






一、研究背景
随着数字通信和人工智能生成内容(AIGC)的爆炸性发展,数据的隐私、安全和保护引起了重大关注。作为一种广泛研究的技术,隐写术旨在以不被发现的方式将消息如音频、图像和文本隐藏到载体图像中。在揭示过程中,只有具备预先定义的揭示操作的接收者才能从载体图像中重建秘密信息。隐写术有广泛的应用,例如版权保护、数字水印、电子商务、反视觉检测和云计算。
最近,基于扩散的生成模型的研究非常流行,具有许多独特的属性,如在零样本方式中执行许多任务的能力、对生成过程的强大控制、图像中的自然鲁棒性以及实现图像到图像的转换。扩散模型与图像隐写术的融合不仅仅是机械地结合它们,而是一种优雅且有指导意义的整合,它考虑了图像隐写术的真实关切。基于这些想法,本文提出了一个名为可控、鲁棒和安全图像隐写术(CRoSS)的新框架,旨在同时实现安全性、可控性和鲁棒性的增益。
二、Method
隐藏过程

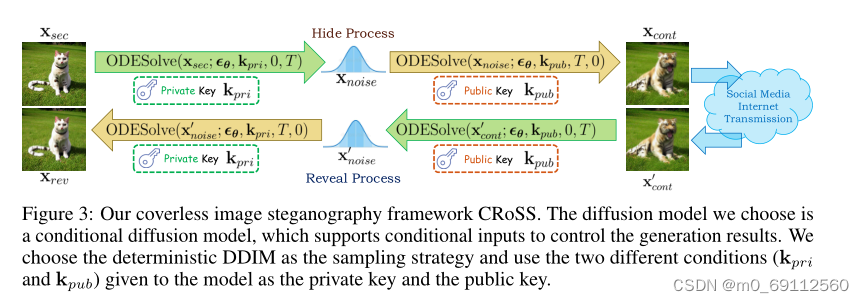
在CRoSS(Controllable, Robust and Secure Image Steganography)框架中,私钥 k pri k_{\text{pri}} kpri 在隐藏阶段用于指导图像生成的过程,具体步骤如下:
-
选择私钥:私钥 k pri k_{\text{pri}} kpri 是一个条件输入,它决定了秘密图像 x sec x_{\text{sec}} xsec 的内容和风格。私钥可以是文本提示、深度图、涂鸦或其他能够控制扩散模型生成过程的条件。
-
前向过程:在隐藏阶段的前向过程中,首先将秘密图像 x sec x_{\text{sec}} xsec 通过条件扩散模型的前向过程添加噪声,生成一系列逐步增加噪声的图像。这个过程是通过DDIM的前向公式来实现的:
x t = α t x t − 1 + 1 − α t ϵ , ϵ ∼ N ( 0 , I ) x_t = \sqrt{\alpha_t x_{t-1}} + \sqrt{1 - \alpha_t} \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) xt=αtxt−1+1−αtϵ,ϵ∼N(0,I)
其中 x t x_t xt 是第 t 步的噪声图像, ϵ \epsilon ϵ 是随机采样的高斯噪声, α t \alpha_t αt 是预定义的参数。 -
私钥指导:在前向过程的每一步中,私钥 k pri k_{\text{pri}} kpri 作为条件输入给条件扩散模型,确保即使在添加噪声的过程中,秘密图像的核心内容和特征仍然被编码和保留在噪声图像中。
-
生成中间噪声:通过前向过程,最终生成一个高度噪声化的图像表示 x T x_T xT,它是秘密图像的潜在表示,包含了秘密图像的关键信息,但对观察者来说是不可解读的。
-
后向过程:接下来,使用私钥 k pri k_{\text{pri}} kpri 作为条件,通过条件扩散模型的后向过程从噪声表示 x T x_T xT 开始逐步去除噪声,恢复出载体图像 x cont x_{\text{cont}} xcont。后向过程使用确定性DDIM公式:
x 0 = ODESolve ( x T ; ϵ θ , k pri , T , 0 ) x_0 = \text{ODESolve}(x_T; \epsilon_{\theta}, k_{\text{pri}}, T, 0) x0=ODESolve(xT;ϵθ,kpri,T,0)
这里 ϵ θ \epsilon_{\theta} ϵθ 是基于预训练的噪声估计器, T T T 是时间步长, O D E S o l v e ODESolve ODESolve 表示使用常微分方程(ODE)求解器进行求解。 -
生成载体图像:通过后向过程,最终生成的载体图像 x cont x_{\text{cont}} xcont 在视觉上与普通图像无异,但编码了秘密图像的信息。私钥 k pri k_{\text{pri}} kpri 在此过程中起到了关键作用,确保了秘密信息的安全性和可控性。
所以说,在CRoSS框架的隐藏阶段,私钥 k pri k_{\text{pri}} kpri 通过条件扩散模型的前向和后向过程,指导了从秘密图像到噪声图像再到载体图像的转换,确保了秘密信息的安全隐藏和高质量视觉结果。
解密过程

在CRoSS框架中的揭示过程(Reveal Process),是指接收者从可能经过网络传输并遭受降级处理的载体图像中恢复出原始的秘密图像的过程。这个过程需要使用与隐藏阶段相同的条件扩散模型,并且依赖于私钥和公钥的正确使用。以下是揭示过程的详细步骤:
-
接收载体图像:接收者首先获得已经通过互联网传输并可能遭受降级的载体图像 x cont ′ x'_{\text{cont}} xcont′。
-
