







ControlNet的目的是为了提高大型预训练文本到图像扩散模型的空间控制能力。以下是对ControlNetl论文的翻译,以及我的理解:
1.ControlNet的目的:
ControlNet旨在为大型预训练的文本到图像扩散模型添加空间条件控制。这种控制允许用户通过额外的图像(例如边缘图、人体姿态骨架等)直接指定他们想要的图像组成。这解决了仅通过文本提示来精确表达复杂布局、姿态、形状和形式的难题,因为这些复杂的空间组成仅通过文本提示来控制是具有挑战性的。
2.ControlNet的架构设计:
ControlNet通过使用“零卷积”连接到预训练模型的编码层,这些卷积层的权重初始化为零,并在训练过程中逐渐调整。这种设计保留了预训练模型的质量和能力,同时允许在训练过程中不损害模型。
ControlNet的架构设计巧妙地利用了零卷积层来渐进式地调整模型参数,这样做既保护了预训练模型的已有知识,又允许新条件的逐渐学习。这种方法避免了从头开始训练一个全新的模型,同时减少了过拟合的风险,因为它没有完全放开整个预训练模型的参数进行更新。
ControlNet的设计不仅提高了模型的灵活性,还考虑到了实际应用中的效率问题。通过在不同大小的数据集上进行训练,ControlNet证明了其方法的实用性和适应性。此外,ControlNet的可扩展性意味着它可以应用于各种规模的项目,从而为图像生成领域提供了一个强大的工具。
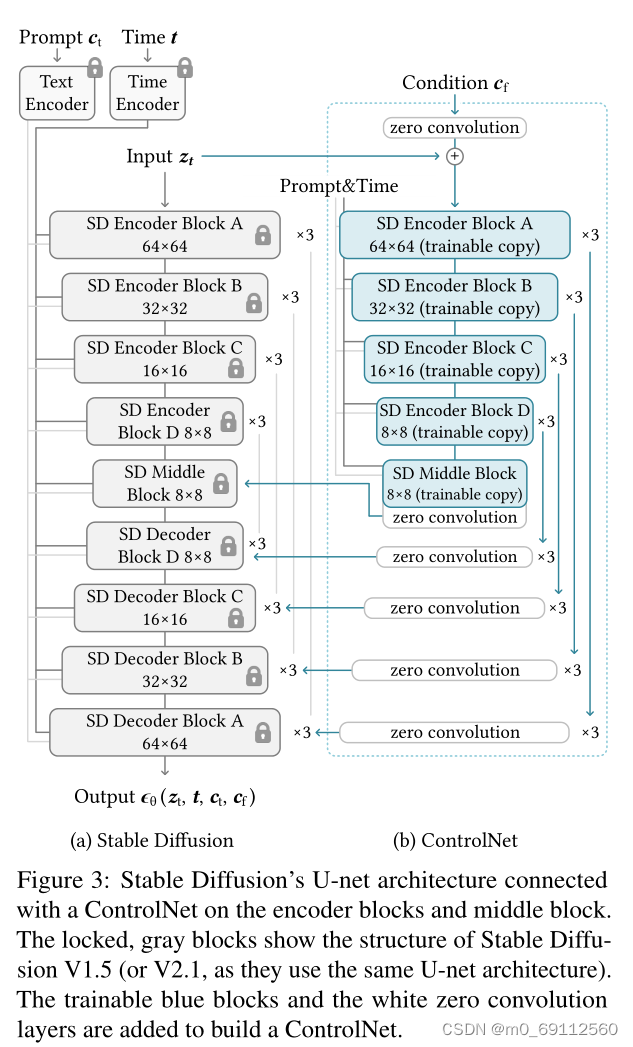
3.ControlNet的技术实现
技术上,ControlNet采用了一种特殊的神经网络架构,该架构能够在不破坏原有预训练模型的基础上,引入条件控制。具体来说,ControlNet通过锁定(冻结)原始神经网络块的参数,并创建一个可训练的副本来实现这一点。这个可训练副本接收条件向量作为输入,并通过零卷积层与原始模型相连。零卷积层的权重和偏置初始化为零,这确保了在训练初期不会引入噪声,从而保护了预训练模型的核心特性。
在数学表达上,如果原始神经网络块用 F ( ⋅ ; Θ ) F(\cdot; \Theta) F(⋅;Θ)表示,其中 Θ \Theta Θ是其参数,那么ControlNet的输出 y c y_c yc可以通过以下公式计算:
y c = F ( x ; Θ ) + Z ( F ( x + Z ( c ; Θ z 1 ) ; Θ c ) ; Θ z 2 ) y_c = F(x; \Theta) + Z(F(x + Z(c; \Theta_{z1}); \Theta_c); \Theta_{z2}) yc=F(x;Θ)+Z(F(x+Z(c;Θz1);Θc);Θz2)
这里, x x x是输入特征图, c c c是条件向量, Z ( ⋅ ; ⋅ ) Z(\cdot; \cdot) Z(⋅;⋅)是零卷积层, Θ z 1 \Theta_{z1} Θz1和 Θ z 2 \Theta_{z2} Θz2是零卷积层的参数, y y y是原始网络块的输出。
3.1 ControlNet的训练策略
ControlNet的训练过程涉及到一个精心设计的目标函数,该函数旨在最小化模型预测的噪声与实际噪声之间的差异。训练时,模型会学习如何根据输入的文本提示和条件图像来生成相应的图像。此外,通过随机移除一部分文本提示,ControlNet能够增强对条件图像语义内容的直接识别能力。
给定输入图像
z
0
z_0
z0,图像扩散算法逐步向图像添加噪声,产生一个噪声图像
z
t
z_t
zt,其中
t
t
t表示添加噪声的次数。给定包括时间步
t
t
t、文本提示
c
t
c_t
ct以及特定任务条件
c
f
c_f
cf的一组条件,图像扩散算法学习一个网络
ϵ
θ
\epsilon_\theta
ϵθ来预测添加到噪声图像
z
t
z_t
zt的噪声,使用以下目标函数:
其中 L L L是整个扩散模型的整体学习目标。这个学习目标直接用于使用ControlNet对扩散模型进行微调。在训练过程中,我们随机将50%的文本提示 c t c_t ct替换为空字符串,这增强了ControlNet直接从输入条件图像中识别语义的能力。由于零卷积在训练过程中不添加噪声,模型应始终能够预测高质量的图像。
L = E z 0 , t , c t , c f , ϵ ∼ N ( 0 , 1 ) [ ∥ ϵ − ϵ θ ( z t , t , c t , c f ) ∥ 2 2 ] L = \mathbb{E}_{z_0,t,c_t,c_f,\epsilon \sim \mathcal{N} (0,1)} \left[ \left\| \epsilon - \epsilon_\theta(z_t, t, c_t, c_f) \right\|^2_2 \right] L=Ez0,t,ct,cf,ϵ∼N(0,1)[∥ϵ−ϵθ(zt,t,ct,cf)∥22]
