
from utils.loss import ComputeLoss
from utils.metrics import fitness
from utils.plots import plot_evolve
from utils.torch_utils import (EarlyStopping, ModelEMA, de_parallel, select_device, smart_DDP, smart
2、train.py文件中的部分参数
lr0: #初始学习率,通常使用的优化器如SGD的初始学习率为1e-2,而Adam的初始学习率为1e-3。
lrf: #OneCycleLR策略中的最终学习率,为初始学习率lr0乘以lrf。
momentum: #SGD优化器的动量参数/Adam优化器的beta1参数,用于加速收敛过程。
weight_decay: #优化器的权重衰减参数,用于减小模型复杂度,避免过拟合。
warmup_epochs: #训练过程中的预热期,即在正式训练前一定周期内逐渐增加学习率。
warmup_momentum: #预热期内的初始动量参数。
warmup_bias_lr: #预热期内的初始偏置学习率。
box: #bounding box回归损失的权重。
cls: #物体分类损失的权重。
cls_pw: #BCELoss中正样本的权重。
obj: #目标存在性损失的权重,即objectness损失。
obj_pw: #BCELoss中正样本的权重。
iou_t: #训练中用于计算目标存在性损失的IoU阈值。
anchor_t: #用于过滤anchor boxes的IoU阈值。
fl_gamma: #focal loss中的gamma参数。
hsv_h: #HSV颜色空间中的hue增强参数。
hsv_s: #HSV颜色空间中的saturation增强参数。
hsv_v: #HSV颜色空间中的value增强参数。
degrees: #图像旋转的角度范围。
translate: #图像平移的范围。
scale: #图像缩放的范围。
shear: #图像剪切的角度范围。
perspective: #透视变换的参数。
flipud: #上下翻转的概率。
fliplr: #左右翻转的概率。
mosaic: #图像融合的概率。
mixup: #图像混合的概率。
copy_paste: #图像分割中的复制粘贴的概率。
3、train.py文件【训练中参数解释】
# 每个参数解释
Epoch: #当前模型的训练轮数/总训练轮数。
gpu_mem: #当前模型在GPU上的显存占用量,以GB为单位。
box: #当前模型的bounding box loss(边界框损失)。
obj: #当前模型的objectness loss(物体存在性损失)。
cls: #当前模型的classification loss(分类损失)。
labels: #当前batch(一批次)中标记为有物体的图像数量。
img_size:#当前batch中输入图像的大小。
#下面是评估模型表现的输出结果:
Class: #检测到的目标类别(此处是所有类别)。
Images: #测试集中包含此类别的图像数量。
Labels: #测试集中此类别的ground-truth(真实)标签数量。
P: #此类别的平均精度(Precision)。
R: #此类别的平均召回率(Recall)。
mAP@.5: #IOU阈值为0.5时的平均精度(mean Average Precision)。
mAP: #所有IOU阈值下的平均精度。
五、问题总结
yolov5-----6.0版本
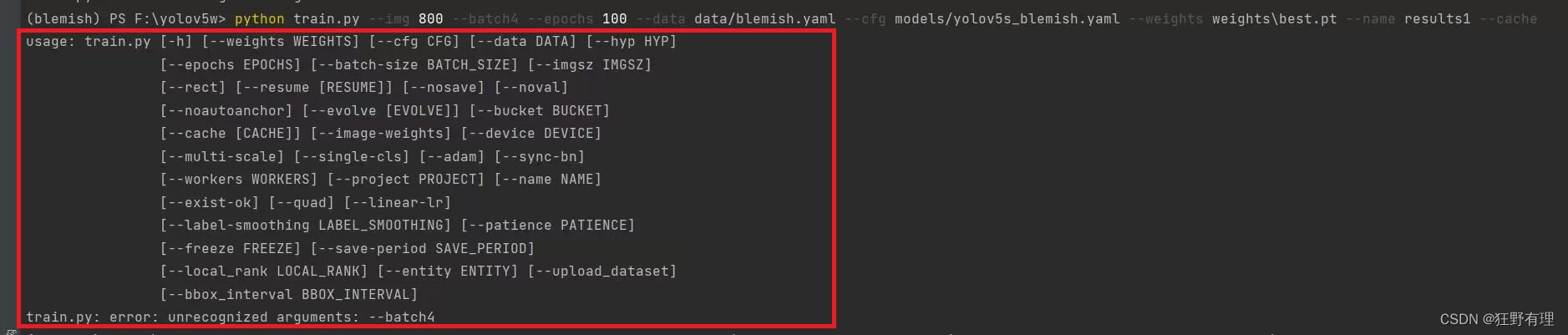
【错误:train.py: error: unrecognized arguments: --batch4】
(blemish) PS F:\yolov5w> python train.py --img 640 --batch4 --epochs 100 --data dataemish.yaml --cfg models/yolov5s_blemish.yaml --weights weights\best.pt --name results1 --cache
usage: train.py [-h] [--weights WEIGHTS] [--cfg CFG] [--data DATA] [--hyp HYP]
[--epochs EPOCHS] [--batch-size BATCH_SIZE] [--imgsz IMGSZ]
[--rect] [--resume [RESUME]] [--nosave] [--noval]
[--noautoanchor] [--evolve [EVOLVE]] [--bucket BUCKET]
[--cache [CACHE]] [--image-weights] [--device DEVICE]
[--multi-scale] [--single-cls] [--adam] [--sync-bn]
[--workers WORKERS] [--project PROJECT] [--name NAME]
[--exist-ok] [--quad] [--linear-lr]
[--label-smoothing LABEL_SMOOTHING] [--patience PATIENCE]
[--freeze FREEZE] [--save-period SAVE_PERIOD]
[--local_rank LOCAL_RANK] [--entity ENTITY] [--upload_dataset]
[--bbox_interval BBOX_INTERVAL]
[--artifact_alias ARTIFACT_ALIAS]
train.py: error: unrecognized arguments: --batch4
解决:
【1】
python train.py --img 640 --batch-size 4 --epochs 100 --data data/blemish.yaml --cfg models/yolov5s_blemish.yaml --weights weights/best.pt --name results1 --cache
【2】
python train.py --img 640 --batch 4 --epochs 100 --data data/blemish.yaml --cfg models/yolov5s_blemish.yaml --weights weights/best.pt --name results1 --cache















 3670
3670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