使用公钥进行前向过程:接收者使用公钥 k pub k_{\text{pub}} kpub 作为条件输入,将受损的载体图像 x cont ′ x'_{\text{cont}} xcont′ 输入到条件扩散模型的前向过程中。这个前向过程与隐藏阶段的前向过程类似,通过逐步添加噪声将图像转换为一系列噪声图像,最终得到一个噪声表示 x T ′ x'_T xT′。
-
公钥的作用:公钥 k pub k_{\text{pub}} kpub 在此阶段用于确保即使接收者不知道私钥 k pri k_{\text{pri}} kpri,也能开始从载体图像中提取信息的过程。公钥帮助模型理解载体图像的某些方面,为后续的逆过程做准备。
-
私钥用于后向过程:一旦获得噪声表示 x T ′ x'_T xT′,接收者使用私钥 k pri k_{\text{pri}} kpri 作为条件输入,开始条件扩散模型的后向过程。这个过程与DDIM的后向过程相似,目的是逐步去除噪声,恢复出秘密图像:
x rev = ODESolve ( x T ′ ; ϵ θ , k pri , T , 0 ) x_{\text{rev}} = \text{ODESolve}(x'_T; \epsilon_{\theta}, k_{\text{pri}}, T, 0) xrev=ODESolve(xT′;ϵθ,kpri,T,0)
其中 ϵ θ \epsilon_{\theta} ϵθ 是预训练的噪声估计器, T T T 是时间步长, O D E S o l v e ODESolve ODESolve 表示使用ODE求解器进行求解。 -
恢复秘密图像:通过后向过程,最终从噪声表示 x T ′ x'_T xT′ 恢复出秘密图像 x rev x_{\text{rev}} xrev。如果私钥和公钥使用正确,且模型能够正确执行逆过程,则恢复出的秘密图像 x rev x_{\text{rev}} xrev 应该与原始的秘密图像 x sec x_{\text{sec}} xsec 语义一致。
-
验证和安全性:揭示过程的成功依赖于私钥的准确性,因为只有正确的私钥才能正确指导后向过程,从而恢复出可识别的秘密图像。此外,即使载体图像在传输过程中遭受了降级,由于扩散模型的鲁棒性,CRoSS框架仍能够恢复出高质量的秘密图像。
揭示过程是CRoSS框架中的逆过程,它允许接收者使用公钥和私钥从受损的载体图像中恢复出秘密图像,同时确保了过程的安全性和鲁棒性。
三、实验

实验目的与设置:
实验旨在全面评估CRoSS框架在安全性、可控性和鲁棒性上的表现。为此,研究者选用了Stable Diffusion模型和确定性DDIM算法,通过一系列精心设计的实验流程,对CRoSS进行测试。实验在GeForce RTX 3090 GPU上执行,避免了额外的训练或微调,以保持模型的通用性和实用性。
数据集构建:
研究者创建了一个名为Stego260的基准数据集,包含260张高质量图像,分为人类、动物和一般对象三个类别。这些图像通过公开数据集和网络搜索获得,并为每张图像设计了两组文本提示(Prompt1和Prompt2),用于指导隐写过程。
安全性分析:
通过重新训练最新的隐写分析工具SID,研究者对CRoSS生成的载体图像进行了安全性测试。CRoSS在抵抗隐写分析攻击方面表现出色,其检测准确度随着泄露样本数量的增加而缓慢提高,表明其具有较低的被检测风险。
可控性验证:
实验中,CRoSS展示了其高度的可控性。通过使用不同的私钥和公钥,如文本提示、ControlNets和LoRAs,CRoSS能够根据用户的输入条件精确地生成和恢复图像。这一特性使得CRoSS在隐藏特定信息时具有很高的灵活性和准确性。
鲁棒性测试:
CRoSS在多种降级条件下的鲁棒性得到了充分的验证。无论是面对模拟的高斯噪声、JPEG压缩,还是现实世界的微信传输和手机拍摄等复杂情况,CRoSS均能恢复出高质量的秘密图像,证明了其在实际应用中的可靠性。
实验结论:
实验结果表明,CRoSS框架在图像隐写任务中提供了一种新的解决方案,它不仅在理论上具有创新性,而且在实际应用中也显示出了显著的优势。CRoSS的成功应用展示了扩散模型在图像隐写领域的潜力,为未来的研究和开发提供了新的方向。尽管CRoSS在像素级保真度和编辑能力上存在一定的局限性,但其在安全性、可控性和鲁棒性方面的卓越表现,使其成为了图像隐写技术领域的一个重要进展。
四、代码解析
class ODESolve:
def __init__(self, model, NUM_DDIM_STEPS=50):
# 初始化DDIMScheduler,用于控制扩散模型中的噪声添加和去除过程
scheduler = DDIMScheduler(...)
self.model = model
# 设置扩散步骤的数量,用于控制生成过程的精细程度
self.num_ddim_steps = NUM_DDIM_STEPS
# 获取模型的tokenizer,用于文本提示的处理
self.tokenizer = self.model.tokenizer
# 配置模型使用的时间步数量
self.model.scheduler.set_timesteps(self.num_ddim_steps)