3.2 ControlNet的推理与应用
在推理阶段,ControlNet提供了灵活的方式来控制条件图像对去噪扩散过程的影响。例如,通过调整分类器自由引导(CFG)的权重,可以在保持图像质量的同时,平衡无条件输出和有条件输出之间的影响。CFG的公式如下:
ϵ prd = ϵ uc + β cfg ( ϵ c − ϵ uc ) \epsilon_{\text{prd}} = \epsilon_{\text{uc}} + \beta_{\text{cfg}} (\epsilon_c - \epsilon_{\text{uc}}) ϵprd=ϵuc+βcfg(ϵc−ϵuc)
其中, ϵ prd \epsilon_{\text{prd}} ϵprd是模型的最终输出, ϵ uc \epsilon_{\text{uc}} ϵuc是无条件输出, ϵ c \epsilon_c ϵc是有条件输出, β cfg \beta_{\text{cfg}} βcfg是用户指定的权重。
此外,ControlNet支持将多个条件图像组合应用到图像生成中,这一过程无需额外的加权或插值,极大地提升了模型的应用范围和灵活性。为了实现这一点,ControlNet允许直接将多个条件的影响相加,如:
Output = Stable Diffusion + ∑ i ControlNet i \text{Output} = \text{Stable Diffusion} + \sum_i \text{ControlNet}_i Output=Stable Diffusion+i∑ControlNeti
这里, Stable Diffusion \text{Stable Diffusion} Stable Diffusion是基础的图像扩散模型,而 ControlNet i \text{ControlNet}_i ControlNeti是与第 i i i个条件相关的ControlNet的输出。
4.源码解析
调用层
def process(input_image, prompt, a_prompt, n_prompt, num_samples, image_resolution, ddim_steps, guess_mode, strength, scale, seed, eta, low_threshold, high_threshold):
with torch.no_grad():
img = resize_image(HWC3(input_image), image_resolution)
H, W, C = img.shape
detected_map = apply_canny(img, low_threshold, high_threshold)
detected_map = HWC3(detected_map)
control = torch.from_numpy(detected_map.copy()).float().cuda() / 255.0
control = torch.stack([control for _ in range(num_samples)], dim=0)
control = einops.rearrange(control, 'b h w c -> b c h w').clone()
if seed == -1:
seed = random.randint(0, 65535)
seed_everything(seed)
if config.save_memory:
model.low_vram_shift(is_diffusing=False)
cond = {"c_concat": [control], "c_crossattn": [model.get_learned_conditioning([prompt + ', ' + a_prompt] * num_samples)]}
un_cond = {"c_concat": None if guess_mode else [control], "c_crossattn": [model.get_learned_conditioning([n_prompt] * num_samples)]}
shape = (4, H // 8, W // 8)
if config.save_memory:
model.low_vram_shift(is_diffusing=True)