# 初始化用于存储文本提示的变量
self.prompt = None
# 初始化用于存储上下文嵌入的变量
self.context = None
def prev_step(self, model_output, timestep, sample):
# 根据模型输出和当前时间步计算前一时间步的样本
prev_timestep = timestep - ... # 根据当前时间步计算前一时间步的索引
alpha_prod_t = ... # 当前时间步的alpha累积乘积
alpha_prod_t_prev = ... # 前一时间步的alpha累积乘积
beta_prod_t = 1 - alpha_prod_t # 当前时间步的beta乘积
# 根据模型输出和alpha、beta值计算前一时间步的预测样本
pred_original_sample = (sample - beta_prod_t ** 0.5 * model_output) / alpha_prod_t ** 0.5
# 计算前一时间步的样本方向
pred_sample_direction = (1 - alpha_prod_t_prev) ** 0.5 * model_output
# 结合预测的原始样本和样本方向得到前一时间步的样本
prev_sample = alpha_prod_t_prev ** 0.5 * pred_original_sample + pred_sample_direction
return prev_sample
@torch.no_grad()
def invert_i2n2i(self, prompt1, prompt2, image_start_latent, flip=False):
# 实现从图像到噪声表示再到图像的逆向过程
self.init_prompt(prompt1) # 初始化第一个提示
latent_i2n = self.ddim_loop(image_start_latent, is_forward=True) # 从图像到噪声表示
xT = latent_i2n[-1] # 获取最终的噪声表示
if flip: # 如果需要翻转图像
xT = torch.flip(xT, dims=[2]) # 沿宽度翻转
self.init_prompt(prompt2) # 初始化第二个提示
latent_n2i = self.ddim_loop(xT, is_forward=False) # 从噪声表示到图像
# 返回原始图像、原始潜在表示、逆向生成的图像和逆向生成的潜在表示
return self.latent2image(image_start_latent), image_start_latent, self.latent2image(latent_n2i[-1]), latent_n2i[-1]
逻辑解释
ODESolve 类实现了基于扩散模型的图像隐写术的核心逻辑,包括图像的隐藏和恢复过程。
-
__init__: 类的构造函数初始化了模型和扩散步骤的数量,并准备了用于文本提示和上下文的变量。 -
prev_step和next_step: 这两个函数用于在DDIM过程中计算给定时间步的前一步骤和后一步骤的样本。这是通过应用预定义的alpha和beta值来实现的,这些值控制了噪声的添加和去除。 -
get_noise_pred_single: 用于获取给定潜在表示、时间步和上下文的单步噪声预测。 -
get_noise_pred:结合无条件和条件噪声预测,并根据是否前向的标志执行相应的步骤更新。 -
latent2image: 将潜在表示解码成可视化图像,将模型的输出转换为可理解形式。 -
image2latent: 执行逆操作,将图像编码成潜在表示,这是逆向过程的起始步骤。 -
init_prompt: 初始化文本提示,并获取用于条件生成的文本嵌入。 -
ddim_loop: 执行DDIM循环,根据是前向还是后向过程,生成一系列潜在表示。 -
invert: 实现了从给定初始潜在表示开始的逆向生成过程,用于恢复隐藏的图像。 -
invert_i2n2i: 实现了从图像到噪声表示再到图像的完整逆向过程,包括可选的图像翻转,用于在揭示阶段恢复原始图像。
class ODESolve:
def __init__(self, model, NUM_DDIM_STEPS=50):
# 初始化扩散模型的调度器,用于控制噪声添加和去除的策略
scheduler = DDIMScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear",
clip_sample=False, set_alpha_to_one=False)
self.model = model
# 设置扩散步骤的数量,用于控制生成过程的详细程度
self.num_ddim_steps = NUM_DDIM_STEPS
# 获取与模型关联的tokenizer,用于处理文本提示
self.tokenizer = self.model.tokenizer
# 配置模型使用的扩散步骤数量
self.model.scheduler.set_timesteps(self.num_ddim_steps)
# 初始化用于存储文本提示的变量
self.prompt = None
# 初始化用于存储文本嵌入上下文的变量
self.context = None
def prev_step(self, model_output: Union[torch.FloatTensor, np.ndarray], timestep: int, sample: Union[torch.FloatTensor, np.ndarray]):
# 计算前一步骤的样本
prev_timestep = timestep - self.scheduler.config.num_train_timesteps // self.scheduler.num_inference_steps
# 计算当前时间步的alpha累积乘积
alpha_prod_t = self.scheduler.alphas_cumprod[timestep]
# 如果是第一个时间步,使用最终的alpha累积乘积
alpha_prod_t_prev = self.scheduler.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.scheduler.final_alpha_cumprod
# 计算当前时间步的beta值
beta_prod_t = 1 - alpha_prod_t
# 计算预测的原始样本
pred_original_sample = (sample - beta_prod_t ** 0.5 * model_output) / alpha_prod_t ** 0.5
# 计算前一时间步的样本方向
pred_sample_direction = (1 - alpha_prod_t_prev) ** 0.5 * model_output
# 计算并返回前一时间步的样本
prev_sample = alpha_prod_t_prev ** 0.5 * pred_original_sample + pred_sample_direction
return prev_sample
def next_step(self, model_output: Union[torch.FloatTensor, np.ndarray], timestep: int, sample: Union[torch.FloatTensor, np.ndarray]):
# 计算后一步骤的样本
timestep, next_timestep = min(timestep - self.scheduler.config.num_train_timesteps // self.scheduler.num_inference_steps, 999), timestep
# 如果是第一个时间步,使用最终的alpha累积乘积
alpha_prod_t = self.scheduler.alphas_cumprod[timestep] if timestep >= 0 else self.scheduler.final_alpha_cumprod
# 计算下一个时间步的alpha累积乘积
alpha_prod_t_next = self.scheduler.alphas_cumprod[next_timestep]
# 计算当前时间步的beta值
beta_prod_t = 1 - alpha_prod_t
# 计算下一个时间步的预测原始样本
next_original_sample = (sample - beta_prod_t ** 0.5 * model_output) / alpha_prod_t ** 0.5
# 计算下一个时间步的样本方向
next_sample_direction = (1 - alpha_prod_t_next) ** 0.5 * model_output
# 计算并返回下一个时间步的样本
next_sample = alpha_prod_t_next ** 0.5 * next_original_sample + next_sample_direction
return next_sample
def get_noise_pred_single(self, latents, t, context):
# 获取单步的噪声预测,不包括文本指导
noise_pred = self.model.unet(latents, t, context)["sample"]
return noise_pred
def get_noise_pred(self, latents, t, is_forward=True, context=None):