model.control_scales = [strength * (0.825 ** float(12 - i)) for i in range(13)] if guess_mode else ([strength] * 13) # Magic number. IDK why. Perhaps because 0.825**12<0.01 but 0.826**12>0.01
samples, intermediates = ddim_sampler.sample(ddim_steps, num_samples,
shape, cond, verbose=False, eta=eta,
unconditional_guidance_scale=scale,
unconditional_conditioning=un_cond)
if config.save_memory:
model.low_vram_shift(is_diffusing=False)
x_samples = model.decode_first_stage(samples)
x_samples = (einops.rearrange(x_samples, 'b c h w -> b h w c') * 127.5 + 127.5).cpu().numpy().clip(0, 255).astype(np.uint8)
results = [x_samples[i] for i in range(num_samples)]
return [255 - detected_map] + results
参数解释
input_image: 输入图像,它将被用于生成条件图像。prompt: 文本提示,用于引导图像生成过程。a_prompt: 附加文本提示,可能用于添加更多上下文信息。n_prompt: 另一个文本提示,可能用于指定不希望在生成的图像中出现的元素。num_samples: 要生成的图像样本数量。image_resolution: 输出图像的分辨率。ddim_steps: 用于生成图像的去噪步骤数。guess_mode: 一个布尔值,指示是否启用猜测模式。strength: 控制条件对生成过程的影响强度。scale: 用于调整无条件引导的比例。seed: 随机种子,用于确保结果的可重复性。eta: 在去噪过程中使用的超参数,控制扩散和去噪之间的平衡。low_threshold和high_threshold: Canny边缘检测中的阈值参数。
函数逻辑
-
图像预处理:使用
resize_image函数调整输入图像的分辨率,并将其转换为适合模型处理的格式HWC3。 -
边缘检测:应用Canny算法来检测输入图像的边缘,并将结果转换为灰度图像
detected_map。 -
条件向量创建:将检测到的边缘图转换为张量
control,并将其归一化到[0,1]范围。然后,根据要生成的样本数量,沿批次维度重复这个张量。 -
随机种子设置:如果用户提供了随机种子(
seed),则使用它;否则,生成一个随机的种子以确保结果的随机性。 -
条件字典构建:构建两个条件字典
cond和un_cond,分别包含有条件和无条件的引导信息。这些将用于指导图像生成过程。 -
模型状态调整:如果配置要求节省内存,模型将切换到低VRAM模式。
-
图像生成:使用
ddim_sampler.sample函数进行图像生成,该函数根据提供的文本提示和条件向量生成图像样本。 -
后处理:生成的图像样本通过模型的第一阶段解码器进行解码,然后转换为8位无符号整数格式,并确保像素值在0到255的范围内。
-
结果组合:将原始的检测到的边缘图和生成的图像样本组合成结果列表。
这段代码体现了ControlNet的核心理念,即通过额外的条件图像(在这里是边缘检测图)来控制图像生成过程。通过将边缘检测图作为条件输入,并结合文本提示,模型能够生成具有所需空间组成的图像。此外,通过调整strength参数,可以控制条件图像对生成过程的影响程度,这与ControlNet中通过调整条件控制的强度来影响图像生成的概念相符。
训练过程
def forward(self, x, hint, timesteps, context, **kwargs):
'''
x: 加了噪声的latent z
'''
# 把时间t编码为vector
t_emb = timestep_embedding(timesteps, self.model_channels, repeat_only=False)
emb = self.time_embed(t_emb) # linear->relu->linear emb.shape=(B, time_embed_dim)