# 根据条件获取噪声预测,并执行前向或后向步骤
if context is None:
context = self.context
# 设置文本指导的强度
guidance_scale = GUIDANCE_SCALE
# 从上下文中分离出无条件和条件嵌入
uncond_embeddings, cond_embeddings = context.chunk(2)
# 获取无条件的噪声预测
noise_pred_uncond = self.model.unet(latents, t, uncond_embeddings)["sample"]
# 获取条件的噪声预测
noise_prediction_text = self.model.unet(latents, t, cond_embeddings)["sample"]
# 结合无条件和条件噪声预测
noise_pred = noise_pred_uncond + guidance_scale * (noise_prediction_text - noise_pred_uncond)
# 根据前向或后向标志执行相应的步骤
if is_forward:
latents = self.next_step(noise_pred, t, latents)
else:
latents = self.prev_step(noise_pred, t, latents)
return latents
@torch.no_grad()
def latent2image(self, latents, return_type='np'):
# 将潜在表示转换为图像
# 缩放潜在表示以匹配解码器的期望输入
latents = 1 / 0.18215 * latents.detach()
# 使用模型的VAE解码器将潜在表示解码为图像
image = self.model.vae.decode(latents)['sample']
# 如果需要返回NumPy数组格式的图像
if return_type == 'np':
# 将图像缩放到[0, 1]范围,并转换为NumPy数组
image = (image / 2 + 0.5).clamp(0, 1)
# 将图像从PyTorch张量转换为NumPy数组,并进行适当的维度置换
image = image.cpu().permute(0, 2, 3, 1).numpy()[0]
# 将图像数据类型转换为无符号8位整数
image = (image * 255).astype(np.uint8)
return image
@torch.no_grad()
def image2latent(self, image):
# 将图像转换为潜在表示
with torch.no_grad():
if type(image) is Image:
# 如果输入是PIL图像,首先转换为NumPy数组
image = np.array(image)
if type(image) is torch.Tensor and image.dim() == 4:
# 如果输入已经是PyTorch张量且维度正确,则直接使用
latents = image
else:
# 将图像数据类型转换为浮点数,并进行规范化处理
image = torch.from_numpy(image).float() / 127.5 - 1
# 调整图像的维度以匹配模型的输入要求,并将其移动到设备上
image = image.permute(2, 0, 1).unsqueeze(0).to(device)
# 使用模型的VAE编码器将图像编码为潜在表示
latents = self.model.vae.encode(image)['latent_dist'].mean
# 缩放潜在表示以匹配扩散模型的期望输入
latents = latents * 0.18215
return latents
@torch.no_grad()
def init_prompt(self, prompt: str):
# 初始化文本提示,并获取无条件和条件文本嵌入
uncond_input = self.model.tokenizer(
[""], padding="max_length", max_length=self.model.tokenizer.model_max_length,
return_tensors="pt"
)
# 获取无条件输入的嵌入
uncond_embeddings = self.model.text_encoder(uncond_input.input_ids.to(self.model.device))[0]
text_input = self.model.tokenizer(
[prompt],
padding="max_length",
max_length=self.model.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