# 只会对 hint 进行操作,因为这里的input_hint_block里面的类型不是TimestepBlock和SpatialTransformer
# 那相当于这里只对 hint 进行conv->silu->conv->silu->...->conv->silu->zero_conv
guided_hint = self.input_hint_block(hint, emb, context)
outs = []
h = x.type(self.dtype) # 将 x 的数据类型转换为 self.dtype。
for module, zero_conv in zip(self.input_blocks, self.zero_convs):
if guided_hint is not None:
h = module(h, emb, context) # conv_nd(h)
h += guided_hint # x + conv_nd(hint)
guided_hint = None
else:
h = module(h, emb, context)
outs.append(zero_conv(h, emb, context)) # 对加入hint后的h再次conv_nd
h = self.middle_block(h, emb, context)
outs.append(self.middle_block_out(h, emb, context)) # make_zero_conv
return outs # ControlNet的输出,即zero_conv->ldm->zero_conv->outs
参数解释
x: 输入数据,通常是经过添加噪声处理的潜在表示(latent representation),在图像生成任务中,这可能代表一个图像的噪声版本。hint: 一个额外的提示或条件,用于指导图像生成过程,可能包括边缘图、深度图等。timesteps: 时间步长,用于在扩散过程中跟踪当前的噪声水平。context: 可能包含额外的上下文信息,用于辅助图像生成。**kwargs: 额外的关键字参数,用于传递其他可能需要的参数。
函数逻辑
-
时间嵌入:使用
timestep_embedding函数将时间步长timesteps编码为一个时间向量t_emb,然后通过一个线性层和两次激活函数(通常是ReLU)处理,得到形状为(B, time_embed_dim)的嵌入向量emb。 -
提示引导:
hint通过input_hint_block进行处理,该块可能包含一系列卷积和激活函数,同时考虑到时间嵌入emb和上下文context。处理后的hint被称为guided_hint。 -
输入块处理:对于模型中的每个输入块
module,执行以下操作:- 如果
guided_hint不为None,则将h(当前的处理状态)和emb传入module,然后将结果与guided_hint相加。这允许hint指导图像生成过程。 - 无论
guided_hint是否为None,都将处理后的h再次通过module。
- 如果
-
零卷积:在每个输入块后,使用
zero_convs中的零卷积层对h进行处理,并将结果存储在outs列表中。零卷积是一种特殊的卷积操作,其权重初始化为零,用于在训练开始时不引入噪声。 -
中间块处理:
h通过middle_block进行处理,该块可能包含更复杂的操作,以进一步提炼图像表示。 -
输出零卷积:处理后的中间表示再次通过零卷积层,结果也添加到
outs列表中。 -
返回输出:
outs包含了模型生成的所有中间零卷积层的输出,这些输出可以用于后续的图像生成或其他处理步骤。
forward 函数是ControlNet架构的核心,它体现了ControlNet如何通过零卷积层和条件提示来控制图像生成过程。通过逐步处理输入的噪声图像 x 并引导其通过一系列模块,同时在关键步骤中引入条件提示,ControlNet能够生成符合特定条件的高质量图像。这种方法允许在保留预训练模型知识的同时,对生成过程进行精细控制,从而提高图像生成的精度和多样性。
5.结论
ControlNet的引入,不仅提升了图像生成的精度和灵活性,还为图像编辑和创作提供了新的可能性。这种方法的创新之处在于其能够保留预训练模型的知识,同时通过条件控制来适应各种下游任务。ControlNet的这些特性,无疑将为图像处理和计算机视觉领域带来新的突破,并在技术社区中引起广泛的关注和讨论。















 2222
2222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