# 获取条件输入的嵌入
text_embeddings = self.model.text_encoder(text_input.input_ids.to(self.model.device))[0]
# 合并无条件和条件嵌入,形成上下文向量
self.context = torch.cat([uncond_embeddings, text_embeddings])
# 保存当前的提示
self.prompt = prompt
@torch.no_grad()
def get_text_embeddings(self, prompt: str):
# 获取文本提示的嵌入表示
text_input = self.model.tokenizer(
[prompt],
padding="max_length",
max_length=self.model.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_embeddings = self.model.text_encoder(text_input.input_ids.to(self.model.device))[0]
return text_embeddings
@torch.no_grad()
def ddim_loop(self, latent, is_forward=True):
# 执行DDIM循环,用于生成或逆向生成图像
all_latent = [latent]
latent = latent.clone().detach()
# 根据前向或后向生成,迭代所有时间步
for i in tqdm(range(self.num_ddim_steps)):
if is_forward:
# 如果是前向生成,使用递减的时间步
t = self.model.scheduler.timesteps[len(self.model.scheduler.timesteps) - i - 1]
else:
# 如果是后向生成,使用递增的时间步
t = self.model.scheduler.timesteps[i]
# 根据当前的时间步和上下文获取噪声预测,并更新潜在表示
latent = self.get_noise_pred(latent, t, is_forward, self.context)
# 保存当前步骤的潜在表示
all_latent.append(latent)
# 返回所有步骤的潜在表示
return all_latent
@property
def scheduler(self):
# 返回模型的调度器
return self.model.scheduler
def save_inter(self, latent, img_name):
# 保存中间生成的图像
image = self.latent2image(latent)
cv2.imwrite(img_name, cv2.cvtColor(image, cv2.COLOR_RGB2BGR))
def invert(self, prompt, start_latent, is_forward):
# 实现从给定的潜在表示开始的逆向生成过程
self.init_prompt(prompt) # 初始化文本提示
latents = self.ddim_loop(start_latent, is_forward=is_forward) # 执行DDIM循环
return latents[-1] # 返回最终的潜在表示
def invert_i2n2i(self, prompt1, prompt2, image_start_latent, flip=False):
# 实现从图像到噪声表示再到图像的完整逆向过程
self.init_prompt(prompt1) # 初始化第一个文本提示
latent_i2n = self.ddim_loop(image_start_latent, is_forward=True) # 从图像到噪声表示
xT = latent_i2n[-1] # 获取最终的噪声表示
if flip: # 如果需要翻转图像
xT = torch.flip(xT, dims=[2]) # 沿宽度翻转
self.init_prompt(prompt2) # 初始化第二个文本提示
latent_n2i = self.ddim_loop(xT, is_forward=False) # 从噪声表示到图像
# 返回原始图像、原始潜在表示、逆向生成的图像和逆向生成的潜在表示
return self.latent2image(image_start_latent), image_start_latent, self.latent2image(latent_n2i[-1]), latent_n2i[-1]















 2036
2036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









